# Tutoriel Distant Viewing 1 : Affiches de films et analyse des couleurs
[[**diapositives**](https://raw.githubusercontent.com/taylor-arnold/atelier/refs/heads/main/2026_dv/slides/tutoriel01.pdf)]
[[**chapitre**](https://direct.mit.edu/books/oa-monograph/chapter-pdf/2163342/c001700_9780262375160.pdf)]
[[**site web**](https://www.distantviewing.org)]
Ce notebook présente une introduction aux méthodes exposées dans le
livre *Distant Viewing: Computational Exploration of Digital Images* (MIT
Press, 2023). Nous reproduisons et étendons certaines parties de l'analyse
en utilisant une collection de 5000 affiches de films présentée dans le
troisième chapitre du livre. Aucune connaissance préalable de Python ou
de la vision par ordinateur n'est requise. Bien qu'une introduction
complète à Python dépasse le cadre de ce tutoriel, nous mettrons en
avant les principales caractéristiques du langage telles qu'elles
s'appliquent ici. Voici les objectifs d'apprentissage spécifiques du
tutoriel :
1. Expliquer comment les images numériques sont stockées sous forme de
tableaux de pixels.
2. Relier la structure des images numériques aux méthodes
computationnelles à travers le cadre du distant viewing.
3. Appliquer du code Python préconstruit pour étudier une collection
d'images numériques.
4. Expliquer les mesures telles que la teinte, la saturation, le chroma
et la valeur à l'aide de la théorie des couleurs.
5. Comparer la composition des affiches de films à travers le temps et
les genres.
Vous trouverez plus d'informations sur la théorie du distant viewing et son
application aux affiches de films dans notre livre, disponible en
téléchargement gratuit sous licence libre sur notre
[site web](https://www.distantviewing.org/book/), ainsi que des données
et du code supplémentaires permettant de reproduire les autres études
présentées dans le texte.
## 1.1 Configuration
Pour commencer, nous devons télécharger le jeu de données des affiches
de films, et indiquer à Python toutes les fonctions dont nous aurons
besoin par la suite. Le code ci-dessous télécharge les métadonnées et
les affiches de films que nous utiliserons dans ce notebook. Il
s'appuie sur le programme **wget** pour télécharger les fichiers depuis
le site distant viewing, suivi de la commande **tar** pour décompresser
le répertoire contenant les miniatures des affiches. Le point
d'exclamation au début de chaque ligne de code indique au notebook que
nous voulons exécuter directement un outil en ligne de commande en
dehors de Python. Nous explorerons le contenu de chacun de ces éléments
au fur et à mesure dans les sections suivantes. La dernière ligne
utilise **mkdir** pour créer un répertoire vide qui sera nécessaire
dans la dernière section du notebook pour exécuter les modèles
d'apprentissage automatique sur la collection. Pour exécuter le code,
passez votre souris sur l'arrière-plan du code. Un bouton de lecture
triangulaire apparaîtra à gauche du bloc de code. Cliquez sur le bouton
et attendez la fin de l'exécution, ce qui peut prendre une minute ou
deux. Toutes les lignes seront exécutées les unes après les autres. Une
petite flèche verte indique la ligne en cours d'exécution à tout
moment, ce qui nous aide à comprendre quelles étapes prennent le plus
de temps.
```{python}
#| eval: false
!mkdir -p data
!mkdir -p /root/.cache/torch/hub/checkpoints/
!wget -q -nc -P data/ "https://distantviewing.org/atelier/movies_50_years_meta.csv"
!wget -q -nc -P data/ "https://distantviewing.org/atelier/movies_50_years_hue.csv"
!wget -q -nc -P data/ "https://distantviewing.org/atelier/movies_50_years_genre_fra.csv"
!wget -q -nc "https://distantviewing.org/atelier/mp_med.tar"
!wget -q -nc "https://distantviewing.org/atelier/funs.py"
!tar -xf mp_med.tar --warning=no-unknown-keyword
!mv mp_med data
```
Dans la dernière partie de la configuration, nous allons exécuter du
code en Python (les lignes ci-dessous ne commencent pas par un point
d'exclamation). Ce code utilise la commande **import** pour indiquer à
Python quelles bibliothèques et fonctions nous allons utiliser dans le
notebook. Il s'agit de **matplotlib.pyplot** et **matplotlib.patches**
pour la visualisation de données, **torch** pour l'apprentissage
automatique, **polars** pour les jeux de données tabulaires, **numpy**
pour travailler avec de grands tableaux de nombres, et **cv2** (la
bibliothèque OpenCV pour le traitement d'images). Les dernières lignes
chargent quelques composants supplémentaires : **PIL** pour ouvrir des
images, un alias `c` pour les colonnes de polars, nos propres fonctions
utilitaires depuis le fichier `funs`, et **plotnine** pour la création
de graphiques selon la grammaire des graphiques.
```{python}
import matplotlib.pyplot as plt
import matplotlib.patches as patches
import torch
import polars as pl
import numpy as np
import cv2
from PIL import Image
from polars import col as c
from funs import *
from plotnine import *
theme_set(theme_minimal())
```
Dans Google Colab, votre environnement de travail se réinitialise à
chaque fois que vous rouvrez un notebook. Toutes les étapes ci-dessus
doivent donc être ré-exécutées à chaque démarrage du notebook. Si vous
exécutiez ce code sur votre propre machine, le téléchargement des
données ne devrait être fait qu'une seule fois. Le chargement des
modules dans le dernier bloc de code, en revanche, doit toujours être
exécuté à chaque redémarrage de Python.
## 1.2 Jeu de données des affiches de films
Avant de plonger dans l'analyse des images d'affiches de films, il est
important de prendre un moment pour examiner les métadonnées attachées
à chaque affiche et comprendre la structure du jeu de données. Dans le
code ci-dessous, nous utilisons la fonction `read_csv` du module polars
(que nous avons abrégé en **pl** selon la convention)
pour charger le fichier csv contenant une ligne par film de notre jeu
de données. Nous enregistrons la sortie de la fonction dans un objet
nommé `posters`. À la dernière ligne, nous écrivons simplement le nom
de l'objet, ce qui affiche les premières lignes du jeu de données dans
le notebook. Les données contiennent une ligne pour chacun des 100
films les plus rentables de chaque année, de 1970 à 2019. Pour
quelques films des années 1970, nous n'avons pas pu trouver les
affiches ; ceux-ci sont exclus du jeu de données. Pour chaque film,
nous disposons de l'année, du titre, du nom du fichier image associé à
l'affiche, et d'une description de la demi-décennie dont provient le
film. Cette dernière sera utilisée dans notre analyse des évolutions
au fil du temps.
```{python}
posters = pl.read_csv("data/movies_50_years_meta.csv")
posters
```
Nous disposons d'un autre ensemble de métadonnées qui associe chaque
film à une ou plusieurs catégories de genre. Le jeu de données contient
une ligne pour chaque paire film/étiquette de genre. L'année est
incluse parce que plusieurs films partagent le même titre, mais
peuvent être identifiés de manière unique en connaissant à la fois le
titre et l'année.
```{python}
genre = pl.read_csv("data/movies_50_years_genre_fra.csv")
genre
```
En examinant les premières et dernières lignes, les étiquettes de
genre semblent-elles cohérentes pour les films concernés ? Nos analyses
dans la suite du notebook se concentreront sur les motifs des affiches
de films à travers les périodes et les genres.
Maintenant que nous avons une idée de nos données, quelles questions
pourrait-on vouloir explorer ?
## 1.3 Images numériques
Maintenant que nous avons vu les métadonnées des affiches, regardons
comment les images numériques sont manipulées en Python en chargeant
l'image d'une seule affiche. Toutes les affiches sont stockées au
format JPEG (abréviation de Joint Photographic Experts Group). Il
s'agit d'un format d'image courant qui peut être ouvert et compris
par presque tous les programmes ou appareils qui travaillent avec des
images. Si vous ouvriez un fichier JPEG sur votre ordinateur ou votre
téléphone, l'image s'afficherait sans configuration particulière. La
plupart des images que vous voyez sur les sites web publics sont
stockées au format JPEG et sont traitées et affichées par votre
navigateur.
