# Tutoriel Distant Viewing 3 : Images animées
[[**diapositives**](https://raw.githubusercontent.com/taylor-arnold/atelier/refs/heads/main/2026_dv/slides/tutoriel03.pdf)]
[[**chapitre**](https://direct.mit.edu/books/oa-monograph/chapter-pdf/2163344/c003200_9780262375160.pdf)]
[[**site web**](https://www.distantviewing.org)]
Ce notebook explore la théorie et les méthodes présentées dans le livre
*Distant Viewing* (MIT Press, 2023) pour étudier le style visuel de deux
sitcoms de l'ère des grands réseaux télévisés américains. Concrètement,
nous allons examiner chaque épisode diffusé des séries *Bewitched*
(1964-1972) et *I Dream of Jeannie* (1965-1970). Dans le notebook, nous
détaillerons d'abord la méthodologie à partir d'un court extrait vidéo
de 45 secondes, en avançant pas à pas. Puis, faute de temps, et compte
tenu de la taille des fichiers et des contraintes de droits d'auteur,
nous chargerons un jeu d'annotations précalculées équivalent à celles
de l'extrait, et nous utiliserons cet ensemble plus large pour
l'analyse. Voici les objectifs d'apprentissage du tutoriel :
1. Expliquer comment les vidéos numériques peuvent être comprises
comme une séquence d'images.
2. Appliquer les fonctions de vision par ordinateur du distant viewing
toolkit à un court fichier vidéo.
3. Calculer les ruptures de plan à l'aide d'un algorithme de vision
par ordinateur de pointe, et relier ces ruptures à des questions de
recherche en *media studies*.
4. Classer l'identité estimée des personnages à l'aide d'algorithmes
de vision par ordinateur et de plongements de visages.
5. Montrer comment aborder des questions de recherche en sciences
humaines à l'aide d'algorithmes de vision par ordinateur appliqués
à un corpus de séries télévisées.
Ce notebook ne requiert aucune connaissance préalable de Python ni de
la vision par ordinateur. Cependant, il avance assez rapidement sur les
étapes préliminaires de manipulation des images numériques et
n'explique que les aspects les plus importants du code Python à chaque
étape. Pour une introduction plus approfondie à la façon dont les
ordinateurs « voient » les images et à Python, nous recommandons de
suivre d'abord le notebook *Distant Viewing Tutorial: Movie Posters
and Color Analysis*, accessible
[ici](https://colab.research.google.com/drive/1qQKQw8qHsTG7mK7Rz-z8nBfl98QBMWGf?usp=sharing).
## 3.1 Configuration
Pour commencer, nous devons installer quelques composants Python
supplémentaires, télécharger les jeux de données, et indiquer à Python
toutes les fonctions dont nous aurons besoin par la suite. Pour
démarrer, nous utiliserons le code ci-dessous pour installer le module
**dvt** (le distant viewing toolkit), qui contient plusieurs fonctions
utiles spécialement conçues pour appliquer des algorithmes de vision
par ordinateur à des collections de données en humanités. Le point
d'exclamation au début de la ligne de code indique au notebook que nous
voulons exécuter directement un outil en ligne de commande en dehors
de Python. Ici, nous utilisons **pip** pour installer des
fonctionnalités supplémentaires pour Python. Pour exécuter le code,
passez votre souris sur l'arrière-plan du code. Un bouton de lecture
triangulaire apparaîtra à gauche du bloc de code. Cliquez sur le bouton
et attendez la fin de l'exécution, ce qui peut prendre une minute ou
deux, car Colab met toujours un peu de temps à se mettre en place lors
de l'exécution du premier bloc de code.
```{python}
!pip install -q dvt
!pip install -q insightface
!pip install -q onnxruntime
```
Ensuite, le code ci-dessous télécharge les métadonnées et les fichiers
vidéo que nous utiliserons dans ce notebook. Il s'appuie sur le
programme **wget** pour télécharger les fichiers depuis le site distant
viewing, suivi de la commande **tar** pour décompresser le répertoire
contenant les portraits de personnages. Nous explorerons le contenu de
chacun de ces éléments au fur et à mesure dans les sections suivantes.
La dernière ligne utilise **mkdir** pour créer un répertoire vide qui
sera nécessaire dans la dernière section du notebook pour exécuter les
modèles d'apprentissage automatique sur la collection. Comme ci-dessus,
passez la souris sur le code puis cliquez sur le bouton de lecture à
gauche du bloc. Toutes les lignes seront exécutées les unes après les
autres. Une petite flèche verte indique la ligne en cours d'exécution
à tout moment, ce qui nous aide à comprendre quelles étapes prennent
le plus de temps.
```{python}
#| eval: false
!mkdir -p data
!mkdir -p cache
!mkdir -p /root/.cache/torch/hub/checkpoints/
!wget -q -nc -P data/ "https://distantviewing.org/atelier/ttl_sitcom_characters.csv"
!wget -q -nc -P data/ "https://distantviewing.org/atelier/ttl_sitcom_metadata.csv"
!wget -q -nc -P data/ "https://distantviewing.org/atelier/ttl_sitcom_shots.csv"
!wget -q -nc "https://distantviewing.org/atelier/faces.tar"
!wget -q -nc "https://distantviewing.org/atelier/bewitched_sample.mp4"
!wget -q -nc "https://distantviewing.org/atelier/funs.py"
!tar -xf faces.tar --warning=no-unknown-keyword
```
Dans la dernière partie de la configuration, nous allons exécuter du
code en Python (les lignes ci-dessous ne commencent pas par un point
d'exclamation). Ce code utilise la commande **import** pour indiquer à
Python quelles bibliothèques et fonctions nous allons utiliser dans le
notebook. Plus précisément, il s'agit de **os** pour interagir avec le
système de fichiers, **numpy** pour travailler avec de grands tableaux
de nombres, **polars** pour les jeux de données tabulaires,
**matplotlib.pyplot** pour la visualisation de base des images,
**plotnine** pour la visualisation de données, **insightface** pour la
détection et la reconnaissance de visages, **PIL** (Pillow) pour
charger les fichiers image, et le module **dvt** décrit ci-dessus.
```{python}
import matplotlib.pyplot as plt
import matplotlib.patches as patches
import polars as pl
import numpy as np
import cv2
import os
import dvt
import insightface
from insightface.app import FaceAnalysis
from PIL import Image
from polars import col as c
from funs import *
from plotnine import *
theme_set(theme_minimal())
```
Dans Google Colab, votre environnement de travail se réinitialise à
chaque fois que vous rouvrez un notebook. Toutes les étapes ci-dessus
doivent donc être ré-exécutées à chaque démarrage du notebook. Si vous
exécutiez ce code sur votre propre machine, l'installation du paquet
**dvt** et le téléchargement des données ne devraient être faits
qu'une seule fois. Le chargement des modules dans le dernier bloc de
code, en revanche, doit toujours être exécuté à chaque redémarrage de
Python.
