# Tutoriel Distant Viewing 2 : Modèles avancés
[[**diapositives**](https://raw.githubusercontent.com/taylor-arnold/atelier/refs/heads/main/2026_dv/slides/tutoriel02.pdf)]
[[**site web**](https://www.distantviewing.org)]
Ce second notebook prolonge l'introduction du premier en passant à une
nouvelle famille d'outils : les modèles de vision par ordinateur
fondés sur l'apprentissage profond. Là où le premier tutoriel
construisait des annotations à partir d'opérations relativement
simples sur les pixels (luminosité, chroma, teinte dominante), nous
allons maintenant utiliser des réseaux de neurones pré-entraînés
capables de produire des annotations beaucoup plus riches : détection
d'objets, segmentation, lecture de texte, estimation de profondeur,
reconnaissance de visages, estimation de pose, et même description
des images en langage naturel via des modèles de vision-langage (VLM).
Le fil conducteur reste le même : nous travaillons sur notre
collection d'affiches de films de 1970 à 2019, et chaque annotation
est conçue pour répondre, au moins partiellement, à une question de
recherche sur la composition visuelle de ces affiches. La théorie du
distant viewing s'applique exactement comme avant : ces nouveaux
modèles, malgré leur puissance, restent des constructeurs
d'annotations destructives et non neutres. Plus un modèle est
sophistiqué, plus il est tentant d'oublier les choix qu'il
incorpore — choix de données d'entraînement, choix d'étiquettes,
choix d'architecture. Nous gardons donc, tout au long du notebook,
l'habitude de revenir aux images originales pour comparer les sorties
des modèles à notre propre interprétation.
Voici les objectifs d'apprentissage de ce second tutoriel :
1. Appliquer un modèle de détection d'objets pré-entraîné à une
collection d'images.
2. Utiliser un modèle de détection à vocabulaire ouvert (zero-shot)
pour repérer des objets décrits par du texte libre.
3. Combiner détection et reconnaissance optique de caractères pour
extraire le texte présent dans une image.
4. Produire des segmentations pixel par pixel à partir d'un point ou
d'une boîte de référence.
5. Estimer une carte de profondeur à partir d'une seule image.
6. Calculer des plongements vectoriels (embeddings) d'images pour
pouvoir les comparer, les regrouper ou les chercher.
7. Détecter et caractériser les visages.
8. Estimer la pose corporelle des personnages.
9. Interroger une image en langage naturel à l'aide d'un modèle de
vision-langage, avec ou sans sortie structurée.
Pour commencer, nous devons télécharger le jeu de données des affiches
de films, et indiquer à Python toutes les fonctions dont nous aurons
besoin par la suite.
```{python}
#| eval: false
!mkdir -p data
!mkdir -p cache
!mkdir -p /root/.cache/torch/hub/checkpoints/
!wget -q -nc -P data/ "https://distantviewing.org/atelier/movies_50_years_meta.csv"
!wget -q -nc -P data/ "https://distantviewing.org/atelier/movies_50_years_hue.csv"
!wget -q -nc -P data/ "https://distantviewing.org/atelier/movies_50_years_genre_fra.csv"
!wget -q -nc -P cache/ "https://distantviewing.org/atelier/posters_depth.parquet"
!wget -q -nc -P cache/ "https://distantviewing.org/atelier/posters_obj.parquet"
!wget -q -nc -P cache/ "https://distantviewing.org/atelier/posters_vlm_single.parquet"
!wget -q -nc -P cache/ "https://distantviewing.org/atelier/posters_dino.parquet"
!wget -q -nc -P cache/ "https://distantviewing.org/atelier/posters_pose.parquet"
!wget -q -nc -P cache/ "https://distantviewing.org/atelier/posters_vlm_struct_single.parquet"
!wget -q -nc -P cache/ "https://distantviewing.org/atelier/posters_face.parquet"
!wget -q -nc -P cache/ "https://distantviewing.org/atelier/posters_sam_gd.parquet"
!wget -q -nc -P cache/ "https://distantviewing.org/atelier/posters_vlm_struct.parquet"
!wget -q -nc -P cache/ "https://distantviewing.org/atelier/posters_gd_text.parquet"
!wget -q -nc -P cache/ "https://distantviewing.org/atelier/posters_vlm.parquet"
!wget -q -nc -P cache/ "https://distantviewing.org/atelier/posters_sam.parquet"
!wget -q -nc -P cache/ "https://distantviewing.org/atelier/posters_gd.parquet"
!wget -q -nc -P cache/ "https://distantviewing.org/atelier/posters_siglip.parquet"
!wget -q -nc "https://distantviewing.org/atelier/mp_med.tar"
!wget -q -nc "https://distantviewing.org/atelier/funs.py"
!tar -xf mp_med.tar --warning=no-unknown-keyword
!mv mp_med data
```
Quelques remarques techniques avant de commencer. Ce notebook utilise
la bibliothèque `transformers` de Hugging Face, qui donne accès à un
très grand nombre de modèles pré-entraînés via une interface uniforme.
La première fois qu'un modèle est chargé, ses poids sont téléchargés
et mis en cache localement, ce qui peut prendre du temps selon votre
connexion. Les exécutions suivantes seront beaucoup plus rapides. Si
une carte graphique compatible CUDA est disponible, les modèles
seront automatiquement exécutés dessus ; sinon, ils tourneront sur
CPU, ce qui reste possible mais nettement plus lent pour les modèles
les plus lourds.
```{python}
#| warning: false
import matplotlib.pyplot as plt
import matplotlib.patches as patches
import torch
import polars as pl
import numpy as np
import cv2
import os
from transformers import pipeline, utils
from PIL import Image
from polars import col as c
from funs import *
from plotnine import *
theme_set(theme_minimal())
device = "cuda" if torch.cuda.is_available() else "cpu"
utils.logging.set_verbosity_error()
utils.logging.disable_progress_bar()
```
La ligne `device = "cuda" if torch.cuda.is_available() else "cpu"`
détecte automatiquement la présence d'un GPU. Les deux dernières
lignes désactivent les messages d'avertissement et les barres de
progression de la bibliothèque `transformers`, simplement pour rendre
la sortie du notebook plus lisible.
## 2.1 Préparation des données
Nous repartons du même jeu de métadonnées que dans le premier
notebook. Chaque ligne correspond à un film, avec son année, son
titre, le chemin vers l'image de l'affiche, et la demi-décennie de
sortie.
```{python}
posters = pl.read_csv("data/movies_50_years_meta.csv")
posters
```
Nous disposons d'un autre ensemble de métadonnées qui associe chaque
film à une ou plusieurs catégories de genre. Le jeu de données contient
une ligne pour chaque paire film/étiquette de genre. L'année est
incluse parce que plusieurs films partagent le même titre, mais
peuvent être identifiés de manière unique en connaissant à la fois le
titre et l'année.
```{python}
genre = pl.read_csv("data/movies_50_years_genre_fra.csv")
genre
```
Un coup d'œil rapide à quelques affiches permet de garder en tête la
diversité visuelle de la collection : compositions très différentes,
nombres de personnages variables, présence ou absence de texte, époques
et genres distincts. C'est cette variété qui rendra les analyses
agrégées intéressantes.
```{python}
plot_image_grid(posters, ncol=4, limit=12)
```
Pour chacune des sections qui suivent, nous procéderons selon le même
schéma en quatre étapes : (1) charger un modèle pré-entraîné, (2)
l'appliquer à une affiche unique pour bien comprendre ce qu'il produit,
(3) visualiser le résultat, et (4) appliquer le modèle à l'ensemble
de la collection et stocker les annotations dans un fichier Parquet.
Le cache sur disque (les fichiers dans `cache/`) permet d'éviter de
relancer les modèles à chaque ouverture du notebook : si le fichier
existe déjà, on le relit directement.
## 2.2 Détection d'objets
Notre première annotation profonde sera une détection d'objets.
L'objectif est simple : pour chaque affiche, localiser les objets
présents et leur attribuer une étiquette tirée d'un vocabulaire
prédéfini. Nous utilisons ici DETR (Detection Transformer), un modèle
de détection de Facebook AI Research entraîné sur le jeu de données
COCO, qui couvre 80 catégories d'objets courants (personne, voiture,
chaise, etc.).
Première étape : charger le modèle et son processeur d'images. Le
processeur s'occupe des transformations nécessaires (redimensionnement,
normalisation) pour que l'image soit acceptée par le réseau.
```{python}
from transformers import AutoImageProcessor, AutoModelForObjectDetection
detr_processor = AutoImageProcessor.from_pretrained("facebook/detr-resnet-50")
detr_model = AutoModelForObjectDetection.from_pretrained("facebook/detr-resnet-50").to(device)
```
Nous sélectionnons ensuite une affiche pour expérimenter. Comme dans
le premier notebook, nous prendrons une affiche bien identifiable pour
suivre ce que fait le modèle.
```{python}
image_path = posters["filepath"][7]
image = Image.open(image_path).convert("RGB")
```
Nous appliquons maintenant le modèle. Le bloc `with torch.no_grad()`
indique à PyTorch que nous ne souhaitons pas calculer de gradients —
nous utilisons le modèle uniquement en inférence, ce qui économise de
la mémoire et accélère le calcul. Le post-traitement convertit les
sorties brutes du réseau en boîtes englobantes accompagnées de scores
de confiance et d'étiquettes. Nous fixons un seuil de `0.7` : seules
les détections dont le modèle est confiant à plus de 70 % sont
conservées.
```{python}
inputs = detr_processor(images=image, return_tensors="pt").to(device)
with torch.no_grad():
outputs = detr_model(**inputs)
results = detr_processor.post_process_object_detection(
outputs, target_sizes=torch.tensor([image.size[::-1]]), threshold=0.7
)[0]
boxes = results["boxes"].cpu().numpy()
label_ids = results["labels"].cpu().numpy()
df = pl.DataFrame({
"xmin": boxes[:, 0],
"ymin": boxes[:, 1],
"xmax": boxes[:, 2],
"ymax": boxes[:, 3],
"score": results["scores"].cpu().numpy(),
"label": [detr_model.config.id2label[i] for i in label_ids]
})
df
```
Chaque ligne du tableau correspond à un objet détecté, avec ses
coordonnées dans l'image (les quatre nombres définissent un rectangle),
son étiquette, et le score de confiance associé. Comme toujours, il
est essentiel de revenir à l'image pour vérifier que ces détections
correspondent à ce que nous voyons.
```{python}
unique_labels = df["label"].unique().to_list()
color_palette = plt.cm.tab10.colors
label_to_color = {label: color_palette[i % len(color_palette)] for i, label in enumerate(unique_labels)}
fig, ax = plt.subplots(1, 1, figsize=(5, 5))
ax.imshow(image)
for row in df.filter(c.score > 0.9).iter_rows(named=True):
x_min, y_min = row["xmin"], row["ymin"]
x_max, y_max = row["xmax"], row["ymax"]
label = row["label"]
score = row["score"]
color = label_to_color[label]
rect = patches.Rectangle(
(x_min, y_min),
x_max - x_min,
y_max - y_min,
linewidth=2.5,
edgecolor=color,
facecolor="none"
)
ax.add_patch(rect)
ax.text(
x_min,
y_min - 5,
f"{label}: {score:.2f}",
color="white",
fontsize=11,
bbox=dict(facecolor=color, edgecolor="none", pad=2)
)
ax.axis("off")
plt.tight_layout()
plt.show()
```
Quelques observations à garder à l'esprit. D'abord, le vocabulaire est
fermé : DETR ne sait reconnaître que les 80 catégories de COCO. Tout
ce qui sort de ce vocabulaire — un chapeau, un sabre laser, une
silhouette stylisée — sera soit ignoré, soit rattaché à la catégorie
la plus proche, parfois de manière surprenante. Ensuite, le modèle a
été entraîné sur des photographies du quotidien ; les affiches de
films, avec leurs compositions stylisées et leurs effets graphiques,
sortent partiellement de cette distribution. Certaines détections
seront donc moins fiables que d'autres, et le score de confiance reste
notre meilleur indicateur.
Appliquons maintenant le modèle à l'ensemble de la collection. Comme
ce traitement peut être long, nous mettons le résultat en cache. Si
le fichier existe déjà, nous le relisons ; sinon, nous parcourons les
affiches une par une.