Dans le code ci-dessous, nous utilisons la fonction `Image.open` de la
bibliothèque PIL pour charger une image en Python. Nous enregistrons
l'image dans un objet nommé `img`. Le chemin vers l'image de l'affiche
est tiré directement des métadonnées ci-dessus. Ici, nous utilisons la
formule suivante : le nom du jeu de données (`posters`), filtré pour ne
garder que la ligne du film *Chisum*, suivi du nom de la colonne
(`filepath`) et du numéro de ligne entre crochets (`[0]`). Nous avons
choisi l'affiche du film *Chisum* avec John Wayne car elle présente une
tonalité orange marquée qui sera intéressante à examiner. Après avoir
chargé l'image en Python, nous l'affichons en l'inscrivant seule sur la
dernière ligne.
```{python}
img = Image.open(
posters.filter(c.title == "Chisum")["filepath"][0]
)
img
```
On voit qu'il est relativement facile de charger un format d'image
courant en Python puis de l'afficher dans le notebook. Pour bien
comprendre les analyses computationnelles qui suivent, il sera utile
d'examiner la façon dont une image numérique est représentée en
Python. Nous pouvons utiliser la fonction Python intégrée `type` pour
voir le type d'objet de n'importe quel objet Python. Faisons-le
ci-dessous :
```{python}
type(img)
```
L'objet `PIL.JpegImagePlugin` n'est pas adapté au traitement numérique. Nous pouvons le transférer vers un `numpy.ndarray`
```{python}
arr = np.asarray(img)
type(arr)
```
Qu'est-ce que cela signifie ? Il s'agit d'un type de données générique créé
par la bibliothèque numpy (la même que celle chargée dans la section de
configuration) pour stocker des blocs rectangulaires de nombres.
Pour comprendre comment un tableau de nombres peut représenter une
image, nous allons afficher l'attribut `shape` de l'objet (un attribut
est une caractéristique d'un objet Python, accessible avec le nom de
l'objet suivi d'un `.` et du nom de l'attribut). Cela nous indique
comment les nombres du tableau sont organisés.
```{python}
arr.shape
```
On voit que la forme de l'objet a trois composantes. Le premier nombre
indique combien de lignes de nombres il y a, et le second combien de
colonnes. Le troisième nombre indique qu'il existe une troisième
dimension de taille trois. La façon la plus simple de se le
représenter est d'imaginer trois grilles rectangulaires de nombres,
chacune avec 229 lignes et 150 colonnes. Pensez à un fichier Excel
avec trois feuilles, chacune contenant une grille de nombres de même
taille.
Une ligne et une colonne précises dans cette grille de nombres
représentent un *pixel* (picture + element), la plus petite unité
individuelle d'une image. Nous avons besoin de trois nombres pour
chaque pixel afin d'indiquer la quantité de lumière rouge, verte et
bleue à combiner pour créer la couleur à cet emplacement précis. La
bibliothèque Python utilisée ici représente la quantité de lumière sur
une échelle allant de 0 (éteint) à 255 (le plus brillant possible). En
mélangeant ces trois composantes, on peut recréer presque toutes les
couleurs perceptibles par l'œil humain.
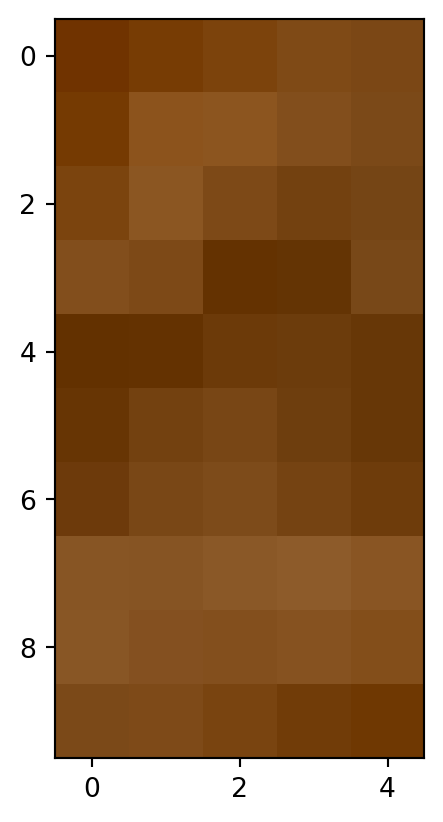
Pour rendre cela plus concret, voyons un exemple des nombres qui
composent l'image ci-dessus. Il y en a beaucoup trop à examiner d'un
seul coup. Nous utiliserons plutôt une notation entre crochets pour
sélectionner les dix premières lignes, les huit premières colonnes, et
la première composante de couleur. Python adopte une convention
courante en programmation qui consiste à commencer à compter à zéro :
le `0` ci-dessous prend donc le premier tableau de nombres, qui
correspond ici à l'intensité de la couleur rouge.
```{python}
arr[:10, :8, 0]
```
La portion de l'image que nous avons extraite ci-dessus est le coin
supérieur gauche. On voit que pour représenter ce coin, il faut
allumer une bonne quantité de lumière rouge (environ 200 sur les 255
possibles). Pourtant, en regardant l'image, on ne voit pas de rouge à
cet endroit : le coin supérieur gauche semble blanc. Pour comprendre
pourquoi, regardons la deuxième composante, qui correspond à la
quantité de lumière verte.
```{python}
arr[:10, :8, 1]
```
Et tant qu'on y est, la quantité de lumière bleue aussi.
```{python}
arr[:10, :8, 2]
```
On voit que les lumières rouge, verte et bleue sont toutes allumées au
même niveau dans le coin supérieur gauche de l'image. Lorsque l'on
mélange ces trois couleurs, on obtient une nuance de gris. Plutôt
noire quand les couleurs sont toutes faibles, plutôt blanche quand
elles sont toutes élevées. Cela correspond à ce que l'on voit dans le
coin supérieur gauche : une nuance de gris très proche du blanc.
Pour bien saisir le fonctionnement de ces composantes, examinons une
autre partie de l'image, correspondant aux lignes 180-190 et aux
colonnes 25-30. C'est très petit, mais en regardant attentivement on
devrait pouvoir le relier à l'image ci-dessus. L'image obtenue est
trop petite pour que Colab la traite automatiquement comme une image à
afficher ; nous utilisons donc la fonction `plt.imshow` pour afficher
les valeurs de pixels comme des pixels.
```{python}
plt.imshow(arr[180:190, 25:30, :])
```
Cette petite fenêtre fait partie de la zone orange en bas de
l'affiche. Voyons les composantes rouge, verte et bleue qui composent
cette couleur.
```{python}
arr[180, 25, :]
```
L'orange foncé provient du mélange d'une bonne quantité de lumière
rouge (189/255), d'un peu de vert (106/255), et de pas de bleu
(0/255). Un coup d'œil à une roue chromatique permet de comprendre
pourquoi l'orange résulte du mélange d'un peu de vert et de beaucoup
de rouge.
Les bibliothèques de traitement d'images utilisent des conventions
légèrement différentes pour représenter les images numériques. La
plupart utilisent le même ordre de couleurs (rouge, vert, bleu), et
certaines utilisent des fractions entre 0 et 1 plutôt que des entiers
entre 0 et 255. Certains formats d'image incluent une quatrième
composante, appelée canal alpha, pour représenter l'opacité. D'autres
formats ne contiennent qu'un seul canal de couleur pour représenter
les images en niveaux de gris. Mais tous ces formats reposent sur le
même concept fondamental : représenter les images numériques par des
nombres indiquant les intensités des pixels. C'est une manière très
différente de penser les images de celle dont les humains traitent les
signaux visuels, ce que nous explorerons dans la section suivante.
Nous savons désormais regarder de près les couleurs des affiches, et
nous pouvons combiner cela avec les métadonnées.