## 3.2 Jeu de données des sitcoms de l'ère des réseaux
Avant de regarder les étapes computationnelles nécessaires pour
travailler avec des images animées, il est utile de comprendre les
questions de recherche en sciences humaines qui motivent ce travail.
Ici, nous nous intéressons à deux sitcoms américains populaires des
années 1960 et du début des années 1970 : *Bewitched* (1964-1972) et
*I Dream of Jeannie* (1965-1970). Voici les métadonnées de chacun des
épisodes de l'ensemble des deux séries :
```{python}
meta = pl.read_csv("data/ttl_sitcom_metadata.csv")
meta
```
Ces deux séries sont souvent comparées et opposées, *I Dream of
Jeannie* étant vu comme une tentative de NBC pour reproduire le succès
de *Bewitched* sur ABC, qui avait débuté une saison plus tôt. Bien
qu'on ait beaucoup écrit sur la portée culturelle de ces deux séries,
la recherche n'avait pas vraiment pris au sérieux leur style visuel.
Nous nous intéressons à la façon dont le tournage et le montage des
deux séries éclairent des questions comme : qui est ou qui sont les
personnages principaux ? Dans quelle mesure le style visuel
contribue-t-il aux relations entre les personnages ? Et comment ces
aspects évoluent-ils dans le temps ? Cette dernière question est
particulièrement intéressante parce que les deux séries ont débuté en
noir et blanc avant de passer à la couleur pour la majorité des
saisons suivantes.
## 3.3 Fichier vidéo d'exemple
Maintenant que nous avons quelques idées des grandes questions qui
nous intéressent, regardons un court extrait de l'une des séries pour
comprendre les étapes computationnelles nécessaires pour travailler
avec des images animées. Lorsqu'on mène des analyses computationnelles
sur des matériaux visuels et audiovisuels, il est important de revenir
fréquemment à des exemples précis pour s'assurer que notre analyse à
grande échelle reste connectée à l'expérience humaine du visionnage.
Dans ce notebook, nous allons commencer par parcourir lentement le
processus de création d'annotations qui résument un court extrait de
45 secondes tiré du premier épisode de la troisième saison de
*Bewitched*.
Nous vous suggérons de regarder l'extrait deux ou trois fois. Essayez
de prêter attention (et peut-être même de noter) au nombre de plans
dans l'extrait et à leur cadrage. Dans les sections suivantes, nous
utiliserons des algorithmes de vision par ordinateur pour essayer de
capturer ces traits sous forme d'annotations structurées.
## 3.4 Travailler avec les images d'une vidéo
Les formats vidéo comme **mp4**, **avi** ou **ogg** stockent
habituellement les images animées dans un format complexe, très
optimisé pour réduire la taille des fichiers et le temps de
décompression. Lorsqu'on travaille avec des images animées en Python,
on décompresse en général ces fichiers pour les transformer en une
suite d'images individuelles stockées comme des tableaux de pixels —
une par image de la vidéo d'entrée. Le distant viewing toolkit
(**dvt**) contient plusieurs fonctions pour travailler efficacement
avec des fichiers vidéo en Python. Dans cette section, nous allons
voir comment elles fonctionnent.
D'abord, on peut utiliser la fonction `video_info` pour accéder aux
métadonnées d'un fichier vidéo. Ici, nous chargeons les métadonnées de
notre extrait, qui affichent le nombre de images, la hauteur et la
largeur de chaque image en pixels, et la fréquence de lecture en
images par seconde (`IPS` ou `FPS` en anglais).
```{python}
info = dvt.video_info('bewitched_sample.mp4')
info
```
Comme on le voit dans les métadonnées, même ce court extrait contient
1319 images individuelles. Sur un épisode complet de série télévisée,
sans parler d'un long métrage, charger toutes les images d'une vidéo
en une seule fois en Python devient vite difficile. La taille des
images, en particulier en haute définition, est tout simplement trop
importante pour qu'elles tiennent toutes en même temps dans la mémoire
de l'ordinateur.
Le distant viewing toolkit (**dvt**) propose une approche alternative
avec la fonction `yield_video`. Elle permet d'écrire une boucle qui
charge chaque image de la vidéo une par une. À chaque appel, la
fonction `yield` renvoie la image suivante sous forme de tableau de
pixels, un entier décrivant le numéro de la image depuis le début de
la vidéo, et un code temporel donnant le nombre de secondes écoulées.
Le code ci-dessous montre un exemple d'utilisation de `yield_video`.
On parcourt chaque image. Pour chacune, on stocke le numéro de image,
le code temporel, et la valeur moyenne des pixels (une mesure de la
luminosité de la image). Puis on transforme l'ensemble en une table
de données avec une ligne par image de la vidéo.
```{python}
output = {'frame': [], 'time': [], 'brightness': []}
for img, frame, msec in dvt.yield_video("bewitched_sample.mp4"):
output['frame'].append(frame)
output['time'].append(msec)
output['brightness'].append(np.mean(img))
output = pl.DataFrame(output)
output
```
La luminosité est l'une des annotations les plus simples qu'on puisse
utiliser pour résumer une image. Mais même cette mesure élémentaire
permet déjà d'avoir une représentation grossière de notre extrait.