```{python}
if os.path.exists("cache/posters_obj.parquet"):
posters_obj = pl.read_parquet("cache/posters_obj.parquet")
else:
all_dfs = []
for poster in posters.iter_rows(named=True):
img = Image.open(poster["filepath"]).convert("RGB")
inputs = detr_processor(images=img, return_tensors="pt").to(device)
with torch.no_grad():
outputs = detr_model(**inputs)
results = detr_processor.post_process_object_detection(
outputs, target_sizes=torch.tensor([img.size[::-1]]), threshold=0.7
)[0]
boxes = results["boxes"].cpu().numpy()
label_ids = results["labels"].cpu().numpy()
n = len(boxes)
all_dfs.append(pl.DataFrame({
"year": [poster["year"]] * n,
"title": [poster["title"]] * n,
"xmin": boxes[:, 0],
"ymin": boxes[:, 1],
"xmax": boxes[:, 2],
"ymax": boxes[:, 3],
"score": results["scores"].cpu().numpy(),
"label": [detr_model.config.id2label[i] for i in label_ids]
}))
posters_obj = pl.concat(all_dfs)
posters_obj.write_parquet("cache/posters_obj.parquet")
posters_obj
```
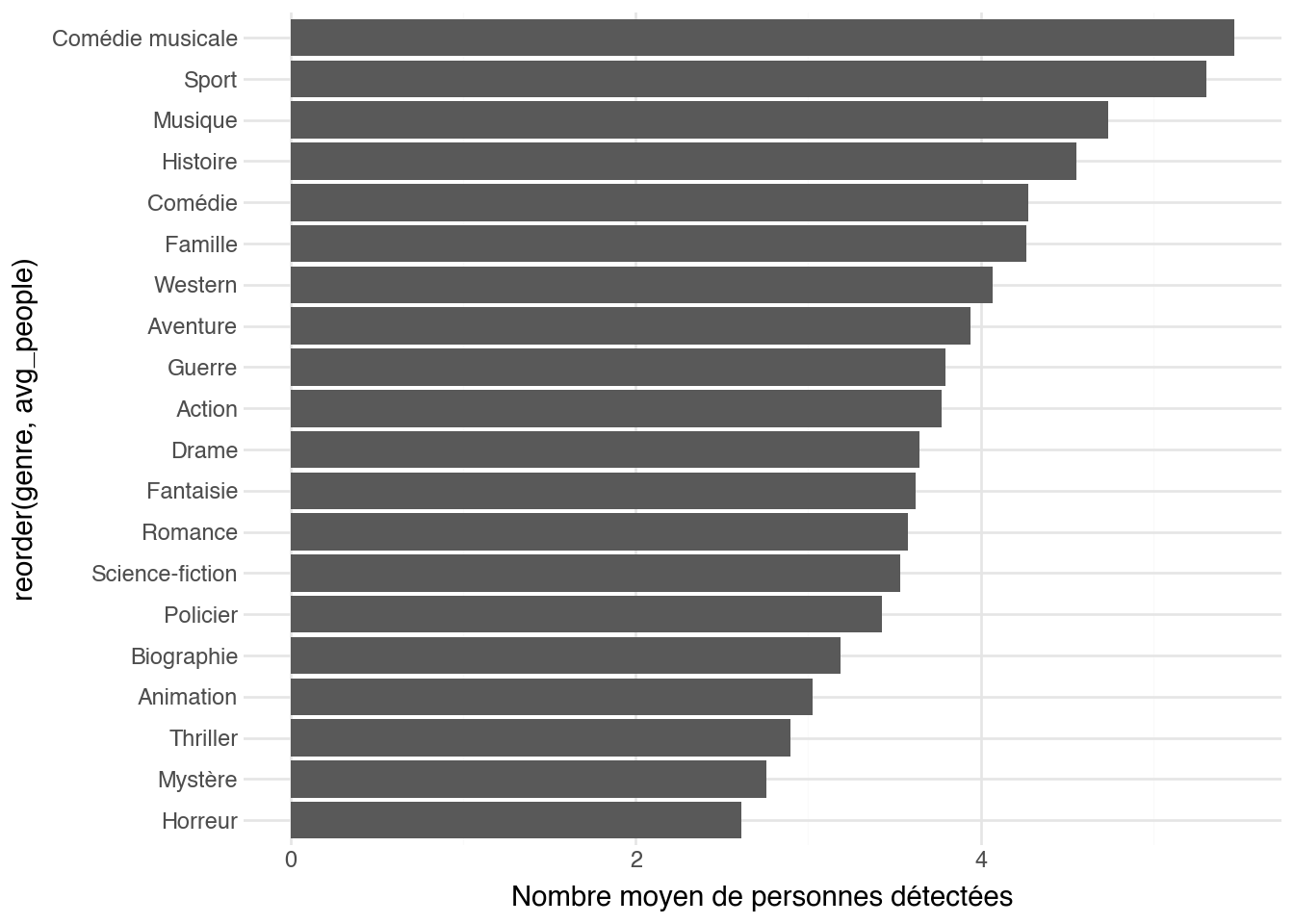
Nous avons maintenant, pour chaque film, la liste des objets détectés
sur son affiche. C'est une annotation très riche : on peut compter le
nombre de personnes par affiche, étudier l'évolution de certaines
catégories au fil du temps, ou comparer la présence d'objets entre
genres.
```{python}
(
posters_obj
.filter(c.label == "person")
.group_by(["year", "title"])
.agg(c.label.count().alias("n_people"))
.join(genre, on=["year", "title"])
.group_by("genre")
.agg(c.n_people.mean().alias("avg_people"))
.pipe(lambda df: (
ggplot(df, aes(x="reorder(genre, avg_people)", y="avg_people"))
+ geom_col()
+ coord_flip()
+ labs(x=None, y="Nombre moyen de personnes détectées")
))
)
```
## 2.3 Détection à vocabulaire ouvert : Grounding DINO
La limitation principale de DETR est son vocabulaire fixe. Que faire
si nous voulons détecter quelque chose qui ne fait pas partie de COCO,
comme un chapeau, un drapeau, ou une arme ? C'est ici qu'interviennent
les modèles dits *zero-shot*, capables de détecter n'importe quel
objet décrit par une phrase en langage naturel. Grounding DINO est
l'un des plus utilisés. On lui fournit une image *et* une description
textuelle de ce qu'on cherche, et il renvoie les régions de l'image
correspondant à cette description.
```{python}
from transformers import AutoProcessor, AutoModelForZeroShotObjectDetection
gd_processor = AutoProcessor.from_pretrained("IDEA-Research/grounding-dino-tiny")
gd_model = AutoModelForZeroShotObjectDetection.from_pretrained("IDEA-Research/grounding-dino-tiny").to(device)
```
La convention pour le prompt textuel est particulière : on liste les
catégories recherchées sous forme de phrases courtes terminées par un
point. Ici, nous cherchons un chapeau.
```{python}
image_path = posters["filepath"][7]
image = Image.open(image_path).convert("RGB")
text_prompt = "a hat."
```
Le code d'inférence est analogue à celui de DETR, à ceci près qu'on
passe désormais le texte au modèle en plus de l'image.
```{python}
inputs = gd_processor(images=image, text=text_prompt, return_tensors="pt").to(device)
with torch.no_grad():
outputs = gd_model(**inputs)
results = gd_processor.post_process_grounded_object_detection(
outputs,
inputs.input_ids,
text_threshold=0.3,
target_sizes=[image.size[::-1]],
)[0]
boxes = results["boxes"].cpu().numpy()
df = pl.DataFrame({
"xmin": boxes[:, 0],
"ymin": boxes[:, 1],
"xmax": boxes[:, 2],
"ymax": boxes[:, 3],
"score": results["scores"].cpu().numpy(),
"label": results["labels"]
})
df
```
Comme pour DETR, il est utile de superposer les boîtes détectées sur
l'image pour vérifier visuellement que les régions retournées par
Grounding DINO correspondent bien à ce que l'on cherchait.
```{python}
unique_labels = df["label"].unique().to_list()
color_palette = plt.cm.tab10.colors
label_to_color = {label: color_palette[i % len(color_palette)] for i, label in enumerate(unique_labels)}
fig, ax = plt.subplots(1, 1, figsize=(5, 5))
ax.imshow(image)
for row in df.iter_rows(named=True):
x_min, y_min = row["xmin"], row["ymin"]
x_max, y_max = row["xmax"], row["ymax"]
label = row["label"]
score = row["score"]
color = label_to_color[label]
rect = patches.Rectangle(
(x_min, y_min),
x_max - x_min,
y_max - y_min,
linewidth=2.5,
edgecolor=color,
facecolor="none"
)
ax.add_patch(rect)
ax.text(
x_min,
y_min - 5,
f"{label}: {score:.2f}",
color="white",
fontsize=11,
bbox=dict(facecolor=color, edgecolor="none", pad=2)
)
ax.axis("off")
plt.tight_layout()
plt.show()
```
L'intérêt pour la recherche est considérable : nous pouvons désormais
construire des annotations adaptées à nos questions, sans être
contraints par le vocabulaire d'un jeu de données préexistant. Cela
dit, la flexibilité a un coût. Les résultats dépendent fortement de
la formulation du prompt — « a hat » et « a cowboy hat » ne donnent
pas les mêmes détections — et la frontière entre concepts proches
peut être floue. Comme toujours, il faut valider les résultats sur
quelques exemples avant d'agréger.
```{python}
text_prompt = "a hat."
if os.path.exists("cache/posters_gd.parquet"):
posters_gd = pl.read_parquet("cache/posters_gd.parquet")
else:
all_dfs = []
for poster in posters.iter_rows(named=True):
img = Image.open(poster["filepath"]).convert("RGB")
inputs = gd_processor(images=img, text=text_prompt, return_tensors="pt").to(device)
with torch.no_grad():
outputs = gd_model(**inputs)
results = gd_processor.post_process_grounded_object_detection(
outputs, inputs.input_ids, text_threshold=0.3, target_sizes=[img.size[::-1]]
)[0]
boxes = results["boxes"].cpu().numpy()
labels = results["labels"]
n = min(len(boxes), len(labels))
if n == 0:
continue
all_dfs.append(pl.DataFrame({
"year": [poster["year"]] * n,
"title": [poster["title"]] * n,
"xmin": boxes[:n, 0],
"ymin": boxes[:n, 1],
"xmax": boxes[:n, 2],
"ymax": boxes[:n, 3],
"score": results["scores"].cpu().numpy()[:n],
"label": labels[:n]
}))
posters_gd = pl.concat(all_dfs) if all_dfs else pl.DataFrame(schema={"year": pl.Int32, "title": pl.String, "xmin": pl.Float32, "ymin": pl.Float32, "xmax": pl.Float32, "ymax": pl.Float32, "score": pl.Float32, "label": pl.String})
posters_gd.write_parquet("cache/posters_gd.parquet")
posters_gd
```
## 2.4 Grounding DINO + TrOCR : extraction du texte
Les affiches de films contiennent presque toujours du texte : titre,
nom des acteurs, slogan, mentions de production. Ce texte est un
élément central de la composition visuelle, et il porte une
information très différente de celle des images. Pour l'extraire,
nous combinons deux modèles : Grounding DINO pour localiser les
régions contenant du texte, puis TrOCR (Transformer-based OCR) de
Microsoft pour lire ce qui est écrit dans chaque région.
Cette approche en deux étapes — détecter puis reconnaître — est très
courante en vision par ordinateur. Elle a l'avantage de la modularité :
on peut remplacer chaque composant indépendamment, par exemple
utiliser un autre détecteur ou un autre moteur OCR.
```{python}
from transformers import AutoProcessor, AutoModelForZeroShotObjectDetection, TrOCRProcessor, VisionEncoderDecoderModel
gd_processor = AutoProcessor.from_pretrained("IDEA-Research/grounding-dino-tiny")
gd_model = AutoModelForZeroShotObjectDetection.from_pretrained("IDEA-Research/grounding-dino-tiny").to(device)
trocr_processor = TrOCRProcessor.from_pretrained("microsoft/trocr-base-printed")
trocr_model = VisionEncoderDecoderModel.from_pretrained("microsoft/trocr-base-printed").to(device)
```
```{python}
image_path = posters["filepath"][7]
image = Image.open(image_path).convert("RGB")
```
Pour la détection, nous demandons à Grounding DINO de repérer tout
ce qui ressemble à du texte. On peut formuler la requête de plusieurs
façons ; ici, nous combinons trois variantes pour augmenter le rappel.
Pour chaque région détectée, nous découpons l'image et passons le
résultat à TrOCR, qui produit la transcription.