Quelles autres questions peut-on se poser sur les affiches de films ?
## 1.4 Distant Viewing : théorie
Les ordinateurs représentent les images comme des tableaux
tridimensionnels de nombres. C'est très différent de la façon dont les
images sont interprétées et utilisées par les spectateurs humains. De
plus, le lien entre ces deux représentations n'a rien d'évident. Il
est impossible de comprendre ce qui est représenté par un petit
sous-ensemble d'intensités de pixels sans voir une grande partie de
l'image dans son ensemble. Même quelque chose d'aussi simple que la
quantité de lumière bleue dans un pixel peut être difficile à
interpréter. Beaucoup de bleu peut signifier la couleur bleue, ou
seulement un mélange avec du rouge et du vert pour produire du blanc.
Pour mener des analyses computationnelles sur de grandes collections
d'images numériques, il faut donc d'abord convertir ces intensités de
pixels brutes en représentations correspondant aux interprétations des
images qui nous intéressent.
La théorie du distant viewing découle exactement de ce constat : la
façon dont les images numériques sont représentées nous oblige à
construire des *annotations* contenant des données structurées
alignées sur nos questions de recherche. Ces annotations, qui peuvent
être créées manuellement ou à l'aide d'algorithmes, sont à la fois
destructives (il y a une perte d'information lors de leur création) et
ouvertes à l'interprétation (il n'existe pas de manière neutre de
créer des annotations ; des choix doivent toujours être faits).
Nous progresserons vers des annotations plus complexes, mais
commençons par l'une des plus simples : la luminosité de l'image. Les
intensités des pixels nous indiquent à quel point allumer les lumières
rouge, verte et bleue à chaque position de l'image. Plus ces nombres
sont élevés, plus l'image est lumineuse à l'affichage. Une manière de
créer une annotation pertinente sur une image consiste donc à prendre
la valeur moyenne de toutes les intensités de pixels. On peut le faire
avec le code suivant, qui utilise la fonction `mean` de numpy pour
calculer la moyenne de toutes les valeurs d'un tableau.
```{python}
np.mean(arr)
```
Il faut sans doute peu d'arguments pour convaincre que beaucoup
d'informations sont perdues entre ce nombre unique et toute la
richesse présente dans la miniature de l'affiche. Aucune information
sur le contenu du texte de l'image, sur la dominante orange, sur la
silhouette de l'homme et du cheval, sur la bordure blanche, ou sur la
disposition de ces éléments dans le cadre. Le processus de création
d'annotations est donc clairement destructif. La différence entre
l'annotation résumée (un seul nombre) et l'information de l'image
d'origine est ce que la théorie de l'information appelle un *écart
sémantique*. Mais qu'en est-il de la seconde partie de la théorie,
selon laquelle cette mesure n'est pas neutre et reflète des choix
spécifiques sur la façon dont nous voulons *voir* à distance ? Cela
peut sembler moins évident, mais il existe de nombreuses façons de
mesurer la luminosité d'une image. Par exemple, on pourrait considérer
la valeur médiane des intensités plutôt que leur moyenne, comme dans
le code ci-dessous.
```{python}
np.median(arr)
```
Par ailleurs, l'œil humain étant plus sensible au vert qu'au bleu ou
au rouge, on pourrait pondérer la luminosité plus fortement selon la
couleur. Beaucoup d'affiches ont des bordures noires ou blanches, qui
peuvent fortement influencer la luminosité globale. On pourrait
peut-être ne calculer la luminosité que sur la partie centrale de
l'image. Et d'ailleurs, pourquoi se soucier de la luminosité en
premier lieu ? Dès lors que l'on commence à envisager toutes ces
options, il devient clair qu'il n'existe pas de manière parfaite de
représenter un élément d'image sous forme de données structurées. Des
choix et des compromis sont toujours faits. Il faut bien finir par en
faire, et voir ce qu'on peut en apprendre, tout en gardant à l'esprit
la nature des annotations d'images et les écarts sémantiques qui en
résultent. Autrement dit, lorsque nous analysons des images par vision
par ordinateur, nous faisons du distant viewing.
## 1.5 Annoter la luminosité de l'image
Nous avons examiné en détail la manière dont les images numériques
sont stockées, vu les implications pour la théorie du distant viewing,
et présenté une façon particulière de construire une annotation à
travers la luminosité. Mettons maintenant tout cela en pratique pour
analyser les affiches de films selon leur luminosité globale. Première
étape : répéter sur toutes les images du jeu de données le processus
appliqué à la seule affiche ci-dessus. Pour cela, on utilise une
boucle Python. Elle est constituée du mot-clé `for` suivi d'un bloc de
code indenté. Chaque ligne du code indenté sera exécutée une fois pour
chaque valeur de la variable d'itération `ind`, prise dans l'ensemble
des numéros de lignes du jeu de données `posters`. Nous chargerons
donc l'image de chaque affiche, calculerons sa luminosité, et
l'enregistrerons dans une nouvelle colonne ajoutée au jeu de données.
Pour coller au plus près des résultats du livre, nous diviserons la
luminosité par 255 afin que les valeurs aillent de 0 (totalement noir)
à 1 (totalement blanc).
```{python}
results = []
for row in posters.iter_rows(named=True):
arr = np.asarray(Image.open(row["filepath"]))
results.append(np.mean(arr) / 255)
posters = posters.with_columns(
avg_brightness = pl.Series(results).round(4)
)
```
Maintenant que la luminosité a été ajoutée à chaque ligne des données
d'affiches, nous pouvons les trier de la plus lumineuse à la plus
sombre avec la méthode `sort`.
```{python}
posters.sort(c.avg_brightness, descending=True)
```
La théorie du distant viewing nous rappelle que la création
d'annotations, étape nécessaire de l'analyse computationnelle
d'images, est à la fois destructive et subjective. Avant de passer à
une analyse agrégée, il est donc utile de relier les annotations aux
images en regardant effectivement quelques affiches. Une manière de
faire est de regarder les affiches aux valeurs extrêmes. Dans le code
ci-dessous, nous chargeons la première image du jeu de données trié,
soit l'affiche ayant la luminosité la plus élevée. Rappelez-vous que
Python commence à compter à zéro : le zéro de la première ligne
correspond à la première ligne des données.
N'hésitez pas à examiner d'autres lignes particulièrement lumineuses
pour avoir une vision plus complète de ce que capture l'annotation.