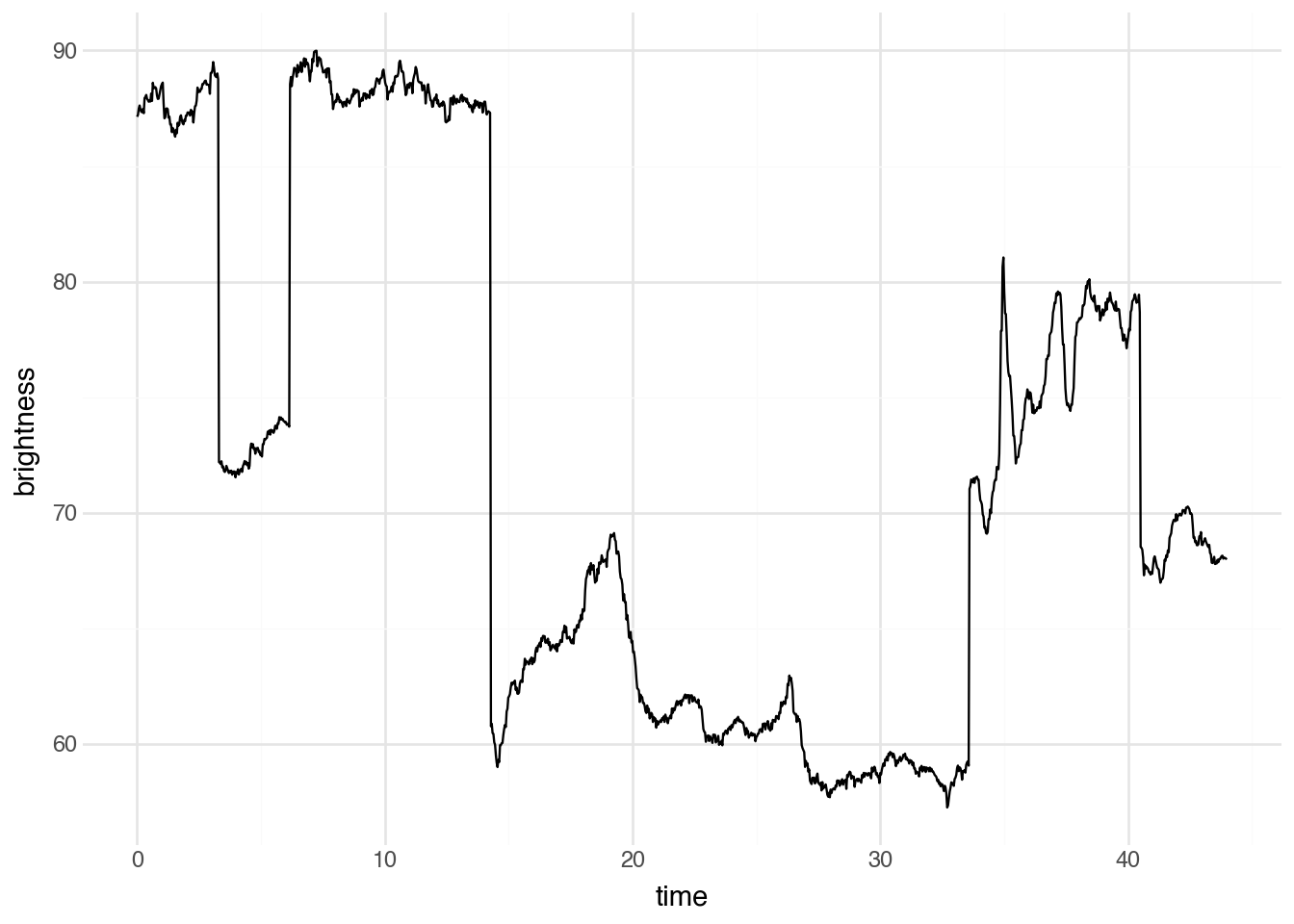
Pour le voir, traçons la luminosité de la image au cours du temps.
```{python}
(
output
.pipe(ggplot, aes("time", "brightness"))
+ geom_line()
)
```
En regardant la luminosité, et en particulier les grands sauts de
valeurs, parvenez-vous à identifier les ruptures de plan que vous
aviez repérées en regardant la vidéo ? Il y a une montée régulière de
la luminosité entre 15 et 20 secondes environ. À quoi cela
correspond-il dans la vidéo ?
## 3.5 Détection des ruptures de plan
L'une des premières tâches qu'on cherche souvent à effectuer sur un
fichier vidéo est d'identifier les coupures entre les plans. Ce
processus s'appelle la *détection des ruptures de plan* (shot boundary
detection). Comme on l'a vu sur le graphique de luminosité ci-dessus,
des heuristiques simples permettent déjà d'identifier
approximativement de nombreux types de ruptures. Pour obtenir des
prédictions plus précises — qui ne confondent pas un mouvement rapide
avec une rupture de plan et qui ne ratent pas les transitions plus
subtiles comme les fondus enchaînés — il faut faire appel à un
algorithme plus complexe. Le distant viewing toolkit (**dvt**) inclut
un algorithme de détection de ruptures de plan fondé sur les réseaux
de neurones, qui fonctionne bien sur de nombreux genres et types de
sources.
Pour exécuter l'algorithme intégré, nous créons d'abord un annotateur
avec la fonction `AnnoShotBreaks`. Puis nous le faisons tourner sur le
fichier vidéo. C'est le seul annotateur du toolkit qui travaille
directement sur un fichier vidéo plutôt que sur des images ou des
images individuelles. Le code Python affichera sa progression dans le
fichier au fur et à mesure, et renverra un dictionnaire contenant les
ruptures prédites.
```{python}
anno_breaks = dvt.AnnoShotBreaks()
out_breaks = anno_breaks.run("bewitched_sample.mp4")
```
Nous allons convertir la sortie de la détection en jeu de données
tabulaire, et ajouter l'heure de début et l'heure de fin à l'aide des
métadonnées récupérées avec `video_info`. Voici ce que l'algorithme a
trouvé pour cet extrait :
```{python}
shot = (
pl.DataFrame(out_breaks['scenes'])
.with_columns(
mid=((c.start + c.end) // 2),
start_t=(c.start / info['fps']),
end_t=(c.end / info['fps']),
)
)
shot
```
Prenez quelques minutes pour vérifier que ces ruptures correspondent
bien à celles que vous aviez repérées en regardant la vidéo. Vous
pouvez même revoir la vidéo (en mettant en pause à chaque coupure) et
constater qu'elle coïncide avec les ruptures identifiées
automatiquement.
Dans la section suivante, nous nous intéresserons à la détection et à
l'identification de visages. C'est une tâche courante lorsqu'on
travaille avec des images animées, mais qui finalement s'applique sur
des images individuelles. Pour simplifier le travail au début, nous
allons utiliser le code suivant pour construire un jeu de données
contenant une image par plan détecté dans l'extrait. Plus précisément,
nous prenons l'image centrale de chaque plan, telle que repérée dans
la table `shot` ci-dessus.
```{python}
img_list = []
for img, frame, msec in dvt.yield_video("bewitched_sample.mp4"):
if frame in shot['mid'].to_list():
img_list.append(img)
```
Pour avoir une idée de ce à quoi elles ressemblent, on peut combiner
ces images et les convertir en vignettes afin de voir les six plans de
notre extrait.
```{python}
img_comb = np.hstack(img_list)
img_comb = cv2.resize(img_comb, (img_comb.shape[1] // 5, img_comb.shape[0] // 5))
fig, ax = plt.subplots(1, 1, figsize=(12, 12))
ax.imshow(img_comb)
ax.axis("off")
plt.tight_layout()
plt.show()
```
Nous utiliserons les versions complètes de ces six images dans la
section suivante pour identifier la position, la taille et l'identité
des personnages dans chaque plan.