```{python}
gd_inputs = gd_processor(images=image, text="text. word. letter.", return_tensors="pt").to(device)
with torch.no_grad():
gd_outputs = gd_model(**gd_inputs)
gd_results = gd_processor.post_process_grounded_object_detection(
gd_outputs, gd_inputs.input_ids,
text_threshold=0.2, target_sizes=[image.size[::-1]]
)[0]
text_boxes = gd_results["boxes"].cpu().numpy()
text_scores = gd_results["scores"].cpu().numpy()
recognized_texts = []
for box in text_boxes:
x1, y1, x2, y2 = [int(v) for v in box]
crop = image.crop((x1, y1, x2, y2))
pixel_values = trocr_processor(images=crop, return_tensors="pt").pixel_values.to(device)
with torch.no_grad():
gen_ids = trocr_model.generate(pixel_values, max_new_tokens=64)
text = trocr_processor.batch_decode(gen_ids, skip_special_tokens=True)[0]
recognized_texts.append(text)
df = pl.DataFrame({
"xmin": text_boxes[:, 0],
"ymin": text_boxes[:, 1],
"xmax": text_boxes[:, 2],
"ymax": text_boxes[:, 3],
"score": text_scores,
"text": recognized_texts
})
df
```
```{python}
colors = plt.cm.tab20.colors
fig, ax = plt.subplots(1, 1, figsize=(6, 6))
ax.imshow(image)
for i, row in enumerate(df.iter_rows(named=True)):
x1, y1, x2, y2 = row["xmin"], row["ymin"], row["xmax"], row["ymax"]
color = colors[i % len(colors)]
rect = patches.Rectangle((x1, y1), x2 - x1, y2 - y1, linewidth=2, edgecolor=color, facecolor="none")
ax.add_patch(rect)
label = f"{row['text'][:30]} ({row['score']:.2f})"
ax.text(x1, y1 - 5, label, color="white", fontsize=9, bbox=dict(facecolor=color, edgecolor="none", pad=2))
ax.set_title(f"Grounding DINO + TrOCR — {len(df)} text region(s)")
ax.axis("off")
plt.tight_layout()
plt.show()
```
L'OCR sur des affiches de films est un cas particulièrement difficile :
les typographies sont créatives, le texte est souvent stylisé, parfois
incliné ou intégré au graphisme. Les transcriptions ne seront donc pas
parfaites. Mais à l'échelle de la collection, elles permettent de
poser des questions intéressantes : quels mots reviennent le plus
souvent dans les titres ? Quelle est l'évolution de la quantité de
texte sur les affiches au fil des décennies ?
```{python}
if os.path.exists("cache/posters_gd_text.parquet"):
posters_gd_text = pl.read_parquet("cache/posters_gd_text.parquet")
else:
all_dfs = []
for poster in posters.iter_rows(named=True):
img = Image.open(poster["filepath"]).convert("RGB")
gd_inputs = gd_processor(images=img, text="text. word. letter.", return_tensors="pt").to(device)
with torch.no_grad():
gd_outputs = gd_model(**gd_inputs)
gd_results = gd_processor.post_process_grounded_object_detection(
gd_outputs, gd_inputs.input_ids, text_threshold=0.2, target_sizes=[img.size[::-1]]
)[0]
text_boxes = gd_results["boxes"].cpu().numpy()
text_scores = gd_results["scores"].cpu().numpy()
if len(text_boxes) == 0:
continue
recognized_texts = []
for box in text_boxes:
x1, y1, x2, y2 = [int(v) for v in box]
crop = img.crop((x1, y1, x2, y2))
pixel_values = trocr_processor(images=crop, return_tensors="pt").pixel_values.to(device)
with torch.no_grad():
gen_ids = trocr_model.generate(pixel_values, max_new_tokens=64)
recognized_texts.append(trocr_processor.batch_decode(gen_ids, skip_special_tokens=True)[0])
n = len(text_boxes)
all_dfs.append(pl.DataFrame({
"year": [poster["year"]] * n,
"title": [poster["title"]] * n,
"xmin": text_boxes[:, 0],
"ymin": text_boxes[:, 1],
"xmax": text_boxes[:, 2],
"ymax": text_boxes[:, 3],
"score": text_scores,
"text": recognized_texts
}))
posters_gd_text = pl.concat(all_dfs) if all_dfs else pl.DataFrame(schema={"year": pl.Int32, "title": pl.String, "xmin": pl.Float32, "ymin": pl.Float32, "xmax": pl.Float32, "ymax": pl.Float32, "score": pl.Float32, "text": pl.String})
posters_gd_text.write_parquet("cache/posters_gd_text.parquet")
posters_gd_text
```
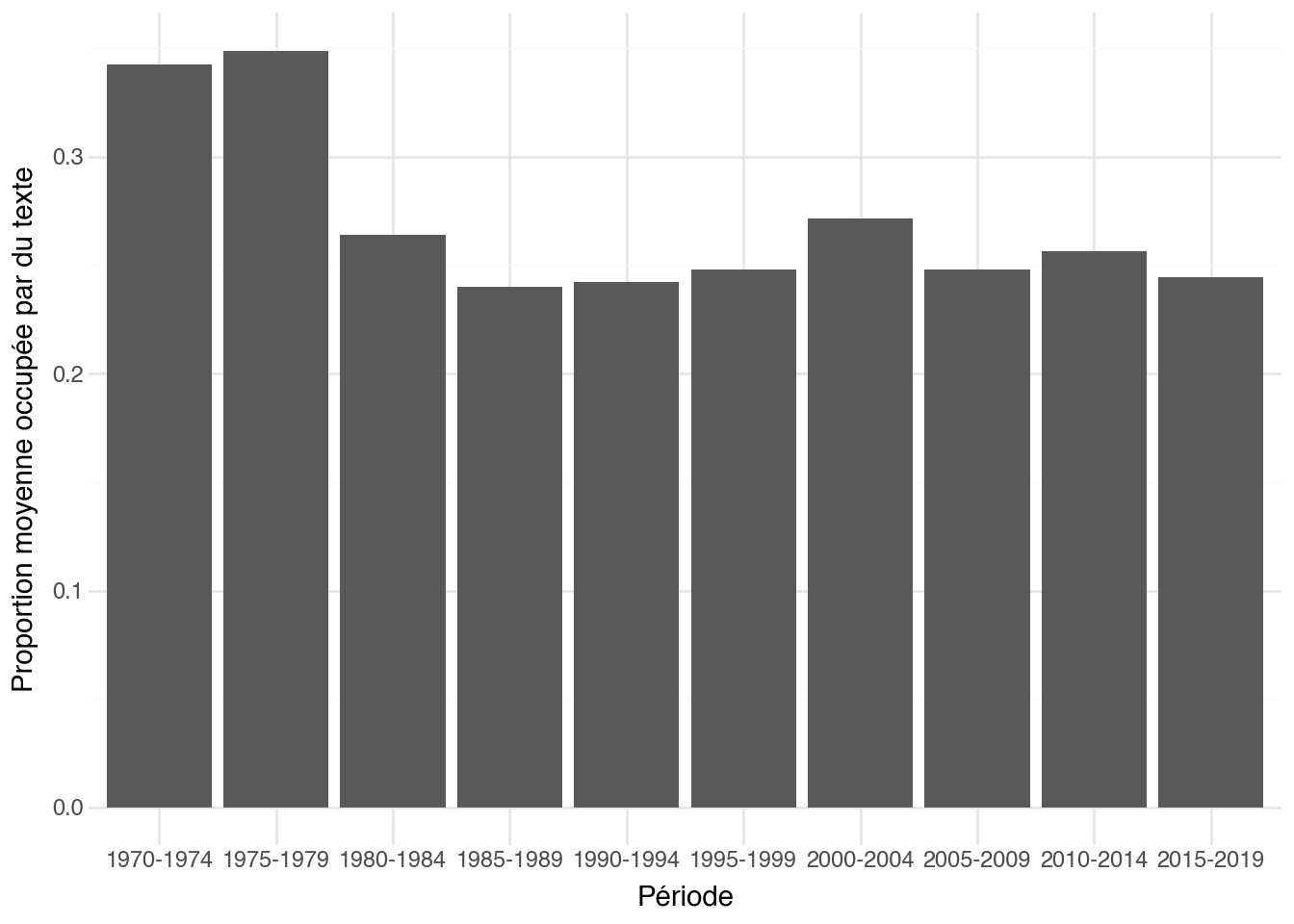
À titre d'illustration, on peut regarder comment la place occupée par
le texte sur les affiches évolue dans le temps : la composition
typographique d'une affiche est un indice de l'esthétique commerciale
d'une époque autant que des conventions de chaque genre.
```{python}
(
posters_gd_text
.with_columns(((c.xmax - c.xmin) * (c.ymax - c.ymin)).alias("box_area"))
.group_by(["year", "title"])
.agg(c.box_area.sum().alias("total_text_area"))
.join(
posters.with_columns(
pl.Series("img_area", [
Image.open(fp).size[0] * Image.open(fp).size[1]
for fp in posters["filepath"].to_list()
])
).select(["year", "title", "period", "img_area"]),
on=["year", "title"]
)
.with_columns((c.total_text_area / c.img_area).alias("text_frac"))
.group_by("period")
.agg(c.text_frac.mean().alias("avg_text_frac"))
.sort("period")
.pipe(lambda df: (
ggplot(df, aes(x="period", y="avg_text_frac"))
+ geom_col()
+ labs(x="Période", y="Proportion moyenne occupée par du texte")
))
)
```
## 2.5 Segment Anything : segmentation à partir d'un point
Les boîtes englobantes sont utiles, mais elles ne disent rien de la
forme exacte des objets. Une boîte autour d'un personnage inclut
forcément des pixels du fond. Pour aller plus loin, on utilise la
*segmentation*, qui consiste à classer chaque pixel comme appartenant
ou non à un objet d'intérêt.
Segment Anything (SAM), publié par Meta AI, est un modèle de
segmentation très général. Au lieu de prédire une classe pour chaque
pixel à partir d'un vocabulaire fixe, SAM accepte un *prompt* — un
point, une boîte, ou un masque approximatif — et renvoie le masque
précis correspondant. C'est extrêmement souple : nous pouvons
segmenter à peu près n'importe quoi, à condition de pouvoir le pointer.
```{python}
from transformers import SamModel, SamProcessor
sam_model = SamModel.from_pretrained("facebook/sam-vit-base").to(device)
sam_processor = SamProcessor.from_pretrained("facebook/sam-vit-base")
```
Nous choisissons une affiche et un point de référence, exprimé en
pourcentage de la largeur et de la hauteur. Travailler en pourcentage
rend le code robuste aux différentes tailles d'image.
```{python}
image_path = posters["filepath"][7]
image = Image.open(image_path).convert("RGB")
per_x = 60
per_y = 40
```
SAM renvoie en réalité plusieurs masques candidats par point, avec
un score de confiance pour chacun. Comme un masque pixel par pixel
ne se range pas commodément dans un tableau, nous résumons chaque
masque par sa proportion de la surface totale de l'image — une
statistique très utile pour comparer les segmentations à grande
échelle.
```{python}
point_x = int(image.size[0] * per_x / 100)
point_y = int(image.size[1] * per_y / 100)
inputs = sam_processor(image, input_points=[[[point_x, point_y]]], return_tensors="pt").to(device)
with torch.no_grad():
outputs = sam_model(**inputs)
masks = sam_processor.image_processor.post_process_masks(
outputs.pred_masks.cpu(), inputs["original_sizes"].cpu(), inputs["reshaped_input_sizes"].cpu()
)[0][0].numpy()
scores = outputs.iou_scores.cpu().numpy().squeeze()
total_pixels = masks.shape[1] * masks.shape[2]
df = pl.DataFrame({
"mask_id": list(range(1, len(masks) + 1)),
"iou_score": scores.tolist(),
"pixel_count": [int(mask.sum()) for mask in masks],
"proportion": [float(mask.sum()) / total_pixels for mask in masks]
})
df
```
```{python}
fig, axes = plt.subplots(1, len(masks) + 1, figsize=(5 * (len(masks) + 1), 5))
axes[0].imshow(image)
axes[0].scatter([point_x], [point_y], color="lime", marker="*", s=250, edgecolor="black", linewidth=1.5, zorder=5)
axes[0].set_title(f"Input image (point at {per_x}%, {per_y}%)")
axes[0].axis("off")
for i, (mask, score) in enumerate(zip(masks, scores)):
axes[i + 1].imshow(image)
overlay = np.zeros((*mask.shape, 4))
overlay[mask] = [1, 0, 0, 0.5]
axes[i + 1].imshow(overlay)
axes[i + 1].scatter([point_x], [point_y], color="lime", marker="*", s=250, edgecolor="black", linewidth=1.5, zorder=5)
axes[i + 1].set_title(f"Mask {i+1}, score: {score:.3f}")
axes[i + 1].axis("off")
plt.tight_layout()
plt.show()
```
Les trois masques renvoyés correspondent à différents niveaux de
granularité — typiquement, un masque très local autour du point, un
masque intermédiaire, et un masque englobant. C'est à nous de choisir
celui qui correspond à notre question de recherche. Cette ambiguïté
est précisément un exemple de la « non-neutralité » dont parle la
théorie du distant viewing : il n'y a pas de bon masque dans
l'absolu, il y a un masque adapté à un usage.