```{python}
(
posters
.sort(c.avg_brightness, descending=True)
.pipe(plot_image_grid, ncol=4, limit=12, label_name="avg_brightness")
)
```
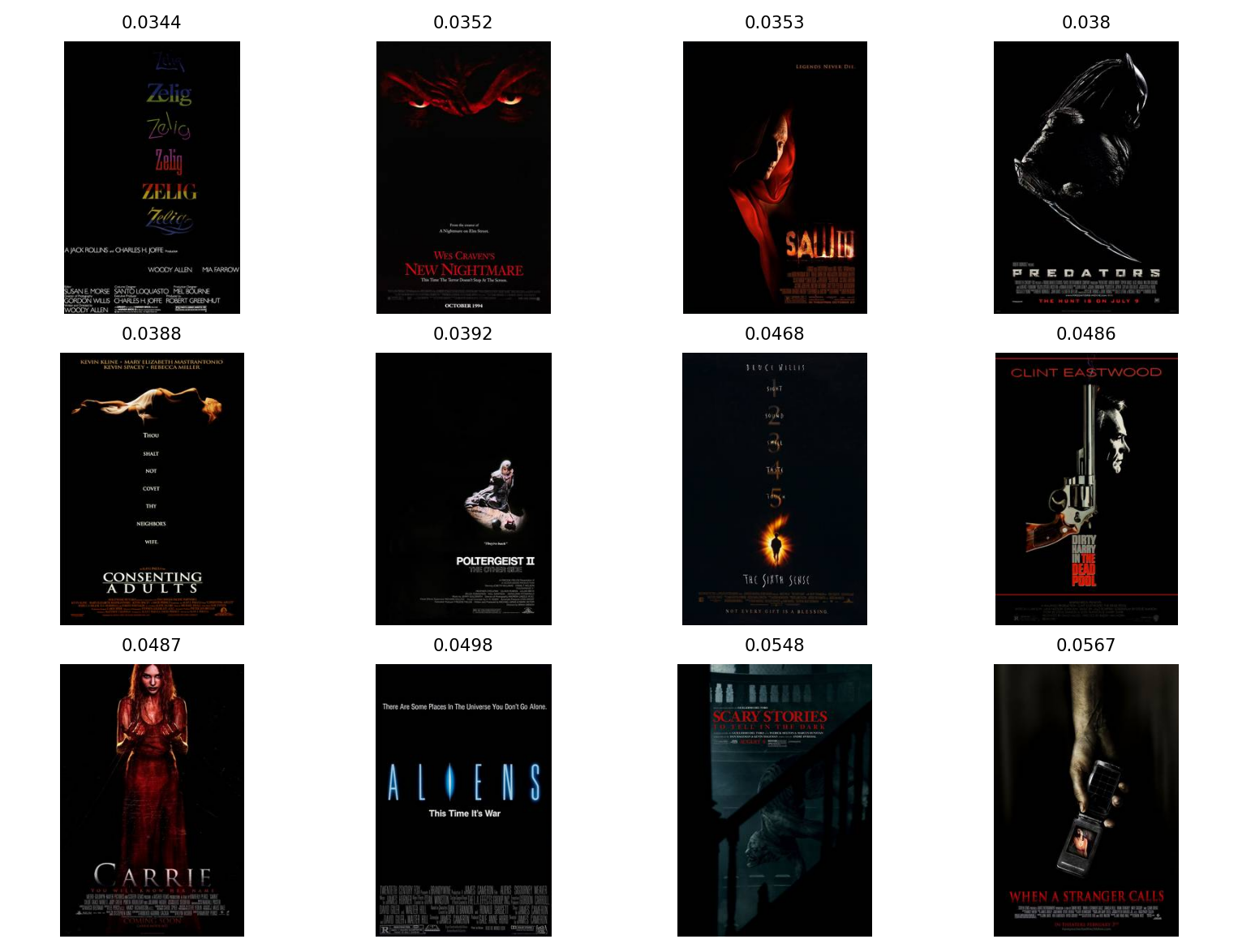
Il est tout aussi utile de regarder les images les plus sombres du
jeu de données. Pour cela, on modifie le code pour commencer au
nombre de lignes moins un (toujours à cause de la convention Python
qui démarre à zéro). On peut remplacer le -1 par -n pour examiner la
n-ième image la moins lumineuse.
```{python}
(
posters
.sort(c.avg_brightness, descending=False)
.pipe(plot_image_grid, ncol=4, limit=12, label_name="avg_brightness")
)
```
Après avoir examiné quelques exemples, que pensez-vous de la capacité
de l'annotation à capturer la luminosité des affiches ? Au moins aux
extrêmes, quels éléments de l'affiche semblent le mieux
expliquer/prédire sa luminosité ?
Maintenant que nous avons une idée du fonctionnement de l'annotation,
et, espérons-le, une certaine confiance dans le fait qu'elle reflète
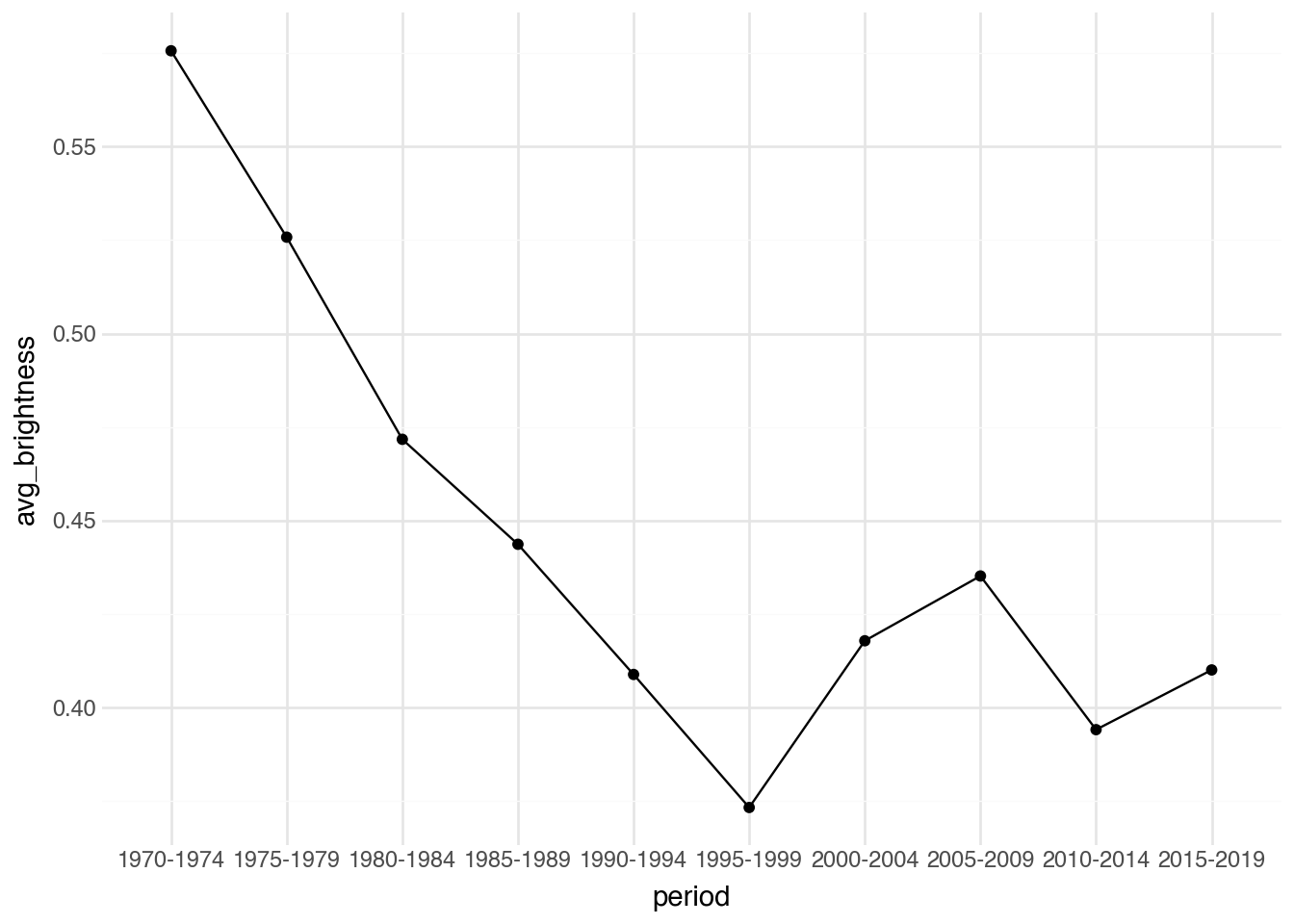
une quantité significative, passons à une analyse agrégée. Le code
ci-dessous regroupe notre jeu de données par `period` (demi-décennies
de 1970 à 2019) et examine la luminosité moyenne de toutes les
affiches de chaque période.
```{python}
(
posters
.group_by(c.period)
.agg(avg_brightness = c.avg_brightness.mean())
.sort(c.period)
)
```
```{python}
(
posters
.group_by(c.period)
.agg(avg_brightness = c.avg_brightness.mean())
.sort(c.period)
.pipe(ggplot, aes("period", "avg_brightness"))
+ geom_point()
+ geom_line(group=1)
)
```
Comment décririez-vous le motif observé ici ? Y a-t-il une tendance
significative ? Si oui, avez-vous des hypothèses sur ce qui pourrait
l'expliquer ?
Faisons une analyse similaire en utilisant les genres associés à
chaque film. Pour cela, nous utilisons d'abord la méthode `join`
pour combiner les données des affiches avec la table des genres.