## 3.6 Détection et reconnaissance de visages
Localiser et identifier les visages présents dans une image donnée
d'une vidéo est une manière courante de comprendre la structure
narrative et le style visuel d'une source. Dans cette section, nous
verrons comment travailler avec les visages à l'aide de la
bibliothèque **InsightFace**, appliquée aux six images de l'extrait
extraites dans la section précédente. Après avoir vu comment procéder
sur un ensemble statique d'images, nous verrons dans la section
suivante comment assembler le tout pour qu'il puisse passer à
l'échelle sur des fichiers vidéo plus longs.
Pour commencer, on initialise un objet `FaceAnalysis` d'InsightFace en
précisant le pack de modèles `buffalo_l`. Au premier lancement, la
fonction téléchargera automatiquement les fichiers de modèles
nécessaires et les enregistrera localement.
```{python}
face_app = FaceAnalysis(name="buffalo_l", providers=["CPUExecutionProvider"])
face_app.prepare(ctx_id=0, det_size=(640, 640))
```
Pour détecter les visages, on convertit l'image du format RGB au
format BGR (celui qu'attend InsightFace) et on la passe à la méthode
`get` de l'objet `face_app`. Lançons la détection sur la troisième
image (en se rappelant que Python commence à compter à zéro : la
troisième image est donc à la position 2).
```{python}
#| warning: false
#| error: false
image_bgr = img_list[2][:, :, ::-1]
faces = face_app.get(image_bgr)
```
On dessine ensuite les boîtes englobantes détectées sur l'image à
l'aide de matplotlib. La boîte de chaque visage détecté est stockée
dans l'attribut `bbox` de l'objet renvoyé. Ici, on voit que
l'algorithme a détecté un seul visage — ce qui correspond très
probablement au nombre de visages qu'un annotateur humain aurait
trouvés sur l'image.
```{python}
colors = plt.cm.tab10.colors
fig, ax = plt.subplots(1, 1, figsize=(5, 7))
ax.imshow(img_list[2])
for i, face in enumerate(faces):
x1, y1, x2, y2 = [int(v) for v in face.bbox]
color = colors[i % len(colors)]
rect = patches.Rectangle((x1, y1), x2 - x1, y2 - y1, linewidth=2.5, edgecolor=color, facecolor="none")
ax.add_patch(rect)
ax.axis("off")
plt.tight_layout()
plt.show()
```
Pour pouvoir utiliser cette détection dans une analyse
computationnelle, il faut représenter la position du visage détecté
dans un format structuré. On construit une table polars à partir des
attributs `bbox` (coordonnées de la boîte englobante) et `det_score`
(score de confiance de la détection) de chaque visage. Voici toutes
les informations structurées sur le visage détecté dans l'image
précédente :
```{python}
if len(faces) > 0:
boxes = np.array([f.bbox for f in faces])
df = pl.DataFrame({
"face_id": list(range(len(faces))),
"xmin": boxes[:, 0].tolist(),
"ymin": boxes[:, 1].tolist(),
"xmax": boxes[:, 2].tolist(),
"ymax": boxes[:, 3].tolist(),
"prob": [float(f.det_score) for f in faces],
})
else:
df = pl.DataFrame(schema={"face_id": pl.Int32, "xmin": pl.Float32, "ymin": pl.Float32, "xmax": pl.Float32, "ymax": pl.Float32, "prob": pl.Float32})
df
```
Si vous avez suivi le notebook d'introduction sur les affiches de
films, c'est la même information que celle utilisée pour détecter le
nombre de visages présents sur chaque affiche. Ce qui change avec les
images animées, c'est qu'on retrouve souvent les mêmes personnes d'une
image ou d'un plan à l'autre. Étiqueter l'identité des personnes
présentes dans chaque plan est une étape essentielle pour comprendre
la structure narrative du matériau. **InsightFace** prend en charge la
reconnaissance faciale en plus de la détection. Cela demande un peu
plus de précautions : il faut commencer par identifier les personnages
que l'on souhaite reconnaître.
Par défaut, InsightFace associe également à chaque visage détecté une
séquence de 512 nombres appelée *plongement normalisé* (accessible via
l'attribut `normed_embedding`). Les nombres individuels n'ont pas de
signification directe : ils sont définis de manière relative, de sorte
que deux images d'une même personne aient des plongements plus
proches l'un de l'autre que des plongements de visages différents. À
titre d'exemple, voici la forme du tableau des plongements pour les
visages détectés sur notre image.
```{python}
np.array([f.normed_embedding for f in faces]).shape
```
Une façon d'utiliser ces plongements consiste à identifier d'abord les
portraits des acteurs qui nous intéressent dans la vidéo, puis à
associer chacun à un nom de personnage. On calcule ensuite les
plongements de ces visages et on les stocke. À chaque visage détecté
dans une image, on compare ensuite la similarité entre son plongement
et ceux de notre ensemble de référence. Si l'un des personnages de
référence est suffisamment proche, on suppose que c'est lui qu'on a
trouvé.
L'un des éléments téléchargés lors de la configuration du notebook
était un dossier contenant les portraits des quatre acteurs principaux
de *Bewitched*, nommés d'après leur personnage dans la série. Dans le
code ci-dessous, on parcourt ces images, on charge chacune avec PIL,
on lance InsightFace pour extraire le plongement, et on enregistre le
nom du personnage. On stocke aussi une vignette du portrait pour
l'affichage.
```{python}
face_embed = []
face_name = []
face_img = []
for path in sorted(os.listdir("faces")):
img = np.array(Image.open("faces/" + path).convert("RGB"))
img_bgr = img[:, :, ::-1]
ref_faces = face_app.get(img_bgr)
face_embed.append(ref_faces[0].normed_embedding)
face_name.append(path[:-4])
face_img.append(cv2.resize(img, (200, 250)))
face_embed = np.vstack(face_embed)
face_name = np.array(face_name)
face_img = np.hstack(face_img)
```
Voici les portraits des personnages. Ils sont rangés par ordre
alphabétique : Darrin, Endora, Larry et Sam.
```{python}
fig, ax = plt.subplots(1, 1, figsize=(12, 12))
ax.imshow(face_img)
ax.axis("off")
plt.tight_layout()
plt.show()
```
Pour mesurer la similarité entre deux plongements, on utilise une
technique mathématique appelée *produit scalaire*. Ce nombre vaut `1`
si deux plongements sont exactement identiques, et `-1` s'ils sont
exactement opposés. En général, deux visages de personnes différentes
auront un score de similarité proche de zéro. Commençons par regarder
les scores de similarité entre les quatre portraits.
```{python}
np.dot(face_embed, face_embed.T)
```
La première colonne correspond à Darrin, et compare Darrin à chacune
des quatre images. Comme c'est la première image, on lit `.99999`
parce que la photo est comparée à elle-même. L'image de Darrin est
ensuite comparée à Endora (`.06135`), Larry (`-.19993`) et Samantha
(`.16960`).