```{python}
per_x = 50
per_y = 50
if os.path.exists("cache/posters_sam.parquet"):
posters_sam = pl.read_parquet("cache/posters_sam.parquet")
else:
all_dfs = []
for poster in posters.iter_rows(named=True):
img = Image.open(poster["filepath"]).convert("RGB")
px = int(img.size[0] * per_x / 100)
py = int(img.size[1] * per_y / 100)
inputs = sam_processor(img, input_points=[[[px, py]]], return_tensors="pt").to(device)
with torch.no_grad():
outputs = sam_model(**inputs)
masks = sam_processor.image_processor.post_process_masks(
outputs.pred_masks.cpu(), inputs["original_sizes"].cpu(), inputs["reshaped_input_sizes"].cpu()
)[0][0].numpy()
iou_scores = outputs.iou_scores.cpu().numpy().squeeze()
total_pixels = masks.shape[1] * masks.shape[2]
n = len(masks)
all_dfs.append(pl.DataFrame({
"year": [poster["year"]] * n,
"title": [poster["title"]] * n,
"mask_id": list(range(1, n + 1)),
"iou_score": iou_scores.tolist(),
"pixel_count": [int(mask.sum()) for mask in masks],
"proportion": [float(mask.sum()) / total_pixels for mask in masks]
}))
posters_sam = pl.concat(all_dfs)
posters_sam.write_parquet("cache/posters_sam.parquet")
posters_sam
```
## 2.6 SAM + Grounding DINO : segmentation guidée par texte
Pointer un endroit précis sur chaque affiche n'a pas toujours de sens
à l'échelle d'une collection : la position d'un personnage varie
d'une affiche à l'autre. Pour automatiser, on combine deux modèles :
Grounding DINO détecte d'abord les régions correspondant à un concept
exprimé en langage naturel, puis SAM raffine la segmentation à
l'intérieur de chaque boîte. Le résultat est une segmentation pilotée
par texte, sans intervention manuelle.
```{python}
from transformers import SamModel, SamProcessor, AutoProcessor, AutoModelForZeroShotObjectDetection
gd_processor = AutoProcessor.from_pretrained("IDEA-Research/grounding-dino-tiny")
gd_model = AutoModelForZeroShotObjectDetection.from_pretrained("IDEA-Research/grounding-dino-tiny").to(device)
sam_model = SamModel.from_pretrained("facebook/sam-vit-base").to(device)
sam_processor = SamProcessor.from_pretrained("facebook/sam-vit-base")
```
Le prompt que nous donnons définit ce que nous cherchons. Ici, nous
voulons segmenter les personnages.
```{python}
image_path = posters["filepath"][7]
image = Image.open(image_path).convert("RGB")
text_prompt = "a person."
```
Le pipeline applique d'abord Grounding DINO pour obtenir les boîtes,
puis passe ces boîtes à SAM pour obtenir les masques fins. Comme
précédemment, nous résumons chaque masque par sa proportion de
l'image.
```{python}
gd_inputs = gd_processor(images=image, text=text_prompt, return_tensors="pt").to(device)
with torch.no_grad():
gd_outputs = gd_model(**gd_inputs)
gd_results = gd_processor.post_process_grounded_object_detection(
gd_outputs,
gd_inputs.input_ids,
text_threshold=0.3,
target_sizes=[image.size[::-1]],
)[0]
gd_boxes = gd_results["boxes"].cpu().numpy()
gd_scores = gd_results["scores"].cpu().numpy()
gd_labels = gd_results["labels"]
sam_inputs = sam_processor(image, input_boxes=[gd_boxes.tolist()], return_tensors="pt").to(device)
with torch.no_grad():
sam_outputs = sam_model(**sam_inputs, multimask_output=False)
sam_masks = sam_processor.image_processor.post_process_masks(
sam_outputs.pred_masks.cpu(), sam_inputs["original_sizes"].cpu(), sam_inputs["reshaped_input_sizes"].cpu()
)[0].numpy().squeeze(1)
total_pixels = image.size[0] * image.size[1]
df = pl.DataFrame({
"label": gd_labels,
"score": gd_scores,
"xmin": gd_boxes[:, 0],
"ymin": gd_boxes[:, 1],
"xmax": gd_boxes[:, 2],
"ymax": gd_boxes[:, 3],
"pixel_count": [int(mask.sum()) for mask in sam_masks],
"proportion": [float(mask.sum()) / total_pixels for mask in sam_masks]
})
df
```
```{python}
colors = plt.cm.tab20.colors
fig, ax = plt.subplots(1, 1, figsize=(5, 5))
ax.imshow(image)
for i, row in enumerate(df.iter_rows(named=True)):
color = colors[i % len(colors)]
mask = sam_masks[i]
overlay = np.zeros((*mask.shape, 4))
overlay[mask.astype(bool)] = [*color[:3], 0.5]
ax.imshow(overlay)
x_min, y_min = row["xmin"], row["ymin"]
x_max, y_max = row["xmax"], row["ymax"]
rect = patches.Rectangle(
(x_min, y_min), x_max - x_min, y_max - y_min,
linewidth=2, edgecolor=color, facecolor="none", linestyle="--"
)
ax.add_patch(rect)
ax.text(
x_min, y_min - 5,
f"{row['label']}: {row['score']:.2f}",
color="white", fontsize=11,
bbox=dict(facecolor=color, edgecolor="none", pad=2)
)
ax.set_title(f"Grounding DINO + SAM: '{text_prompt}'")
ax.axis("off")
plt.tight_layout()
plt.show()
```
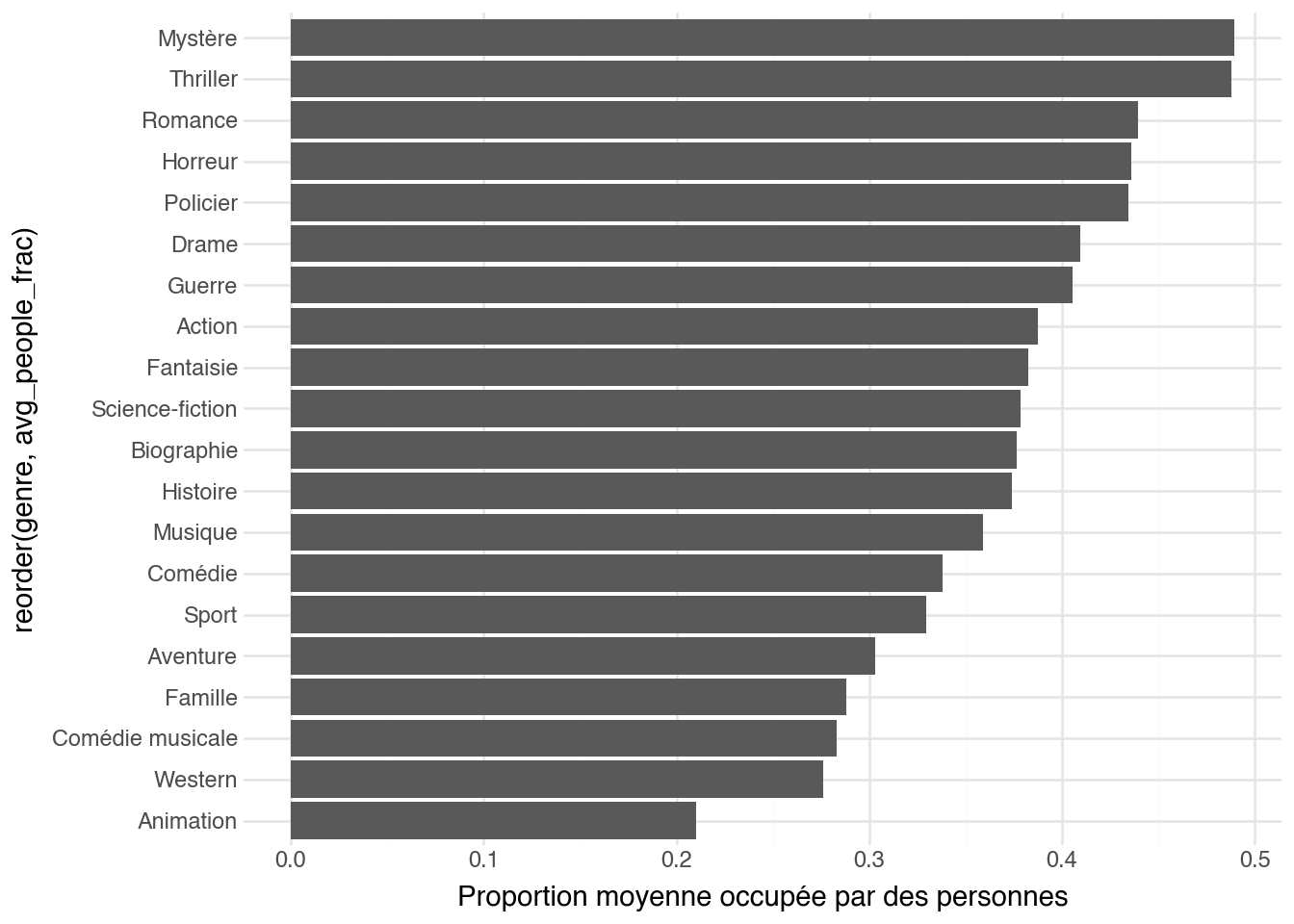
Cette annotation est particulièrement utile pour mesurer la
*proportion d'écran* occupée par un concept : quelle part de
l'affiche est occupée par des personnages ? Cette proportion
évolue-t-elle au fil des décennies ou diffère-t-elle selon le genre ?
Ces questions, difficiles à aborder avec de simples boîtes
englobantes, deviennent accessibles dès qu'on dispose de masques.
```{python}
text_prompt = "a person."
if os.path.exists("cache/posters_sam_gd.parquet"):
posters_sam_gd = pl.read_parquet("cache/posters_sam_gd.parquet")
else:
all_dfs = []
for poster in posters.iter_rows(named=True):
print(poster)
img = Image.open(poster["filepath"]).convert("RGB")
gd_inputs = gd_processor(images=img, text=text_prompt, return_tensors="pt").to(device)
with torch.no_grad():
gd_outputs = gd_model(**gd_inputs)
gd_results = gd_processor.post_process_grounded_object_detection(
gd_outputs, gd_inputs.input_ids, text_threshold=0.3, target_sizes=[img.size[::-1]]
)[0]
gd_boxes = gd_results["boxes"].cpu().numpy()
gd_scores = gd_results["scores"].cpu().numpy()
gd_labels = gd_results["labels"]
if len(gd_boxes) == 0:
continue
sam_inputs = sam_processor(img, input_boxes=[gd_boxes.tolist()], return_tensors="pt").to(device)
with torch.no_grad():
sam_outputs = sam_model(**sam_inputs, multimask_output=False)
sam_masks = sam_processor.image_processor.post_process_masks(
sam_outputs.pred_masks.cpu(), sam_inputs["original_sizes"].cpu(), sam_inputs["reshaped_input_sizes"].cpu()
)[0].numpy().squeeze(1)
total_pixels = img.size[0] * img.size[1]
n = len(gd_boxes)
all_dfs.append(pl.DataFrame({
"year": [poster["year"]] * n,
"title": [poster["title"]] * n,
"label": gd_labels,
"score": gd_scores,
"xmin": gd_boxes[:, 0],
"ymin": gd_boxes[:, 1],
"xmax": gd_boxes[:, 2],
"ymax": gd_boxes[:, 3],
"pixel_count": [int(mask.sum()) for mask in sam_masks],
"proportion": [float(mask.sum()) / total_pixels for mask in sam_masks]
}))
posters_sam_gd = pl.concat(all_dfs)
posters_sam_gd.write_parquet("cache/posters_sam_gd.parquet")
posters_sam_gd
```
Avec cette annotation, on peut comparer la place que chaque genre
accorde aux personnages dans la composition de ses affiches — un
proxy visuel intéressant pour distinguer les films centrés sur des
figures humaines de ceux qui mettent en avant des décors, des objets
ou des éléments graphiques.
```{python}
(
posters_sam_gd
.group_by(["year", "title"])
.agg(c.proportion.sum().alias("people_frac"))
.join(genre, on=["year", "title"])
.group_by("genre")
.agg(c.people_frac.mean().alias("avg_people_frac"))
.pipe(lambda df: (
ggplot(df, aes(x="reorder(genre, avg_people_frac)", y="avg_people_frac"))
+ geom_col()
+ coord_flip()
+ labs(x=None, y="Proportion moyenne occupée par des personnes")
))
)
```
## 2.7 Estimation de profondeur : Depth Anything
Une affiche est une image plate, mais elle représente presque toujours
une scène avec une certaine profondeur : un personnage au premier
plan, un paysage au fond. La profondeur perçue est un élément
important de la composition. Peut-on l'estimer automatiquement à
partir d'une seule image ?