```{python}
(
posters
.join(genre, on=[c.year, c.title])
)
```
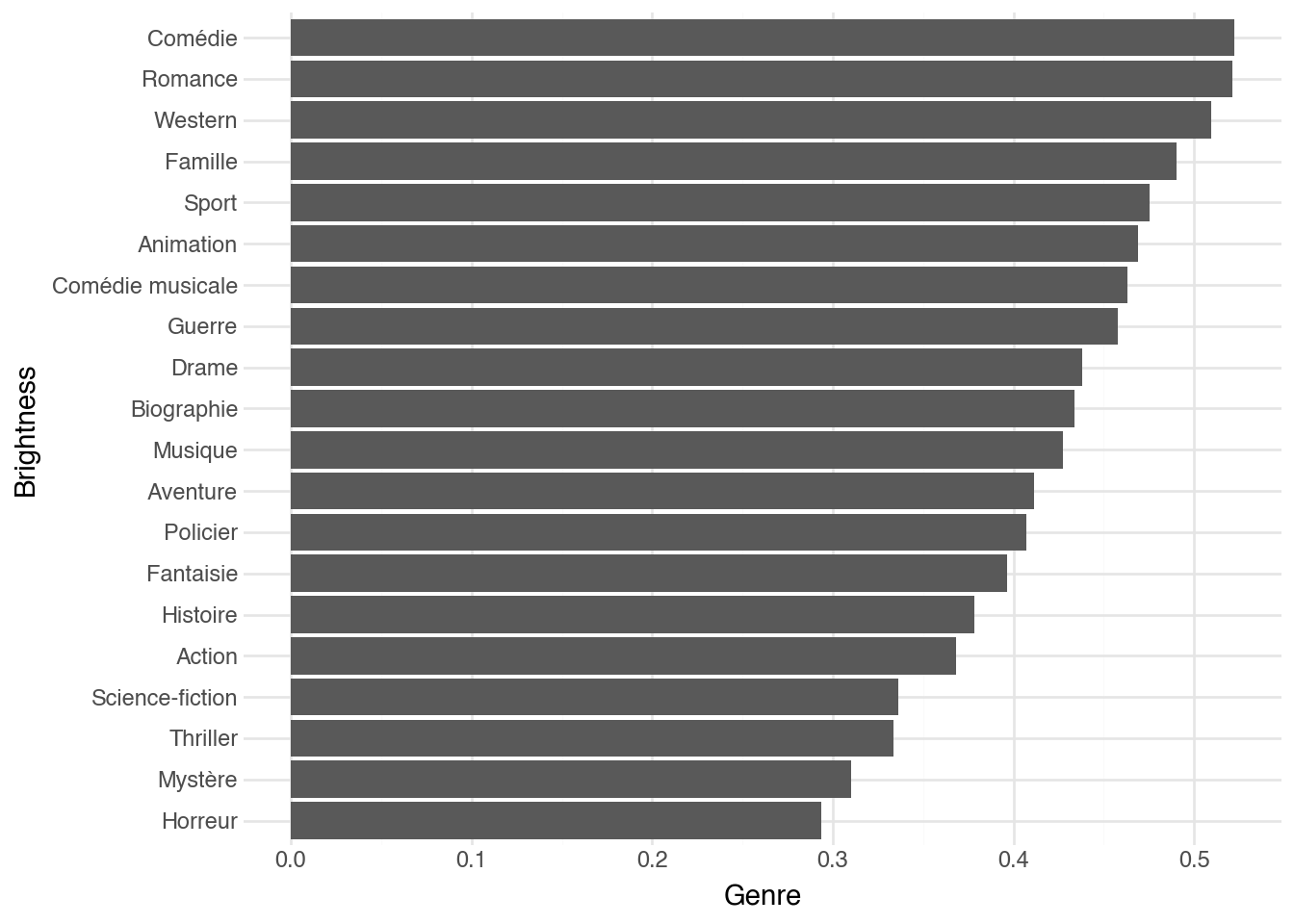
Nous pouvons ensuite répéter l'analyse en regroupant par genre et en
prenant la luminosité moyenne de chaque genre. Là où il était logique
de classer les périodes par ordre chronologique pour faire ressortir
une tendance, il sera ici préférable de laisser Python classer les
genres selon leur luminosité moyenne. On le fait avec la méthode
`sort` sur les données résumées.
```{python}
(
posters
.join(genre, on=[c.year, c.title])
.group_by(c.genre)
.agg(avg_brightness = c.avg_brightness.mean())
.sort(c.avg_brightness)
.pipe(ggplot, aes("reorder(genre, avg_brightness)", "avg_brightness"))
+ geom_col()
+ coord_flip()
+ labs(x="Brightness", y="Genre")
)
```
Quels motifs remarquez-vous parmi les genres ? Lesquels semblent
avoir les affiches les plus sombres, lesquels les plus lumineuses ?
Pouvez-vous résumer cette tendance ? Avez-vous des hypothèses sur ce
qui se passe ici ?
## 1.6 Saturation et chroma
Nous avons déjà vu qu'avec une analyse soignée, on peut faire pas mal
de choses avec une annotation relativement simple fondée sur la
luminosité. Mais notre objectif est de comprendre plus largement
l'usage de la couleur dans les affiches de films, ce qui demande de
créer d'autres annotations capturant d'autres aspects de la couleur.
Une façon de faire est de convertir les intensités de pixels brutes
dans un autre espace colorimétrique.
La représentation RGB des pixels par les quantités de lumière rouge,
verte et bleue nécessaires pour créer une couleur à un point donné
vient des contraintes techniques de capture et d'affichage. Comme on
l'a vu, ce n'est pas une manière particulièrement pertinente de
penser notre perception des couleurs. Heureusement, il existe d'autres
façons de représenter la couleur, plus proches de la perception
humaine. Pour comprendre comment cela fonctionne, rechargeons
l'affiche du film *Chisum* avec John Wayne.
```{python}
arr =np.asarray(Image.open(
posters.filter(c.title == "Chisum")["filepath"][0]
))
```
Rappelons que nous avions repéré plus haut un pixel correspondant à
l'orange brûlé de l'affiche. Sa représentation RGB est la suivante :
```{python}
arr[180, 25, :]
```
On peut convertir le format RGB en format HSV avec la fonction
`cv2.cvtColor` en spécifiant le type de transformation
colorimétrique (`COLOR_RGB2HSV`) en second argument. Nous effectuerons
quelques conversions d'échelle de sortie pour les ramener entre 0 et
1, ce qui correspond mieux aux autres sources ainsi qu'à la
discussion plus détaillée de cette étude de cas au chapitre 3 de
*Distant Viewing*.
```{python}
arr_hsv = cv2.cvtColor(arr, cv2.COLOR_RGB2HSV)
arr_hsv = arr_hsv.astype(np.float64)
arr_hsv[:, :, 0] = arr_hsv[:, :, 0] / 179.0
arr_hsv[:, :, 1] = arr_hsv[:, :, 1] / 255.0
arr_hsv[:, :, 2] = arr_hsv[:, :, 2] / 255.0
arr_hsv.shape
```
La forme de la sortie est exactement la même que celle de l'image
originale. Les lignes et les colonnes correspondent toujours aux
mêmes positions que dans le modèle RGB ; seul le triplet de nombres à
cet emplacement a changé. Voyons à quoi ressemble maintenant notre
pixel orange brûlé :
```{python}
arr_hsv[180, 25, :]
```
La première composante vaut environ `0,095`. Elle correspond à la
**teinte** (hue) du pixel, et ce nombre correspond à l'orange. La
teinte est un peu complexe et nous l'examinerons plus en détail dans
la section suivante. Le deuxième nombre est la **saturation**, qui
indique la richesse de la couleur. Un pastel pâle, comme un rose pâle,
aura une saturation faible. Ici, la saturation est à son maximum :
`1`. Enfin, la valeur est une autre représentation de la luminosité,
ici égale à `0,74`.