Les valeurs sur la diagonale valent toutes 1 (ou presque) parce qu'on
y compare un plongement à lui-même. Tous les autres scores se situent
entre environ `-0,2` et `+0,17`, comme attendu, puisque chaque
portrait représente un acteur différent.
Comparons maintenant ces visages de référence au plongement de l'image
avec laquelle nous avons commencé cette section : l'image
centrale du troisième plan, qui montre Samantha dans une chambre rose
(`img_list[2]`).
```{python}
image_bgr = img_list[2][:, :, ::-1]
frame_faces = face_app.get(image_bgr)
embeddings = np.array([f.normed_embedding for f in frame_faces])
dist = np.dot(face_embed, embeddings.T)
dist
```
On constate ici un score de similarité bien plus élevé (`0,59`) entre
ce visage et le dernier personnage de l'ensemble. Et en regardant
l'image, on voit en effet qu'il s'agit du même personnage : Samantha.
On peut associer le visage au nom du personnage de manière
algorithmique avec le code suivant.
```{python}
face_name[np.argmax(dist, axis = 0)]
```
Le code ci-dessus associe le visage au personnage dont la similarité
est la plus élevée. Il serait également judicieux de conserver le
score de similarité et de ne faire confiance à la correspondance que
si ce score est suffisamment grand. On peut l'obtenir avec le code
suivant.
```{python}
np.max(dist, axis = 0)
```
Maintenant que nous comprenons comment ce processus fonctionne sur une
seule image, appliquons-le à chacun des plans de l'extrait.
## 3.7 Construire des annotations à partir d'un fichier vidéo
On peut combiner les techniques précédentes avec la fonction
`yield_video` de **dvt** pour identifier les visages dans chacun des
plans. Il est possible de faire tourner l'algorithme de détection sur
chaque image, ce qui a certains avantages. Par souci de temps et de
simplicité, nous l'appliquerons uniquement à l'image centrale de
chaque plan détecté.
```{python}
output = []
for img, frame, msec in dvt.yield_video("bewitched_sample.mp4"):
if frame in shot['mid'].to_list():
img_bgr = img[:, :, ::-1]
faces = face_app.get(img_bgr)
if len(faces) > 0:
boxes = np.array([f.bbox for f in faces])
embeddings = np.array([f.normed_embedding for f in faces])
dist = np.dot(face_embed, embeddings.T)
n = len(faces)
output.append(pl.DataFrame({
"frame": [frame] * n,
"time": [msec] * n,
"xmin": boxes[:, 0].tolist(),
"ymin": boxes[:, 1].tolist(),
"xmax": boxes[:, 2].tolist(),
"ymax": boxes[:, 3].tolist(),
"prob": [float(f.det_score) for f in faces],
"character": face_name[np.argmax(dist, axis=0)].tolist(),
"confidence": np.max(dist, axis=0).tolist(),
}))
output = pl.concat(output)
output = output.filter(c.prob > 0.7)
output
```
Prenez quelques minutes pour revenir aux vignettes de ces visages
détectés et regarder dans quelle mesure elles correspondent aux
personnages effectivement présents (si vous ne connaissez pas
*Bewitched*, servez-vous des portraits pour apprendre les noms). La
correspondance devrait être bonne, même si le quatrième plan a une
confiance assez faible pour Darrin parce que son visage est assez
petit sur l'image centrale. On obtiendrait de meilleurs résultats en
ajoutant la première image du plan, plus centrée sur Darrin. Nous
recommandons toujours de revenir aux résultats et de les inspecter au
fur et à mesure. On peut alors ajuster son approche en fonction des
données audiovisuelles avec lesquelles on travaille et des questions
qui animent l'analyse.
## 3.8 Analyse du corpus complet
Nous disposons à présent de toutes les méthodes et de tout le code
nécessaires pour identifier les plans et les visages dans un fichier
d'images animées. Si nous avions un épisode entier de *Bewitched*,
nous pourrions exécuter la même séquence d'étapes sur l'épisode
complet sans rien changer. La seule différence serait que les
résultats prendraient bien plus de temps à arriver. Si nous avions un
dossier contenant chaque épisode de la série, il suffirait d'ajouter
une boucle supplémentaire pour parcourir chaque fichier vidéo, en
veillant à inclure le nom du fichier dans chaque ligne de la sortie.
Enfin, pour étendre tout cela à une autre série, il suffirait
d'ajouter dans notre dossier d'images de référence les portraits des
personnages que l'on souhaite identifier.
Nous revenons aux deux séries — *Bewitched* et *I Dream of Jeannie* —
qui sont au cœur du chapitre 5 de *Distant Viewing*. Le chapitre est
construit autour d'une comparaison de ces deux sitcoms magiques,
comparaison rendue possible par la combinaison de la détection des
plans, de la détection des visages, et de la reconnaissance des
visages.
L'ensemble complet des fichiers vidéo des deux séries est assez
volumineux et soumis au droit d'auteur. Le traitement de tous ces
fichiers prend aussi beaucoup de temps, en particulier dans une
session Colab gratuite. Puisqu'il n'est pas possible d'exécuter
directement les annotations ici sur le corpus complet, nous
travaillerons à la place avec les annotations précalculées
téléchargées lors de la configuration. Le jeu de données comporte une
ligne par plan, avec les informations de timing et le nombre de
visages.