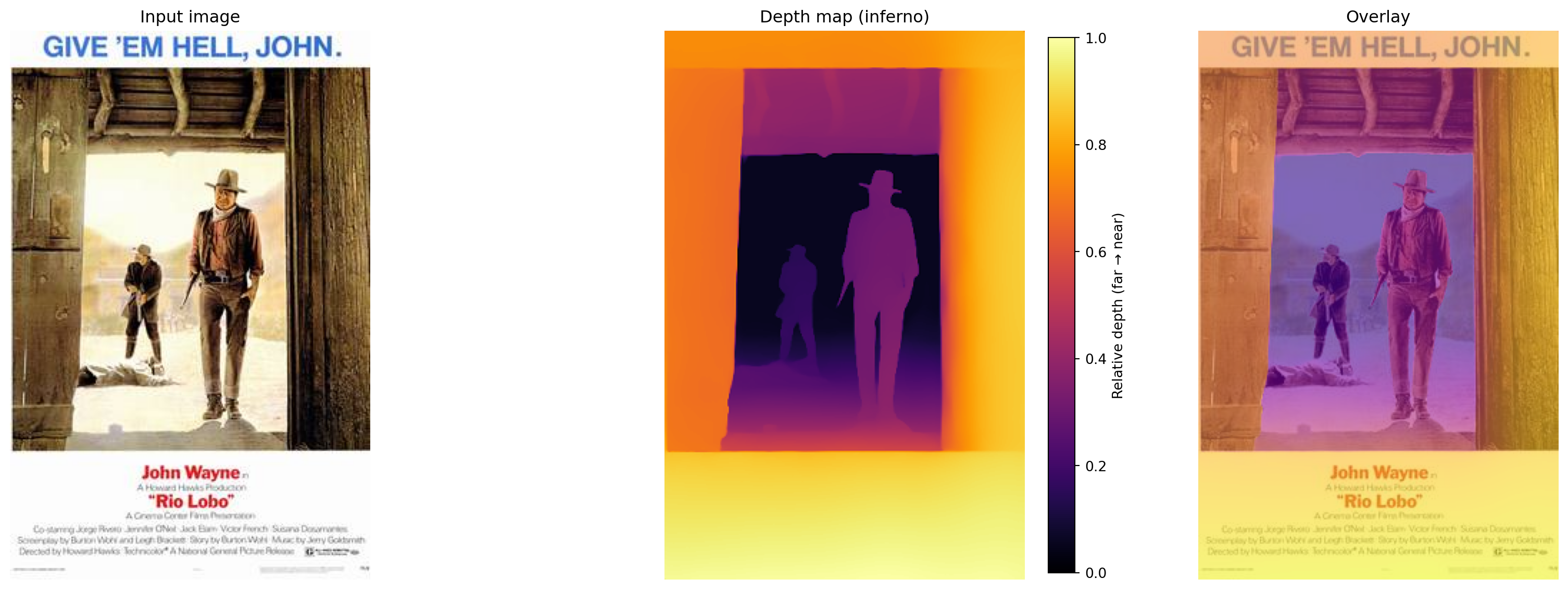
C'est exactement ce que fait Depth Anything : pour chaque pixel, le
modèle prédit une valeur de profondeur relative. On n'obtient pas une
mesure en mètres — c'est impossible sans information de calibration —
mais une carte de profondeur normalisée où les valeurs faibles
correspondent aux pixels proches et les valeurs élevées aux pixels
lointains.
```{python}
from transformers import AutoImageProcessor, AutoModelForDepthEstimation
depth_processor = AutoImageProcessor.from_pretrained("depth-anything/Depth-Anything-V2-Small-hf")
depth_model = AutoModelForDepthEstimation.from_pretrained("depth-anything/Depth-Anything-V2-Small-hf").to(device)
```
```{python}
image_path = posters["filepath"][7]
image = Image.open(image_path).convert("RGB")
```
La carte de profondeur complète contient une valeur par pixel — bien
trop pour une ligne de tableau. Nous la résumons en découpant les
profondeurs normalisées en dix intervalles d'égale largeur, et en
notant la proportion de l'image qui tombe dans chaque intervalle.
```{python}
inputs = depth_processor(images=image, return_tensors="pt").to(device)
with torch.no_grad():
outputs = depth_model(**inputs)
post_processed = depth_processor.post_process_depth_estimation(outputs, target_sizes=[image.size[::-1]])
depth = post_processed[0]["predicted_depth"].cpu().numpy()
depth_normalized = (depth - depth.min()) / (depth.max() - depth.min())
n_bins = 10
bin_edges = np.linspace(0, 1, n_bins + 1)
bin_labels = [f"{bin_edges[i]:.1f}–{bin_edges[i+1]:.1f}" for i in range(n_bins)]
pixel_counts = [
int(((depth_normalized >= bin_edges[i]) & (depth_normalized < bin_edges[i + 1])).sum())
for i in range(n_bins)
]
pixel_counts[-1] = int(((depth_normalized >= bin_edges[-2]) & (depth_normalized <= 1.0)).sum())
total_pixels = depth_normalized.size
df = pl.DataFrame({
"depth_range": bin_labels,
"pixel_count": pixel_counts,
"proportion": [pc / total_pixels for pc in pixel_counts]
})
df
```
```{python}
fig, axes = plt.subplots(1, 3, figsize=(18, 6))
axes[0].imshow(image)
axes[0].set_title("Input image")
axes[0].axis("off")
im1 = axes[1].imshow(depth_normalized, cmap="inferno")
axes[1].set_title("Depth map (inferno)")
axes[1].axis("off")
plt.colorbar(im1, ax=axes[1], fraction=0.046, pad=0.04, label="Relative depth (far → near)")
axes[2].imshow(image)
axes[2].imshow(depth_normalized, cmap="plasma", alpha=0.6)
axes[2].set_title("Overlay")
axes[2].axis("off")
plt.tight_layout()
plt.show()
```
Une carte de profondeur, même approximative, ouvre tout un éventail
de questions : les affiches contemporaines mobilisent-elles plus la
profondeur que les anciennes ? Les genres se distinguent-ils par leur
usage du premier plan et du fond ? Une comédie privilégie-t-elle des
compositions « plates » et des fonds neutres, là où un film d'action
joue davantage avec la profondeur ?
```{python}
if os.path.exists("cache/posters_depth.parquet"):
posters_depth = pl.read_parquet("cache/posters_depth.parquet")
else:
all_dfs = []
n_bins = 10
bin_edges = np.linspace(0, 1, n_bins + 1)
bin_labels = [f"{bin_edges[i]:.1f}–{bin_edges[i+1]:.1f}" for i in range(n_bins)]
for poster in posters.iter_rows(named=True):
img = Image.open(poster["filepath"]).convert("RGB")
inputs = depth_processor(images=img, return_tensors="pt").to(device)
with torch.no_grad():
outputs = depth_model(**inputs)
post_processed = depth_processor.post_process_depth_estimation(outputs, target_sizes=[img.size[::-1]])
depth = post_processed[0]["predicted_depth"].cpu().numpy()
depth_norm = (depth - depth.min()) / (depth.max() - depth.min())
pixel_counts = [
int(((depth_norm >= bin_edges[i]) & (depth_norm < bin_edges[i + 1])).sum())
for i in range(n_bins)
]
pixel_counts[-1] = int(((depth_norm >= bin_edges[-2]) & (depth_norm <= 1.0)).sum())
total_pixels = depth_norm.size
all_dfs.append(pl.DataFrame({
"year": [poster["year"]] * n_bins,
"title": [poster["title"]] * n_bins,
"depth_range": bin_labels,
"pixel_count": pixel_counts,
"proportion": [pc / total_pixels for pc in pixel_counts]
}))
posters_depth = pl.concat(all_dfs)
posters_depth.write_parquet("cache/posters_depth.parquet")
posters_depth
```
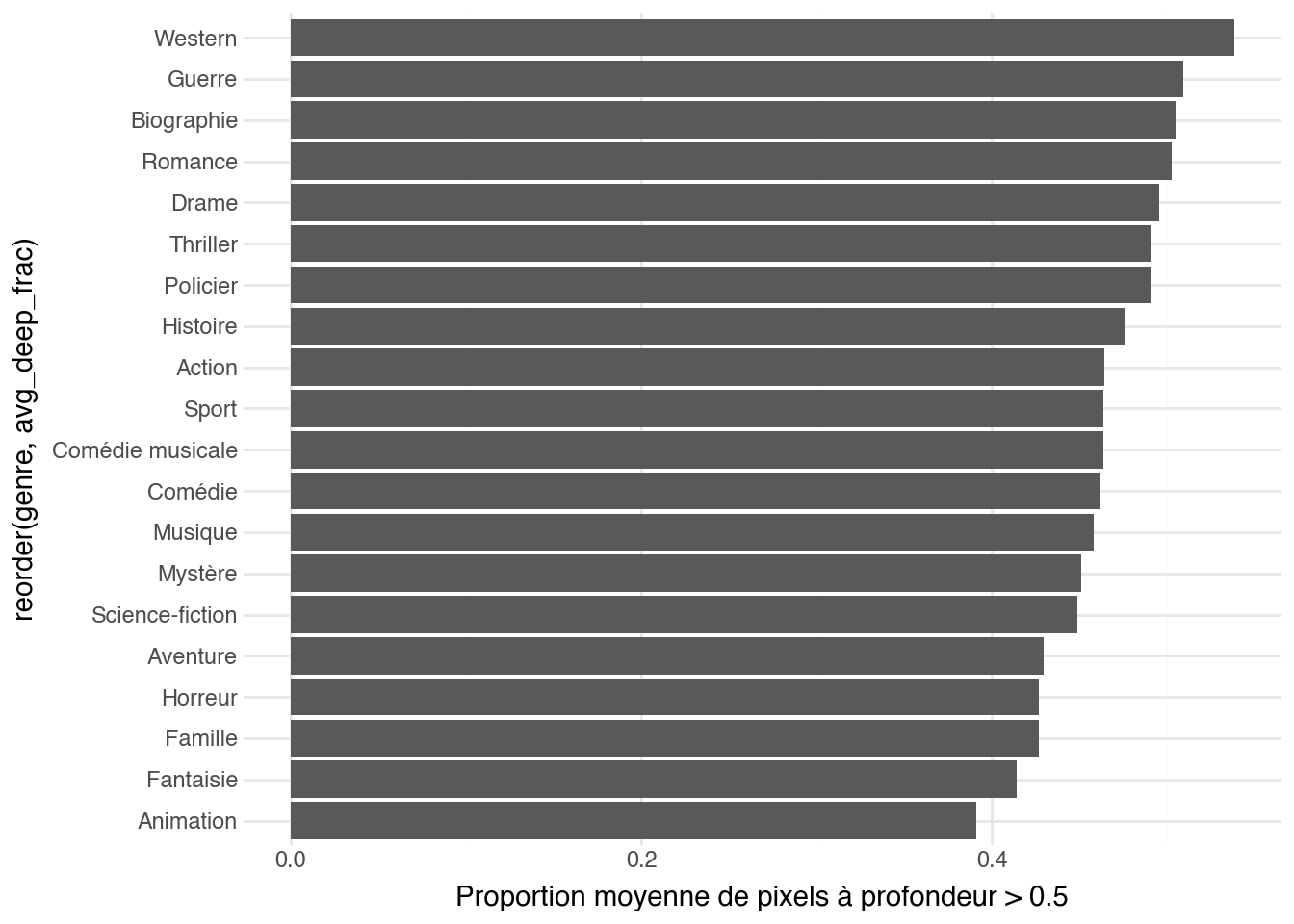
On peut par exemple regarder, par genre, la proportion moyenne de
pixels situés dans la moitié « lointaine » de la carte de profondeur.
Cela donne une idée grossière de la place que chaque genre accorde
aux arrière-plans étendus par rapport aux compositions en gros plan.
```{python}
(
posters_depth
.filter(c.depth_range.str.slice(0, 3).cast(pl.Float64) >= 0.5)
.group_by(["year", "title"])
.agg(c.proportion.sum().alias("deep_frac"))
.join(genre, on=["year", "title"])
.group_by("genre")
.agg(c.deep_frac.mean().alias("avg_deep_frac"))
.pipe(lambda df: (
ggplot(df, aes(x="reorder(genre, avg_deep_frac)", y="avg_deep_frac"))
+ geom_col()
+ coord_flip()
+ labs(x=None, y="Proportion moyenne de pixels à profondeur > 0.5")
))
)
```
## 2.8 Plongements d'images : DINOv2
Toutes les annotations vues jusqu'ici sont *interprétables* : on peut
dire « il y a deux personnes sur cette affiche » ou « 30 % de l'image
est au premier plan ». Mais on peut aussi vouloir une représentation
plus abstraite, qui résume l'image dans son ensemble en un vecteur
de nombres — un *plongement* (embedding). Deux images proches dans
leur contenu donneront des vecteurs proches dans cet espace.
Les plongements ne sont pas directement interprétables, mais ils sont
extraordinairement utiles : on peut les utiliser pour faire de la
recherche par similarité (« trouve-moi les affiches qui ressemblent
à celle-ci »), du regroupement (clustering), de la classification, ou
de la visualisation de la collection en deux dimensions par
projection (UMAP, t-SNE).
DINOv2 est un modèle de Meta AI entraîné de façon auto-supervisée
sur un très grand corpus d'images. Il produit des vecteurs d'image
de très bonne qualité sans avoir besoin de catégories d'entraînement.
```{python}
from transformers import AutoImageProcessor, AutoModel
dino_processor = AutoImageProcessor.from_pretrained("facebook/dinov2-large")
dino_model = AutoModel.from_pretrained("facebook/dinov2-large").to(device)
```
```{python}
image_path = posters["filepath"][7]
image = Image.open(image_path).convert("RGB")
```
Le modèle renvoie un vecteur de plusieurs centaines de dimensions
(1024 pour la variante « large »). Nous extrayons en particulier le
plongement dit *CLS*, qui résume l'image entière en un seul vecteur,
puis le normalisons pour qu'il soit de norme 1. Cette normalisation
rend les comparaisons par similarité cosinus plus simples.