Concentrons-nous maintenant sur la saturation des affiches et faisons
une analyse similaire à celle menée sur la luminosité. Pour coller au
plus près de l'analyse du livre, nous calculerons la quantité
apparentée appelée **chroma** plutôt que de travailler directement
avec la saturation. Elle s'obtient en multipliant la saturation par
la valeur. Nous utilisons cette quantité car elle correspond mieux à
l'idée de richesse de couleur que nous cherchons à capturer. Par
exemple, l'orange brûlé de notre affiche *Chisum* a une saturation
de `1`, mais un chroma de seulement `0,74` (saturation fois valeur).
Seul un orange « pur », comme celui d'une roue chromatique, aurait un
chroma de 1.
Parcourons maintenant les affiches et ajoutons à chacune la valeur
moyenne de chroma, comme nous l'avons fait pour la luminosité.
```{python}
results = []
for row in posters.iter_rows(named=True):
arr = np.asarray(Image.open(row["filepath"]))
arr_hsv = cv2.cvtColor(arr, cv2.COLOR_RGB2HSV)
arr_hsv = arr_hsv.astype(np.float64)
arr_hsv[:, :, 0] = arr_hsv[:, :, 0] / 179.0
arr_hsv[:, :, 1] = arr_hsv[:, :, 1] / 255.0
arr_hsv[:, :, 2] = arr_hsv[:, :, 2] / 255.0
results.append(np.mean(arr_hsv[:, :, 1] * arr_hsv[:, :, 2]))
posters = posters.with_columns(
avg_chroma = pl.Series(results).round(4)
)
```
Et de nouveau, nous trierons les données d'affiches du chroma le plus
élevé au plus faible.
```{python}
posters.sort(c.avg_chroma, descending=True)
```
Examinons à nouveau quelques affiches aux valeurs extrêmes. C'est
toujours une étape importante, lorsqu'on travaille avec de nouvelles
annotations, de revenir aux images originales et de les regarder pour
voir comment la représentation numérique correspond à notre propre
perception et interprétation. Comme avant, n'hésitez pas à explorer
d'autres affiches aux valeurs particulièrement élevées.
```{python}
(
posters
.sort(c.avg_chroma, descending=True)
.pipe(plot_image_grid, ncol=4, limit=12, label_name="avg_chroma")
)
```
On peut faire de même avec les affiches au chroma moyen le plus
faible. Beaucoup d'affiches ont un chroma moyen égal à zéro. Pouvez-
vous deviner ce qu'elles ont toutes en commun avant de regarder les
exemples ?
```{python}
(
posters
.sort(c.avg_chroma, descending=False)
.pipe(plot_image_grid, ncol=4, limit=12, label_name="avg_chroma")
)
```
Voyons comment le chroma moyen se rapporte aux genres associés à
chaque affiche. Étant donné qu'il y a un changement marqué de
luminosité durant les vingt premières années des données (beaucoup
étaient en noir et blanc), nous filtrerons les données après la fusion
avec les genres pour ne garder que les années à partir de 1990.
```{python}
(
posters
.filter(c.year >= 1990)
.join(genre, on=[c.year, c.title])
.group_by(c.genre)
.agg(avg_chroma = c.avg_chroma.mean())
.sort(c.avg_chroma)
.pipe(ggplot, aes("reorder(genre, avg_chroma)", "avg_chroma"))
+ geom_col()
+ coord_flip()
+ labs(x="Chroma", y="Genre")
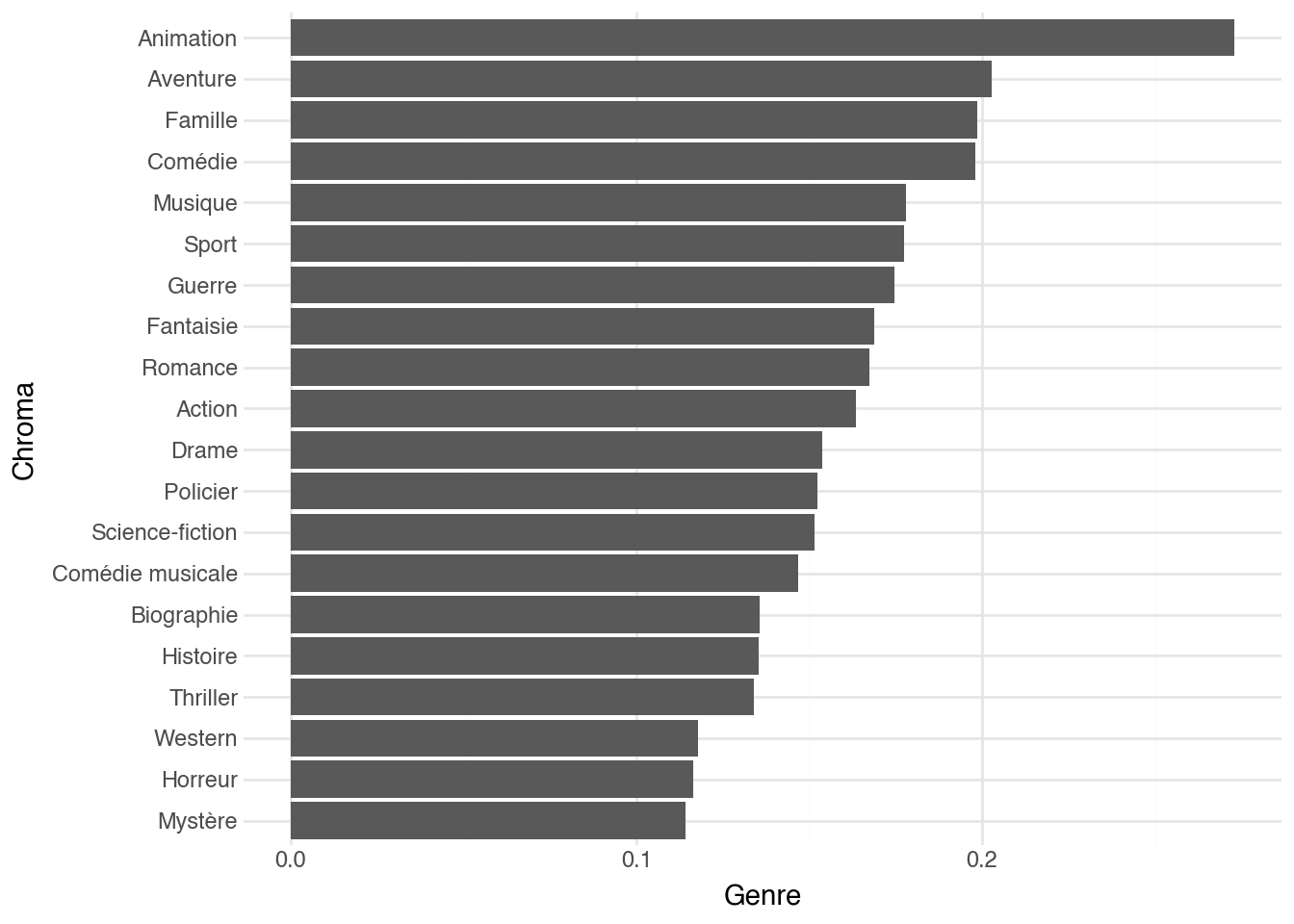
)
```
Prenez un moment pour examiner les résultats. Quels motifs remarquez-
vous ? Quelque chose vous paraît-il (i) particulièrement surprenant
ou (ii) particulièrement attendu ? Les deux types d'observations sont
utiles pour comprendre le lien entre les messages véhiculés par la
couleur de l'affiche et les genres associés.
## 1.7 Couleur dominante
Après avoir examiné la luminosité/valeur et la saturation/chroma des
affiches, nous passons au troisième élément de la couleur : la
**teinte** (hue). Pour commencer, prenons une autre affiche. Nous
allons charger celle du film *Take the Lead* (2006), qui contient
plusieurs teintes différentes.