```{python}
shots = pl.read_csv("data/ttl_sitcom_shots.csv")
shots
```
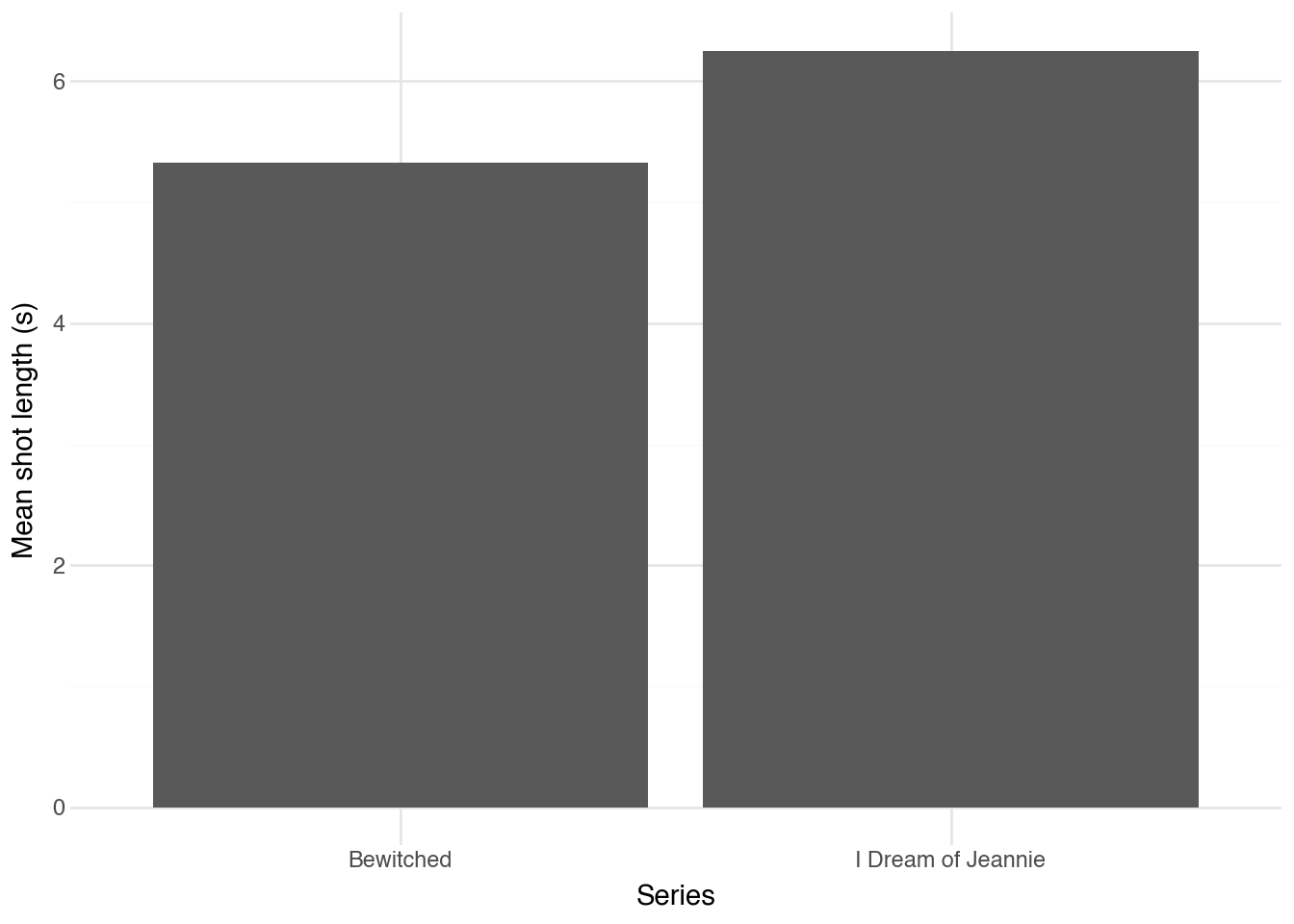
Un indicateur rapide à calculer est la durée moyenne d'un plan pour
chacune des deux séries. C'est une mesure couramment utilisée pour
comprendre le rythme d'un film ou d'une série. Ici, on voit que
*Bewitched* est légèrement plus rapide, avec une durée moyenne de
plan de 5,3 secondes contre 6,2 secondes pour *I Dream of Jeannie*.
```{python}
(
shots
.group_by(c.series)
.agg(time=c.time.mean())
.sort(c.time)
.pipe(ggplot, aes("series", "time"))
+ geom_col()
+ labs(x="Series", y="Mean shot length (s)")
)
```
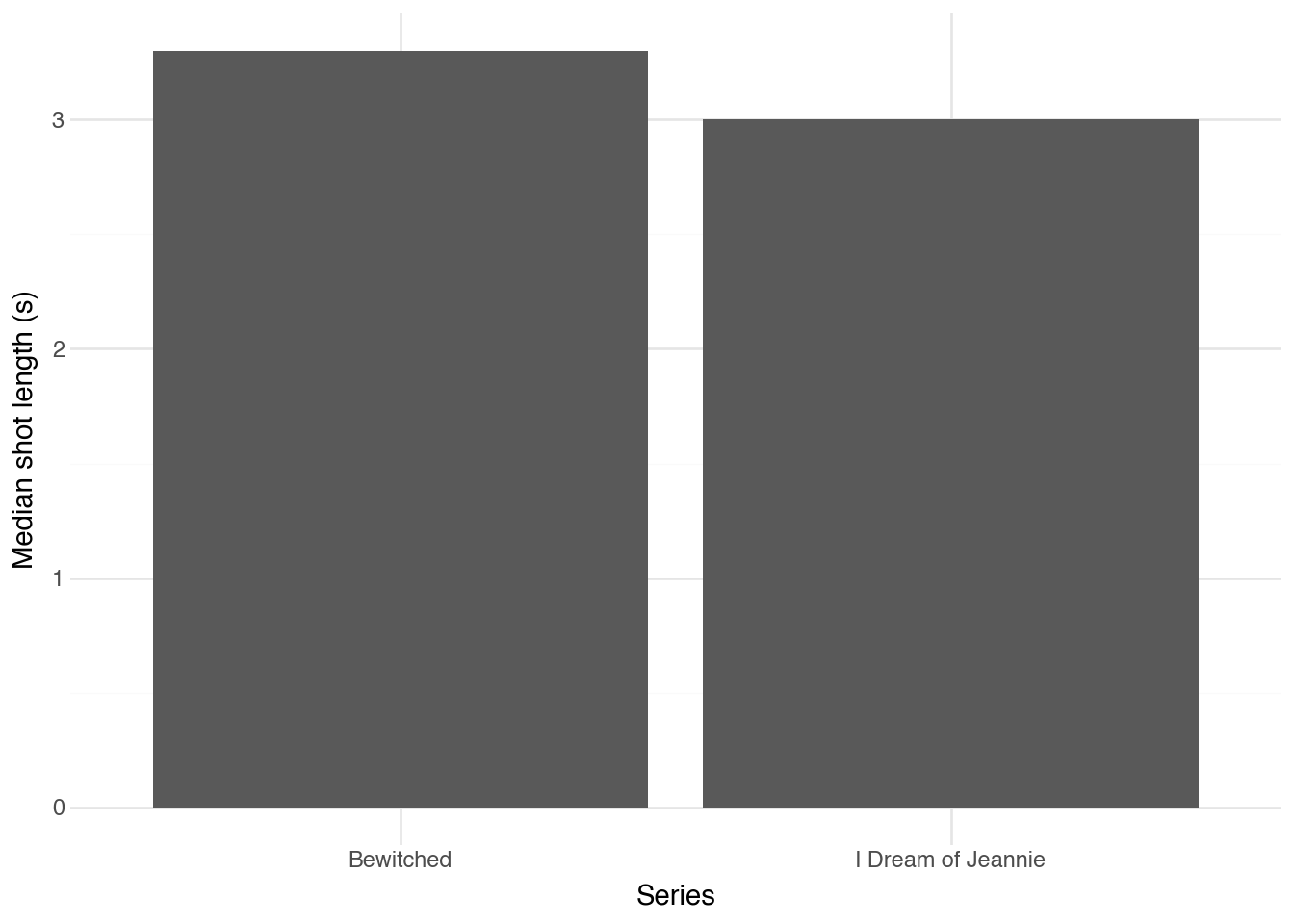
Une mesure proche est la durée médiane des plans, qui montre ici que
le plan médian est légèrement plus long dans *Bewitched* que dans
*Jeannie*. Autrement dit, même si la durée moyenne d'un plan est un
peu plus longue dans *Bewitched*, il pourrait y avoir dans *Jeannie*
un ensemble de plans particulièrement longs qui tirent la moyenne
vers le haut.