```{python}
inputs = dino_processor(images=image, return_tensors="pt").to(device)
with torch.no_grad():
outputs = dino_model(**inputs)
cls_embedding = outputs.last_hidden_state[:, 0, :].cpu().numpy().squeeze()
patch_embeddings = outputs.last_hidden_state[:, 1:, :].cpu().numpy().squeeze()
cls_embedding_normalized = cls_embedding / (cls_embedding ** 2).sum() ** 0.5
df = pl.DataFrame({"embedding": [cls_embedding_normalized.tolist()]})
df
```
```{python}
print(f"CLS embedding shape: {cls_embedding.shape}")
print(f"Patch embeddings shape: {patch_embeddings.shape} (num_patches, embedding_dim)")
print(f"L2 norm of CLS: {(cls_embedding ** 2).sum() ** 0.5:.4f}")
fig, axes = plt.subplots(1, 2, figsize=(14, 4))
axes[0].imshow(image)
axes[0].set_title("Input image")
axes[0].axis("off")
axes[1].plot(df["embedding"][0], linewidth=0.5)
axes[1].set_title(f"DINOv2 CLS embedding ({len(cls_embedding)} dims, L2-normalized)")
axes[1].set_xlabel("Dimension")
axes[1].set_ylabel("Value")
axes[1].grid(True, alpha=0.3)
plt.tight_layout()
plt.show()
```
Le tracé du vecteur n'a pas grand intérêt visuel — c'est juste une
suite de nombres — mais il rappelle bien la nature de cette
annotation : elle est purement quantitative et n'aura de sens qu'en
comparaison avec d'autres vecteurs. Une fois tous les plongements
calculés sur la collection, on peut par exemple regrouper les
affiches similaires et examiner si les groupes obtenus
correspondent à des genres, des époques ou des écoles esthétiques.
```{python}
if os.path.exists("cache/posters_dino.parquet"):
posters_dino = pl.read_parquet("cache/posters_dino.parquet")
else:
all_dfs = []
for poster in posters.iter_rows(named=True):
img = Image.open(poster["filepath"]).convert("RGB")
inputs = dino_processor(images=img, return_tensors="pt").to(device)
with torch.no_grad():
outputs = dino_model(**inputs)
emb = outputs.last_hidden_state[:, 0, :].cpu().numpy().squeeze()
emb = emb / (emb ** 2).sum() ** 0.5
all_dfs.append(pl.DataFrame({
"year": [poster["year"]],
"title": [poster["title"]],
"embedding": [emb.tolist()]
}))
posters_dino = pl.concat(all_dfs)
posters_dino.write_parquet("cache/posters_dino.parquet")
posters_dino
```
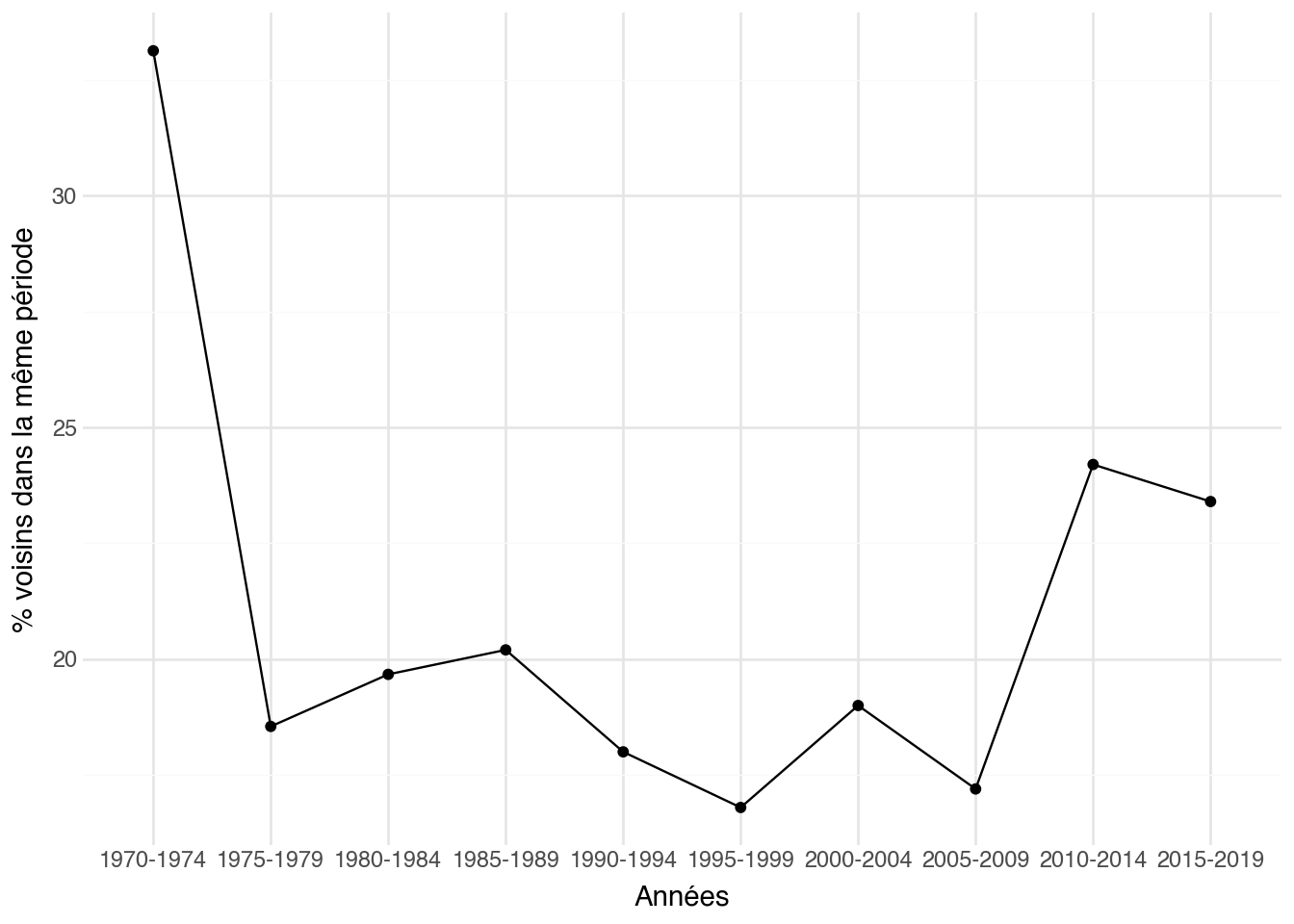
Une façon simple de tester la cohérence visuelle d'une période est
de regarder, pour chaque affiche, si son plus proche voisin dans
l'espace des plongements appartient à la même demi-décennie. Si oui,
c'est un signe que la période a une signature visuelle propre,
reconnaissable par le modèle.
```{python}
embeddings = np.array(posters_dino["embedding"].to_list())
sim = embeddings @ embeddings.T
np.fill_diagonal(sim, -np.inf)
nn_idx = sim.argmax(axis=1)
(
posters_dino
.with_columns(
pl.Series("nn_year", posters_dino["year"].to_numpy()[nn_idx]),
pl.Series("nn_title", posters_dino["title"].to_numpy()[nn_idx]),
)
.join(posters.select(["year", "title", "period"]), on=["year", "title"])
.join(
posters.select(["year", "title", "period"])
.rename({"year": "nn_year", "title": "nn_title", "period": "nn_period"}),
on=["nn_year", "nn_title"]
)
.with_columns(
same_period=(c.period == c.nn_period),
)
.group_by("period")
.agg(pct_same=c.same_period.mean() * 100)
.sort("period")
.pipe(ggplot, aes("period", "pct_same"))
+ geom_line(group=1)
+ geom_point()
+ labs(x="Années", y="% voisins dans la même période")
)
```
## 2.9 Modèles contrastifs : SigLIP2
DINOv2 produit des plongements à partir d'images seules. Une autre
famille de modèles, dits *contrastifs*, apprend conjointement à
représenter images et textes dans un même espace. Le modèle le plus
connu est CLIP ; SigLIP et sa version améliorée SigLIP2 en sont des
évolutions plus performantes.
L'intérêt est considérable : si images et textes vivent dans le même
espace vectoriel, on peut comparer une image à une phrase
(« combien cette affiche ressemble-t-elle à *un film d'horreur des
années 1980* ? »), classer des images sans données d'entraînement
spécifiques, ou faire de la recherche bidirectionnelle entre les deux
modalités.
```{python}
from transformers import AutoProcessor, AutoModel
siglip_processor = AutoProcessor.from_pretrained("google/siglip2-base-patch16-224")
siglip_model = AutoModel.from_pretrained("google/siglip2-base-patch16-224").to(device)
```
```{python}
image_path = posters["filepath"][7]
image = Image.open(image_path).convert("RGB")
```
Pour le moment, nous nous contentons d'extraire le plongement image,
comme nous l'avons fait avec DINOv2. La différence essentielle, qu'on
ne voit pas dans le code, est que cet espace est aligné avec celui
des textes du même modèle.
```{python}
inputs = siglip_processor(images=image, return_tensors="pt").to(device)
with torch.no_grad():
output = siglip_model.get_image_features(**inputs)
image_features = output if torch.is_tensor(output) else output.pooler_output
image_embedding = image_features.cpu().numpy().squeeze()
image_embedding_normalized = image_embedding / (image_embedding ** 2).sum() ** 0.5
df = pl.DataFrame({"embedding": [image_embedding_normalized.tolist()]})
df
```
```{python}
print(f"Embedding shape: {image_embedding.shape}")
print(f"L2 norm: {(image_embedding ** 2).sum() ** 0.5:.4f}")
fig, axes = plt.subplots(1, 2, figsize=(14, 4))
axes[0].imshow(image)
axes[0].set_title("Input image")
axes[0].axis("off")
axes[1].plot(df["embedding"][0], linewidth=0.5)
axes[1].set_title(f"SigLIP2 embedding ({len(image_embedding)} dims, L2-normalized)")
axes[1].set_xlabel("Dimension")
axes[1].set_ylabel("Value")
axes[1].grid(True, alpha=0.3)
plt.tight_layout()
plt.show()
```
DINOv2 et SigLIP2 ont chacun leurs forces. DINOv2 a tendance à mieux
capturer la structure visuelle et la composition, tandis que SigLIP2
est plus sensible au contenu sémantique aligné avec le langage. Dans
les analyses, il peut être intéressant de comparer les deux : si les
regroupements obtenus diffèrent, c'est souvent révélateur des
dimensions visuelles que chaque modèle privilégie.
```{python}
if os.path.exists("cache/posters_siglip.parquet"):
posters_siglip = pl.read_parquet("cache/posters_siglip.parquet")
else:
all_dfs = []
for poster in posters.iter_rows(named=True):
img = Image.open(poster["filepath"]).convert("RGB")
inputs = siglip_processor(images=img, return_tensors="pt").to(device)
with torch.no_grad():
output = siglip_model.get_image_features(**inputs)
image_features = output if torch.is_tensor(output) else output.pooler_output
emb = image_features.cpu().numpy().squeeze()
emb = emb / (emb ** 2).sum() ** 0.5
all_dfs.append(pl.DataFrame({
"year": [poster["year"]],
"title": [poster["title"]],
"embedding": [emb.tolist()]
}))
posters_siglip = pl.concat(all_dfs)
posters_siglip.write_parquet("cache/posters_siglip.parquet")
posters_siglip
```
Comme images et textes partagent le même espace, on peut classer les
affiches selon leur proximité à une phrase de notre choix. Voici par
exemple les affiches qui ressemblent le plus, selon SigLIP2, à la
description « A scary movie poster » — un moyen rapide de retrouver
les codes visuels associés à un genre sans avoir à les définir
explicitement.
```{python}
text_inputs = siglip_processor(text=["A scary movie poster"], padding="max_length", return_tensors="pt").to(device)
with torch.no_grad():
text_emb = siglip_model.get_text_features(**text_inputs).pooler_output
text_emb = (text_emb / text_emb.norm(p=2, dim=-1, keepdim=True)).cpu().numpy().squeeze()
embeddings = np.array(posters_siglip["embedding"].to_list())
scores = embeddings @ text_emb
(
posters_siglip
.with_columns(pl.Series("score", scores))
.join(posters, on=["year", "title"])
.sort("score", descending=True)
.pipe(plot_image_grid, ncol=4, limit=12)
)
```
## 2.10 Détection et reconnaissance de visages
Les visages sont au cœur de la grammaire visuelle des affiches de
films. Nous allons ici aller un cran plus loin avec la bibliothèque
InsightFace, qui détecte les visages, estime l'âge et le genre
apparents, et produit un plongement permettant de reconnaître si
deux visages sont ceux de la même personne.