```{python}
img = Image.open(
posters.filter(c.title == "Take the Lead")["filepath"][0]
)
img
```
Calculons maintenant les coordonnées HSV de cette image, comme dans
la section précédente. Nous réorganiserons aussi les données de
pixels pour que le tableau ait une ligne par pixel et seulement trois
colonnes. C'est une simple réorganisation qui simplifiera la suite du
code.
```{python}
arr = np.asarray(img)
arr_hsv = cv2.cvtColor(arr, cv2.COLOR_RGB2HSV)
arr_hsv = arr_hsv.astype(np.float64)
arr_hsv[:, :, 0] = arr_hsv[:, :, 0] / 179.0
arr_hsv[:, :, 1] = arr_hsv[:, :, 1] / 255.0
arr_hsv[:, :, 2] = arr_hsv[:, :, 2] / 255.0
arr_hsv = arr_hsv.reshape((-1, 3), order = "F")
arr_hsv.shape
```
La teinte est un nombre entre 0 et 1 qui désigne ce que l'on appelle
familièrement la « couleur ». Contrairement à la luminosité, à la
saturation, au chroma et à la valeur, ces nombres se conçoivent mieux
disposés en cercle (voir les diapositives associées pour une
visualisation). Une valeur de `0` correspond au rouge, `0,33` au
vert, `0,5` au cyan, et `0,66` au bleu. Les valeurs proches de 1
rebouclent par le violet et reviennent vers le rouge. Ainsi, les
teintes `0,01` et `0,99` sont en réalité très proches.
Pour mieux comprendre, regardons un histogramme de la distribution
des teintes dans l'image. Attention toutefois : l'interprétation de
la teinte n'est valable que si le chroma est suffisamment élevé. Si
le chroma est faible, il y a peu de couleur de toute façon, et les
différences entre teintes peuvent être difficiles, voire impossibles,
à distinguer. Dans le code ci-dessous, nous affichons la distribution
des teintes pour un chroma supérieur à `0,3`.
```{python}
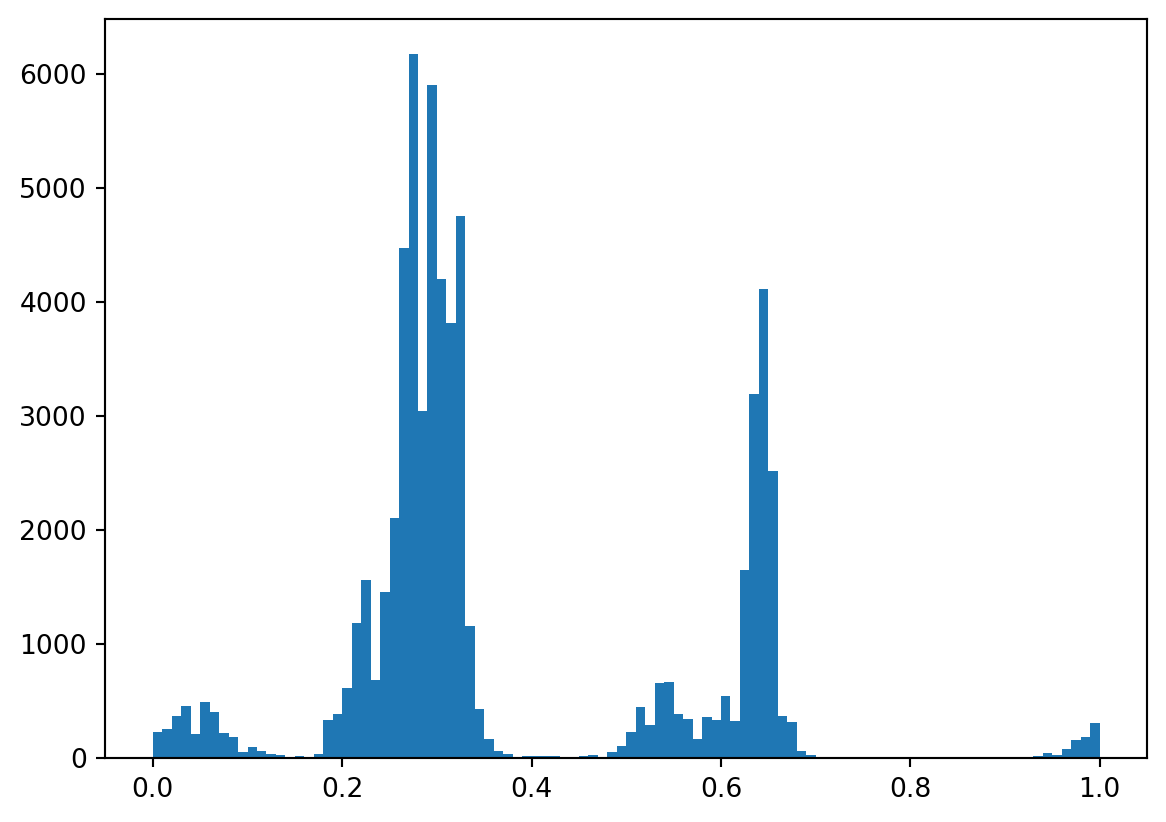
plt.hist(arr_hsv[arr_hsv[:,1] * arr_hsv[:,2] > 0.3, 0], bins=100)
plt.show()
```
On devrait voir beaucoup de valeurs autour de `0,3` ; elles
correspondent au vert de l'affiche, qui occupe beaucoup de place dans
l'image. Le pic près de `0,66` est associé au bleu, principalement
sur les silhouettes des deux personnages. La plus petite zone près de
1, et qui reboucle à 1, correspond au orange/rouge du titre du film.
Calculer la moyenne des teintes ne fournit généralement pas de
résumés significatifs. Exemple extrême : la moyenne de deux nuances
de rouge ayant des teintes de `0,99` et `0,01` donnerait `0,5`, soit
du cyan, une couleur située directement entre le vert et le bleu. À
la place, on peut créer une annotation de teinte en découpant
l'éventail des teintes en noms de couleurs standard, puis en
comptant la proportion de chaque affiche correspondant à chaque
couleur. Pour cela, nous chargeons un autre jeu de données contenant
les seuils que nous avons définis pour chaque teinte.
```{python}
hue = pl.read_csv("data/movies_50_years_hue.csv")
hue
```
Ensuite, nous reprenons les teintes de `arr_hsv` et comptons les
pixels présents dans chacune de ces tranches, après filtrage pour ne
garder qu'un chroma suffisamment élevé pour avoir une teinte
significative.
```{python}
bins = np.append(0, hue['end'].to_numpy())
cnt, _ = np.histogram(
arr_hsv[(arr_hsv[:,1] * arr_hsv[:,2] > 0.3), 0], bins = bins
)
cnt[0] = cnt[0] + cnt[7]
cnt = cnt[:7]
cnt
```
Il y a plusieurs façons de résumer ces décomptes. Nous en tirerons
deux annotations. D'abord, nous associons à chaque affiche une
couleur dominante, correspondant à la teinte la plus représentée. On
le fait avec le code suivant. On voit que le code associe l'affiche
de *Take the Lead* à la couleur verte, comme l'histogramme le
laissait prévoir.
```{python}
hue["cnom"].to_numpy()[np.argmax(cnt)]
```
L'autre quantité utile à conserver est la proportion de l'affiche
correspondant à cette couleur dominante. Avec le code ci-dessous, on
voit que plus de 42 % de cette affiche correspond aux teintes
classées comme « vertes ».
```{python}
color_percent = np.max(cnt) / arr_hsv.shape[0] * 100
color_percent
```
Maintenant que nous savons faire cela sur une seule image, parcourons
toutes les affiches et calculons le nom de la couleur dominante ainsi
que le pourcentage de l'affiche correspondant à chaque couleur pour
chacune d'elles.