```{python}
(
shots
.group_by(c.series)
.agg(time=c.time.median())
.sort(c.time)
.pipe(ggplot, aes("series", "time"))
+ geom_col()
+ labs(x="Series", y="Median shot length (s)")
)
```
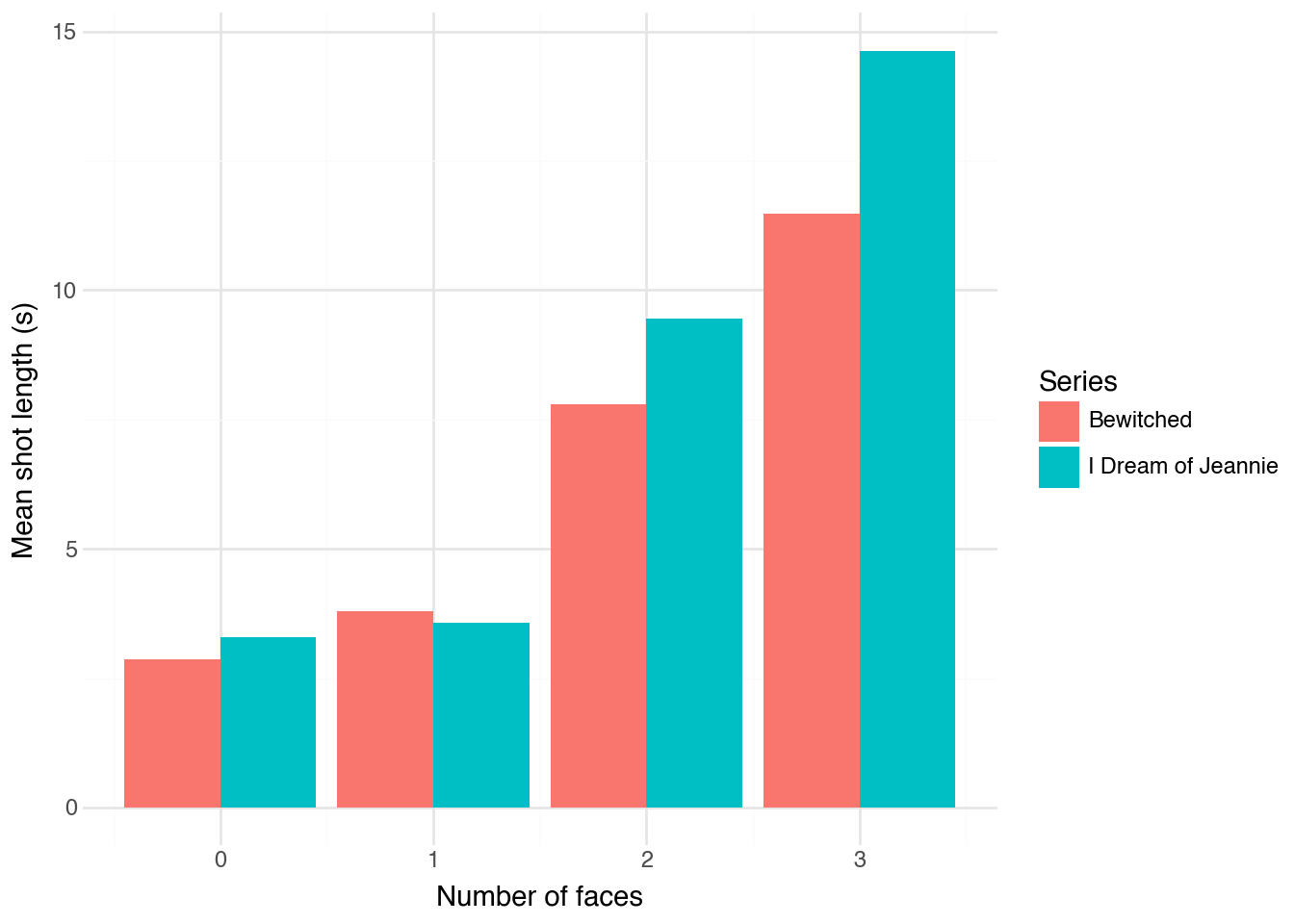
L'un des motifs intéressants que nous avons remarqués en rédigeant le
chapitre consacré à ces deux séries est que la durée moyenne d'un
plan est étroitement liée au nombre de visages présents à l'écran.
Nous avons choisi de plafonner le nombre de visages à trois (toute
valeur supérieure à 3 devient 3), au vu de notre connaissance des
deux séries. On voit comment la durée moyenne du plan augmente avec
le nombre de visages à l'écran, dans les deux séries.
```{python}
(
shots
.with_columns(num_face=pl.when(c.num_face > 3).then(3).otherwise(c.num_face))
.group_by([c.series, c.num_face])
.agg(time=c.time.mean())
.sort([c.series, c.num_face])
.pipe(ggplot, aes("num_face", "time", fill="series"))
+ geom_col(position="dodge")
+ labs(x="Number of faces", y="Mean shot length (s)", fill="Series")
)
```
Nous avons déjà vu un exemple de ce motif dans notre extrait : le seul
plan avec deux personnages était bien plus long que le plan avec un
seul personnage. Cela permet de confirmer que la durée des plans est
liée au style visuel. Pour ces deux séries, au moins, elle se rapporte
à la fréquence avec laquelle on voit un gros plan sur un personnage
seul (en train de parler ou d'agir) plutôt que plusieurs personnages
interagissant dans un plan plus long.
Nous disposons aussi d'un jeu de données indiquant les personnages
précis détectés dans les plans des deux séries. Il s'appuie sur un
algorithme de détection de visages similaire à celui utilisé dans
notre extrait. On a ici une ligne par personnage détecté dans un
plan. Il y a quatre personnages principaux dans chacune des séries.