Quelques mots de précaution s'imposent. L'âge et le genre prédits
par ces modèles sont des estimations probabilistes, fondées sur les
données d'entraînement utilisées. Ces données présentent des biais
connus (sous-représentation de certaines populations, étiquettes
binaires pour le genre, etc.), et il est important d'en tenir compte
dans toute analyse. Ces annotations sont utiles pour décrire des
tendances à l'échelle agrégée, pas pour étiqueter de façon définitive
les personnes représentées.
```{python}
#| eval: false
!pip install -q insightface
!pip install -q onnxruntime
```
```{python}
#| warning: false
#| message: false
#| output: false
import insightface
from insightface.app import FaceAnalysis
face_app = FaceAnalysis(name="buffalo_l", providers=["CPUExecutionProvider"])
face_app.prepare(ctx_id=0, det_size=(640, 640))
```
```{python}
image_path = posters["filepath"][0]
image = Image.open(image_path).convert("RGB")
```
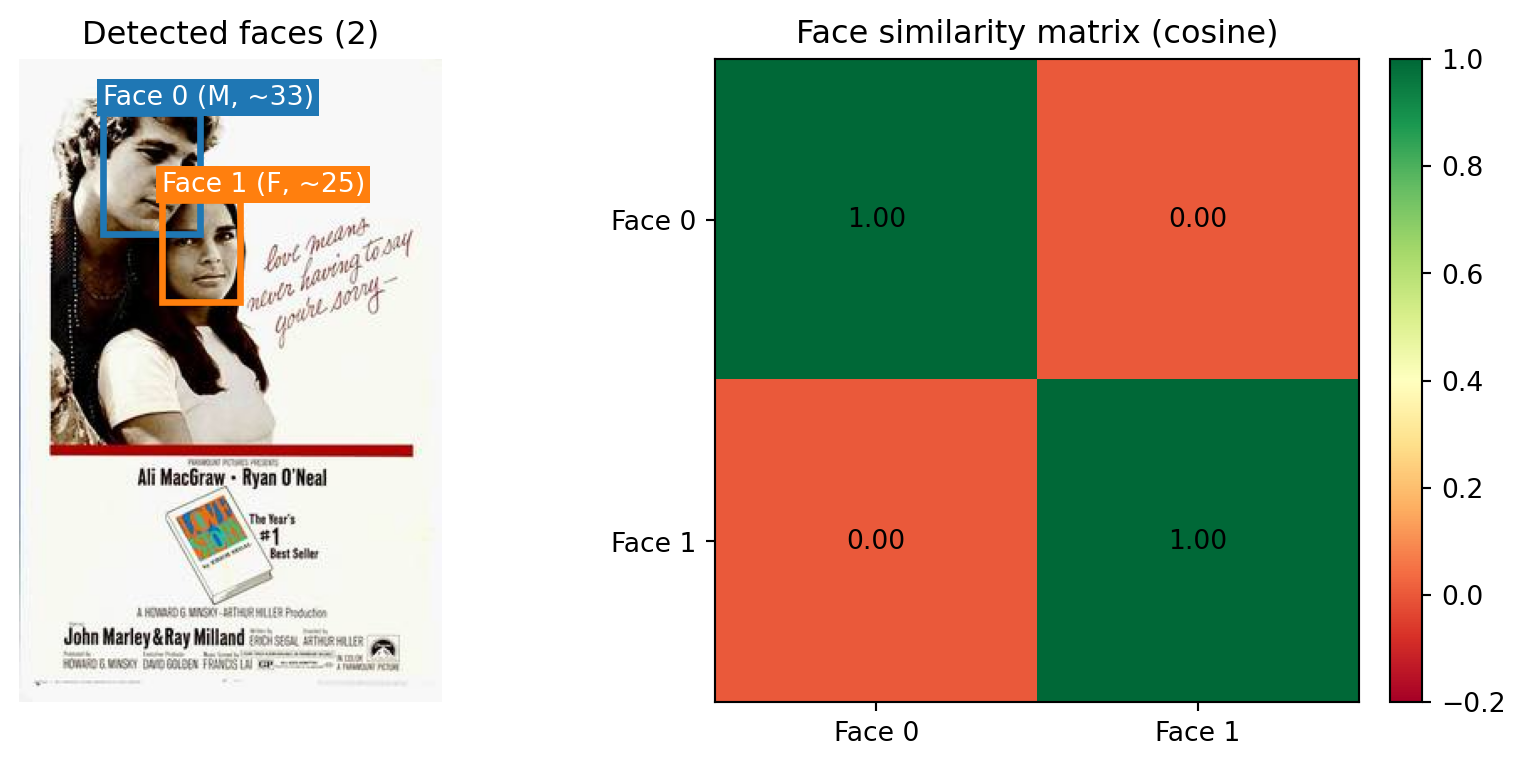
InsightFace renvoie pour chaque visage : une boîte englobante, un
plongement normalisé (de dimension 512), une estimation d'âge et de
genre. Le plongement permet de calculer une matrice de similarité
entre tous les visages détectés : des valeurs proches de 1 indiquent
deux visages similaires (potentiellement la même personne), des
valeurs faibles ou négatives indiquent des visages différents.
```{python}
#| warning: false
#| message: false
image_bgr = np.array(image)[:, :, ::-1]
faces = face_app.get(image_bgr)
boxes = np.array([f.bbox for f in faces])
embeddings = np.array([f.normed_embedding for f in faces])
ages = [int(f.age) for f in faces]
genders = ["M" if f.gender == 1 else "F" for f in faces]
similarity_matrix = embeddings @ embeddings.T if len(embeddings) > 0 else np.zeros((0, 0))
if len(faces) > 0:
df = pl.DataFrame({
"face_id": list(range(len(faces))),
"xmin": boxes[:, 0].tolist(),
"ymin": boxes[:, 1].tolist(),
"xmax": boxes[:, 2].tolist(),
"ymax": boxes[:, 3].tolist(),
"age": ages,
"gender": genders
})
else:
df = pl.DataFrame(schema={
"face_id": pl.Int32, "xmin": pl.Float32, "ymin": pl.Float32,
"xmax": pl.Float32, "ymax": pl.Float32, "age": pl.Int32, "gender": pl.Utf8
})
df
```
```{python}
colors = plt.cm.tab10.colors
fig, axes = plt.subplots(1, 2, figsize=(9, 4))
axes[0].imshow(image)
for row in df.iter_rows(named=True):
i = row["face_id"]
x1, y1, x2, y2 = row["xmin"], row["ymin"], row["xmax"], row["ymax"]
color = colors[i % len(colors)]
rect = patches.Rectangle((x1, y1), x2 - x1, y2 - y1, linewidth=2.5, edgecolor=color, facecolor="none")
axes[0].add_patch(rect)
axes[0].text(
x1, y1 - 5, f"Face {i} ({row['gender']}, ~{row['age']})",
color="white", fontsize=10, bbox=dict(facecolor=color, edgecolor="none", pad=2)
)
axes[0].set_title(f"Detected faces ({len(df)})")
axes[0].axis("off")
if len(faces) > 0:
im = axes[1].imshow(similarity_matrix, cmap="RdYlGn", vmin=-0.2, vmax=1.0)
axes[1].set_xticks(range(len(faces)))
axes[1].set_yticks(range(len(faces)))
axes[1].set_xticklabels([f"Face {i}" for i in range(len(faces))])
axes[1].set_yticklabels([f"Face {i}" for i in range(len(faces))])
for i in range(len(faces)):
for j in range(len(faces)):
axes[1].text(j, i, f"{similarity_matrix[i, j]:.2f}", ha="center", va="center", color="black", fontsize=10)
axes[1].set_title("Face similarity matrix (cosine)")
plt.colorbar(im, ax=axes[1], fraction=0.046, pad=0.04)
else:
axes[1].text(0.5, 0.5, "No faces detected", ha="center", va="center", transform=axes[1].transAxes)
axes[1].axis("off")
plt.tight_layout()
plt.show()
```
Avec ces annotations, on peut par exemple suivre l'évolution du
nombre moyen de visages par affiche, ou comparer les distributions
d'âge apparent par genre cinématographique. Les plongements
permettent aussi de détecter si la même personne apparaît sur
plusieurs affiches — utile pour étudier la carrière des acteurs ou
les visages récurrents d'une époque.
```{python}
if os.path.exists("cache/posters_face.parquet"):
posters_face = pl.read_parquet("cache/posters_face.parquet")
else:
all_dfs = []
for poster in posters.iter_rows(named=True):
img = Image.open(poster["filepath"]).convert("RGB")
img_bgr = np.array(img)[:, :, ::-1]
faces = face_app.get(img_bgr)
if len(faces) == 0:
continue
boxes = np.array([f.bbox for f in faces])
n = len(faces)
all_dfs.append(pl.DataFrame({
"year": [poster["year"]] * n,
"title": [poster["title"]] * n,
"face_id": list(range(n)),
"xmin": boxes[:, 0].tolist(),
"ymin": boxes[:, 1].tolist(),
"xmax": boxes[:, 2].tolist(),
"ymax": boxes[:, 3].tolist(),
"age": [int(f.age) for f in faces],
"gender": ["M" if f.gender == 1 else "F" for f in faces]
}))
posters_face = pl.concat(all_dfs)
posters_face.write_parquet("cache/posters_face.parquet")
posters_face
```
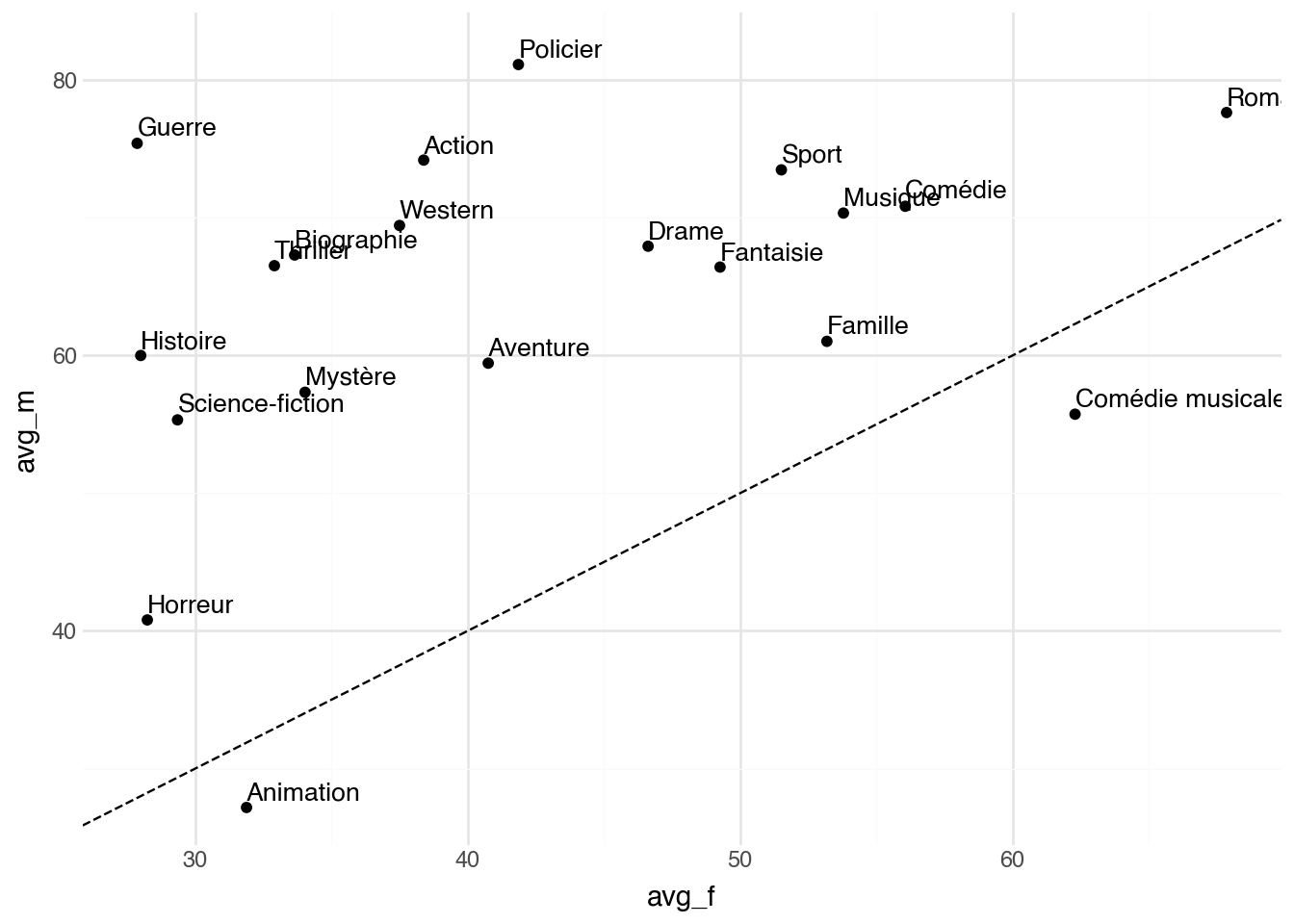
Pour illustrer, on peut comparer chaque genre selon la part de ses
affiches qui contiennent au moins un visage classé féminin et la
part qui contiennent au moins un visage classé masculin. La diagonale
sert de repère : les genres qui s'en écartent sont ceux où les
visages détectés penchent fortement d'un côté ou de l'autre.