```{python}
results = []
results_percent = []
for row in posters.iter_rows(named=True):
arr = np.asarray(Image.open(row["filepath"]))
arr_hsv = cv2.cvtColor(arr, cv2.COLOR_RGB2HSV)
arr_hsv = arr_hsv.astype(np.float64)
arr_hsv[:, :, 0] = arr_hsv[:, :, 0] / 179.0
arr_hsv[:, :, 1] = arr_hsv[:, :, 1] / 255.0
arr_hsv[:, :, 2] = arr_hsv[:, :, 2] / 255.0
arr_hsv = arr_hsv.reshape((-1, 3), order = "F")
bins = np.append(0, hue["end"].to_numpy())
cnt, _ = np.histogram(
arr_hsv[(arr_hsv[:,1] * arr_hsv[:,2] > 0.3), 0], bins = bins
)
cnt[0] = cnt[0] + cnt[7]
cnt = cnt[:7]
results.append(hue["cnom"].to_numpy()[np.argmax(cnt)])
results_percent.append(np.max(cnt) / arr_hsv.shape[0] * 100)
posters = posters.with_columns(
dom_color = pl.Series(results),
dom_color_percent = pl.Series(results_percent).round(4)
)
```
Comme pour les deux autres annotations, on peut commencer par
regarder les affiches qui ont la plus grande proportion de couleur
dominante pour chaque teinte. Voici par exemple le code pour afficher
l'image avec la plus grande quantité de bleu. Essayez de modifier le
code pour voir d'autres couleurs comme « rouge », « jaune » ou
« vert ».
```{python}
(
posters
.filter(c.dom_color == "bleu")
.sort(c.dom_color_percent, descending=True)
.pipe(plot_image_grid, ncol=4, limit=12, label_name="avg_chroma")
)
```
Faisons maintenant un peu d'analyse avec ces annotations. Nous
fusionnerons à nouveau les données de genre avec les annotations.
Nous ne considérerons aussi que les affiches dont la couleur dominante
sélectionnée représente au moins 5 %. On peut alors calculer la
proportion d'affiches de chaque genre ayant le rouge comme couleur
dominante avec le code suivant.
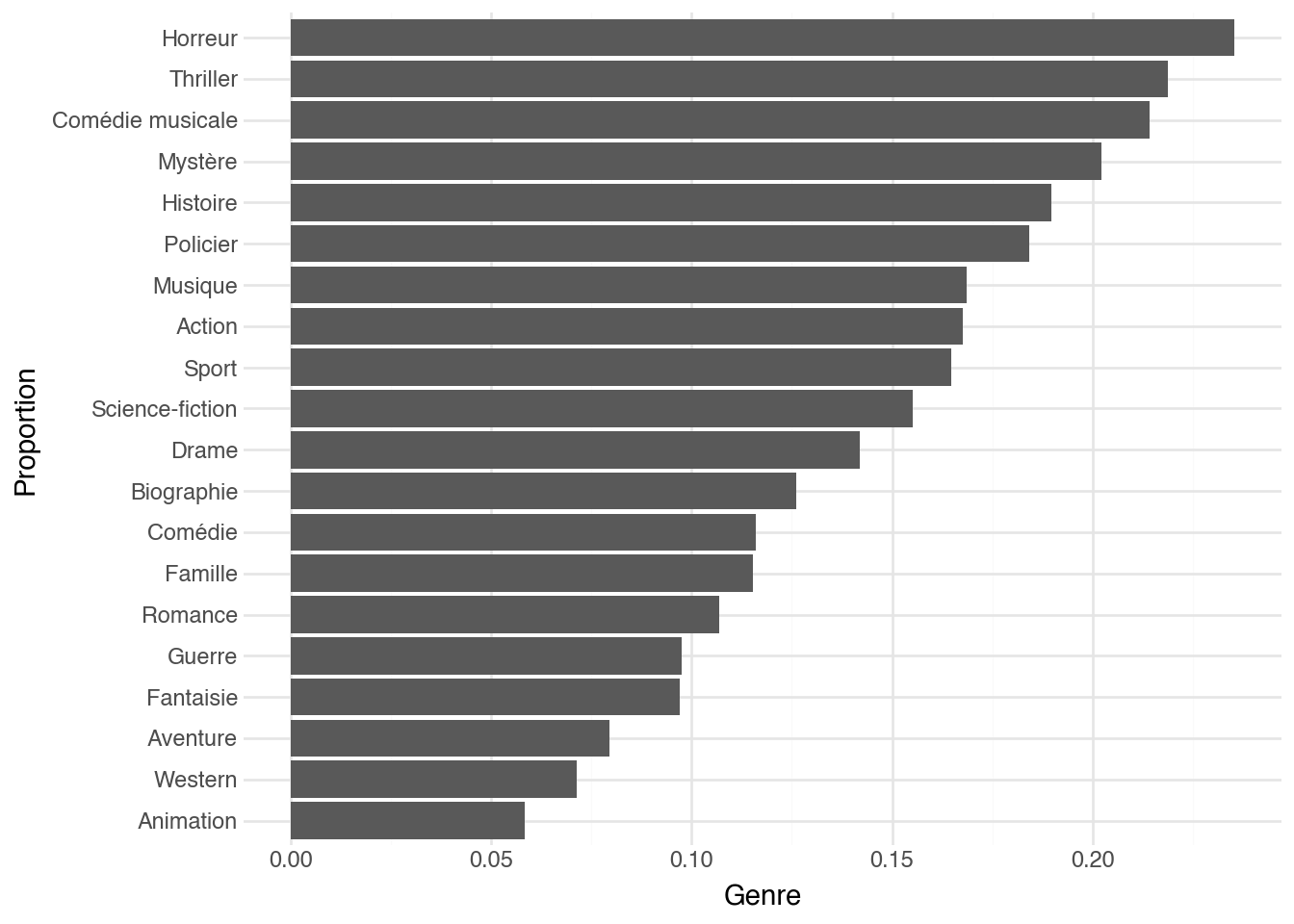
```{python}
(
posters
.join(genre, on=[c.year, c.title])
.filter(c.dom_color_percent > 5)
.group_by(c.genre)
.agg(prop_color = (c.dom_color == "rouge").mean())
.sort(c.prop_color)
.pipe(ggplot, aes("reorder(genre, prop_color)", "prop_color"))
+ geom_col()
+ coord_flip()
+ labs(x="Proportion", y="Genre")
)
```
Voyez-vous des motifs intéressants dans les données ci-dessus ? Après
les avoir examinées de près, essayez de changer la couleur d'intérêt
pour voir si d'autres motifs apparaissent.
## 1.8 Conclusion et prochaines étapes
Ce tutoriel a couvert beaucoup de matière. Nous avons présenté les
bases de Python ainsi qu'une compréhension de la façon dont les
images numériques sont représentées comme des tableaux d'intensités
de pixels. À partir de là, nous avons posé les enjeux théoriques du
distant viewing. Puis nous l'avons mis en pratique en générant des
annotations de plus en plus complexes fondées sur notre compréhension
de la couleur, et enfin en utilisant un algorithme d'apprentissage
automatique à base de réseaux de neurones pour détecter les visages
présents sur chaque affiche. Tout au long, nous avons cherché à
relier chacune de nos analyses à des questions de recherche portant
sur les cultures visuelles autour des affiches de films, à travers
différents genres et sur une période de 50 ans.
Il y a de nombreuses directions à explorer après ce notebook. Si vous
souhaitez voir comment mener à bien l'analyse présentée ici, y
compris l'étape importante de la mise en relation des observations
avec les sources d'archives et savantes existantes, nous vous
suggérons de consulter le chapitre 3 de notre livre *Distant
Viewing*. Un lien est disponible en haut de ce notebook. Si vous
débutez en programmation, apprendre [un peu plus de
Python](https://wiki.python.org/moin/BeginnersGuide) à partir des
principes de base est un bon point de départ. Si les images animées
vous intéressent, nous proposons un notebook de suivi qui parcourt
un exemple à partir d'un ensemble d'émissions de télévision
américaines des années 1960 et 1970. Sinon, nous vous invitons à
explorer les autres annotations disponibles dans le [distant viewing
toolkit](https://github.com/distant-viewing/dvt) et à les appliquer à
vos propres collections.
Merci de prendre le temps de nous lire, et n'hésitez pas à nous
faire part de vos retours !