```{python}
characters = pl.read_csv("data/ttl_sitcom_characters.csv")
characters
```
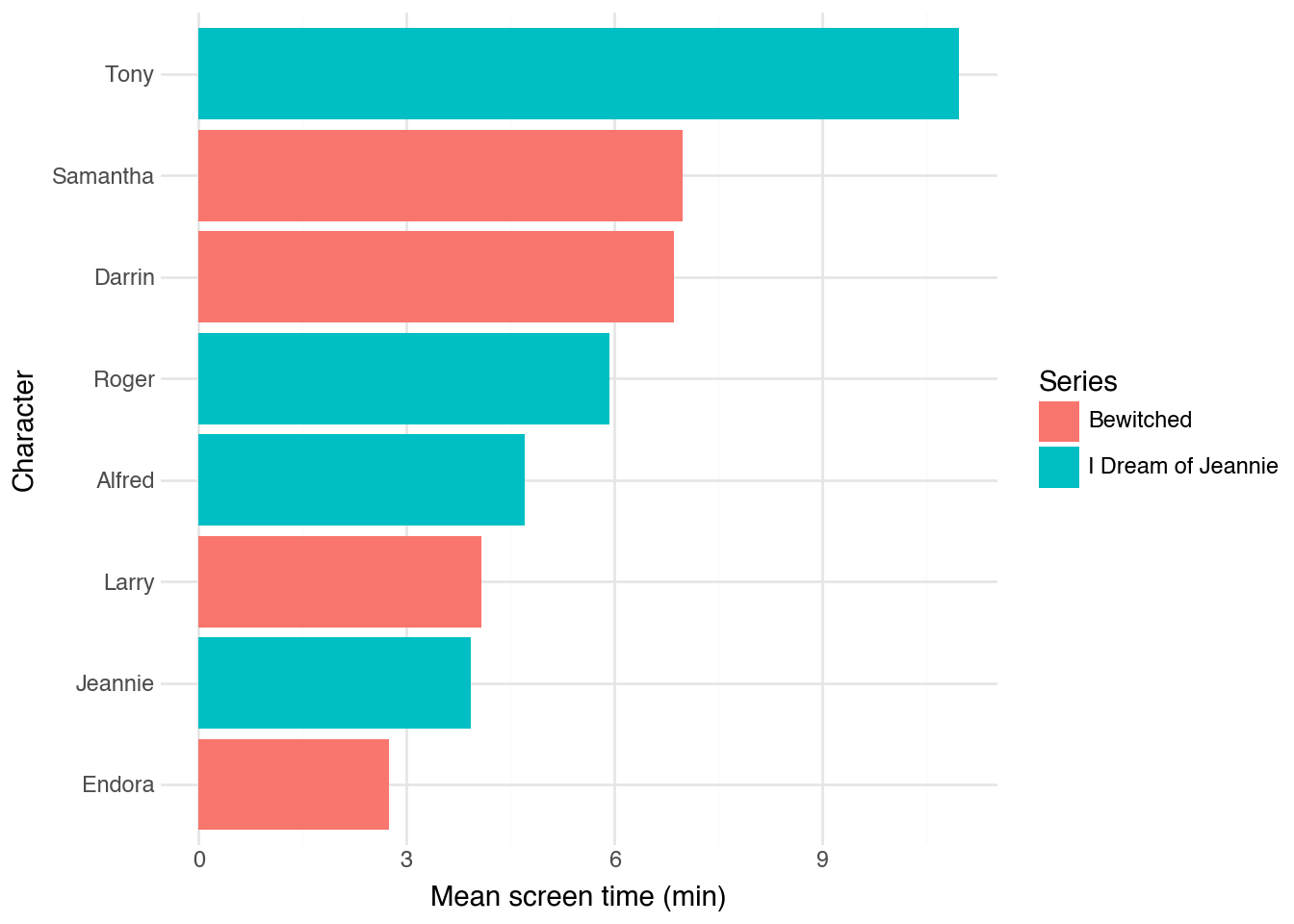
On peut utiliser le temps d'écran moyen d'un personnage dans un
épisode comme une mesure approximative de son importance visuelle
dans la série. On calcule cette mesure pour chacun des personnages,
puis on trie par ordre décroissant à l'intérieur de chaque série.
```{python}
(
characters
.group_by([c.series, c.video, c.character])
.agg(time=c.time.sum())
.group_by([c.series, c.character])
.agg(time=c.time.mean())
.with_columns(time=c.time / 60)
.sort([c.series, c.time], descending=[True, True])
.pipe(ggplot, aes("reorder(character, time)", "time", fill="series"))
+ geom_col(position="dodge")
+ coord_flip()
+ labs(x="Character", y="Mean screen time (min)", fill="Series")
)
```
On voit déjà apparaître l'une des principales conclusions de
l'analyse de ces séries : bien qu'elles soient perçues comme très
similaires, leurs structures narratives sont en réalité assez
différentes. *Jeannie* est en fait centrée sur le personnage masculin
Tony ; le personnage éponyme, Jeannie, n'est souvent guère plus qu'un
ressort narratif qui met l'action en mouvement. À l'inverse,
*Bewitched* se concentre surtout sur la relation entre Samantha et
Darrin, chacun bénéficiant d'un temps d'écran à peu près équivalent.
Nos annotations — détection de plans, détection et reconnaissance de
visages — peuvent maintenant être analysées sous de nombreux angles
différents pour explorer divers aspects des séries, ce que nous
approfondissons dans le chapitre 5. L'important ici est de voir que
trois annotations suffisent à ouvrir de nombreuses possibilités
analytiques, et permettent d'aborder des questions de sciences
humaines posées à des données audiovisuelles.
## 3.9 Conclusion et prochaines étapes
Ce notebook a proposé une introduction à l'annotation des données
d'images animées à partir d'un fichier vidéo numérique, en s'appuyant
sur deux bibliothèques complémentaires : le distant viewing toolkit
(**dvt**) pour les utilitaires vidéo et la détection des ruptures de
plan, et **InsightFace** pour la détection et la reconnaissance des
visages. Nous avons vu comment obtenir des métadonnées de base sur un
fichier vidéo depuis Python, comment parcourir les image une par
une, comment détecter les ruptures de plan, et comment localiser et
identifier des visages à l'aide de plongements. Enfin, nous avons
chargé un jeu de données plus large rassemblant l'ensemble des plans
et des personnages détectés sur l'intégralité de deux sitcoms
américains de l'ère des grands réseaux, et nous avons effectué
plusieurs exemples d'analyses sur ces données.
Pour les lecteurs intéressés par les détails de l'étude de cas
consacrée à ces deux séries, nous suggérons de lire le cinquième
chapitre du livre [*Distant
Viewing*](https://www.distantviewing.org/book/), disponible sous
licence libre. Les deux premiers chapitres du livre peuvent
également présenter de l'intérêt, car ils proposent une approche
théorique et méthodologique plus générale de l'analyse
computationnelle des images numériques.