```{python}
(
genre
.join(posters_face, on=[c.year, c.title], how="left")
.group_by(c.year, c.title, c.genre)
.agg(
any_f = (c.gender == "F").max().fill_null(False),
any_m = (c.gender == "M").max().fill_null(False)
)
.group_by(c.genre)
.agg(
avg_f = c.any_f.mean() * 100,
avg_m = c.any_m.mean() * 100
)
.pipe(ggplot, aes("avg_f", "avg_m"))
+ geom_point()
+ geom_text(aes(label="genre"), ha="left", size=10, nudge_y=1)
+ geom_abline(linetype="dashed")
)
```
## 2.11 Estimation de pose : ViTPose
Au-delà de la simple détection d'une personne, on peut chercher à
caractériser sa *pose* : position de la tête, des bras, des jambes.
L'estimation de pose consiste à localiser un ensemble de points-clés
anatomiques (nez, yeux, épaules, coudes, etc.) sur le corps humain.
Pour des affiches de films, c'est particulièrement intéressant car
les poses sont rarement neutres : héros debout face à la caméra,
amants enlacés, action en plein mouvement. Quantifier ces postures
peut révéler des conventions visuelles propres à chaque genre.
Notre pipeline procède en deux étapes : on détecte d'abord les
personnes avec DETR, puis on applique ViTPose, un modèle dédié à
l'estimation de pose, sur chaque personne détectée.
```{python}
from transformers import AutoImageProcessor, AutoModelForObjectDetection, VitPoseImageProcessor, VitPoseForPoseEstimation
person_processor = AutoImageProcessor.from_pretrained("facebook/detr-resnet-50")
person_model = AutoModelForObjectDetection.from_pretrained("facebook/detr-resnet-50").to(device)
pose_processor = VitPoseImageProcessor.from_pretrained("usyd-community/vitpose-base-simple")
pose_model = VitPoseForPoseEstimation.from_pretrained("usyd-community/vitpose-base-simple").to(device)
```
```{python}
image_path = posters["filepath"][0]
image = Image.open(image_path).convert("RGB")
confidence_threshold = 0.3
keypoint_names = [
"nose", "left_eye", "right_eye", "left_ear", "right_ear",
"left_shoulder", "right_shoulder", "left_elbow", "right_elbow",
"left_wrist", "right_wrist", "left_hip", "right_hip",
"left_knee", "right_knee", "left_ankle", "right_ankle"
]
```
ViTPose prédit pour chaque personne 17 points-clés selon la convention
COCO, chacun accompagné d'un score de confiance. Les points peu
fiables (score sous le seuil) seront laissés de côté lors de la
visualisation.
```{python}
det_inputs = person_processor(images=image, return_tensors="pt").to(device)
with torch.no_grad():
det_outputs = person_model(**det_inputs)
det_results = person_processor.post_process_object_detection(
det_outputs, target_sizes=torch.tensor([image.size[::-1]]), threshold=0.8
)[0]
person_mask = det_results["labels"].cpu().numpy() == person_model.config.label2id["person"]
person_boxes = det_results["boxes"].cpu().numpy()[person_mask]
person_boxes_xywh = person_boxes.copy()
person_boxes_xywh[:, 2] -= person_boxes_xywh[:, 0]
person_boxes_xywh[:, 3] -= person_boxes_xywh[:, 1]
pose_inputs = pose_processor(image, boxes=[person_boxes_xywh.tolist()], return_tensors="pt").to(device)
with torch.no_grad():
pose_outputs = pose_model(**pose_inputs)
pose_results = pose_processor.post_process_pose_estimation(pose_outputs, boxes=[person_boxes_xywh.tolist()])[0]
rows = []
for person_idx, person in enumerate(pose_results):
keypoints = person["keypoints"].cpu().numpy()
kp_scores = person["scores"].cpu().numpy()
for k_idx, ((x, y), score) in enumerate(zip(keypoints, kp_scores)):
rows.append({
"person_id": person_idx,
"keypoint": keypoint_names[k_idx],
"x": float(x),
"y": float(y),
"score": float(score)
})
df = pl.DataFrame(rows)
df
```
Le squelette est obtenu en reliant des paires de points-clés selon
une convention anatomique (nez aux yeux, épaule au coude, coude au
poignet, etc.).
```{python}
#| warning: false
#| message: false
skeleton = [
(0,1),(0,2),(1,3),(2,4),(5,6),(5,7),(7,9),(6,8),(8,10),
(5,11),(6,12),(11,12),(11,13),(13,15),(12,14),(14,16)
]
colors = plt.cm.tab10.colors
fig, ax = plt.subplots(1, 1, figsize=(6, 6))
ax.imshow(image)
for person_idx, person in enumerate(pose_results):
color = colors[person_idx % len(colors)]
keypoints = person["keypoints"].cpu().numpy()
kp_scores = person["scores"].cpu().numpy()
box = person_boxes[person_idx]
rect = patches.Rectangle(
(box[0], box[1]), box[2] - box[0], box[3] - box[1],
linewidth=1.5, edgecolor=color, facecolor="none", linestyle="--", alpha=0.5
)
ax.add_patch(rect)
for j1, j2 in skeleton:
if kp_scores[j1] > confidence_threshold and kp_scores[j2] > confidence_threshold:
ax.plot([keypoints[j1, 0], keypoints[j2, 0]], [keypoints[j1, 1], keypoints[j2, 1]], color=color, linewidth=2.5, alpha=0.8)
for (x, y), score in zip(keypoints, kp_scores):
if score > confidence_threshold:
ax.scatter([x], [y], color=color, s=40, edgecolor="white", linewidth=1.5, zorder=5)
else:
ax.scatter([x], [y], color=color, s=20, edgecolor="white", linewidth=0.5, alpha=0.3, marker="x", zorder=5)
ax.set_title(f"ViTPose — {len(pose_results)} person(s), confidence threshold {confidence_threshold}")
ax.axis("off")
plt.tight_layout()
plt.show()
```
Les affiches stylisées posent un défi particulier à ViTPose, qui a
été entraîné sur des photographies. Les silhouettes très simplifiées,
les angles inhabituels ou les corps partiellement occultés génèrent
des estimations imparfaites. Cela dit, à grande échelle, ces
annotations permettent quand même de quantifier des choses
intéressantes : proportion d'affiches où l'on voit les visages, où
les personnages tendent les bras, où la pose est centrée ou décalée.
```{python}
if os.path.exists("cache/posters_pose.parquet"):
posters_pose = pl.read_parquet("cache/posters_pose.parquet")
else:
all_dfs = []
for poster in posters.iter_rows(named=True):
img = Image.open(poster["filepath"]).convert("RGB")
det_inputs = person_processor(images=img, return_tensors="pt").to(device)
with torch.no_grad():
det_outputs = person_model(**det_inputs)
det_results = person_processor.post_process_object_detection(
det_outputs, target_sizes=torch.tensor([img.size[::-1]]), threshold=0.8
)[0]
person_mask = det_results["labels"].cpu().numpy() == person_model.config.label2id["person"]
person_boxes = det_results["boxes"].cpu().numpy()[person_mask]
if len(person_boxes) == 0:
continue
person_boxes_xywh = person_boxes.copy()
person_boxes_xywh[:, 2] -= person_boxes_xywh[:, 0]
person_boxes_xywh[:, 3] -= person_boxes_xywh[:, 1]
pose_inputs = pose_processor(img, boxes=[person_boxes_xywh.tolist()], return_tensors="pt").to(device)
with torch.no_grad():
pose_outputs = pose_model(**pose_inputs)
pose_results_all = pose_processor.post_process_pose_estimation(pose_outputs, boxes=[person_boxes_xywh.tolist()])[0]
rows = []
for person_idx, person in enumerate(pose_results_all):
keypoints = person["keypoints"].cpu().numpy()
kp_scores = person["scores"].cpu().numpy()
for k_idx, ((x, y), score) in enumerate(zip(keypoints, kp_scores)):
rows.append({
"year": poster["year"],
"title": poster["title"],
"person_id": person_idx,
"keypoint": keypoint_names[k_idx],
"x": float(x),
"y": float(y),
"score": float(score)
})
if rows:
all_dfs.append(pl.DataFrame(rows))
posters_pose = pl.concat(all_dfs)
posters_pose.write_parquet("cache/posters_pose.parquet")
posters_pose
```
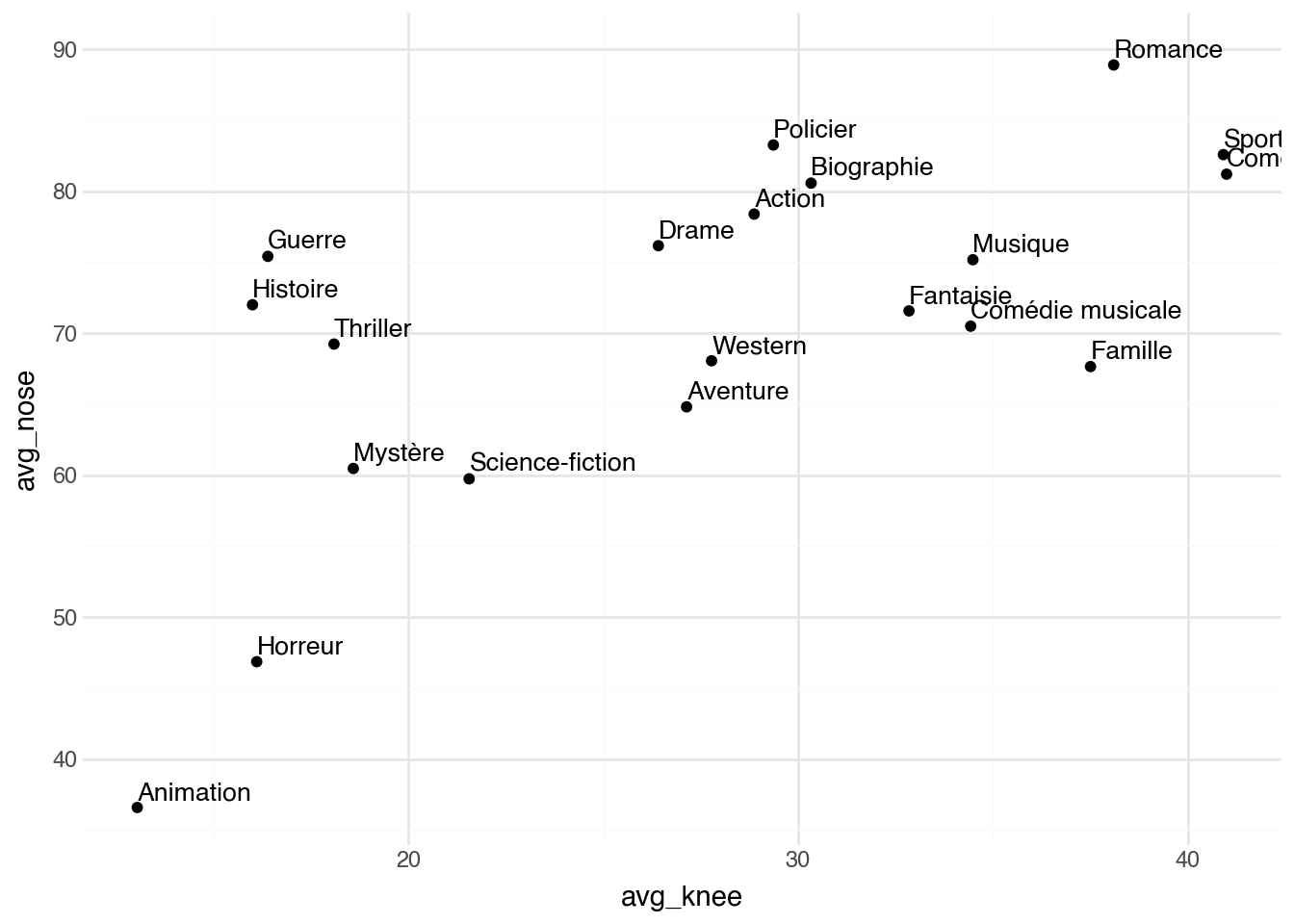
On peut s'en servir pour comparer les genres selon la part de leurs
affiches où l'on distingue clairement le visage (nez détecté avec
confiance) et celle où l'on voit les jambes (genoux détectés) — un
proxy simple pour distinguer les compositions cadrées sur la tête de
celles qui montrent les personnages en pied.
```{python}
(
genre
.join(posters_pose, on=[c.year, c.title], how="left")
.group_by(c.year, c.title, c.genre)
.agg(
any_nose = (
(c.keypoint.is_in(["nose"])) & (c.score > 0.8)
).max().fill_null(False),
any_knee = (
(c.keypoint.is_in(["left_knee", "right_knee"])) & (c.score > 0.8)
).max().fill_null(False)
)
.group_by(c.genre)
.agg(
avg_nose = c.any_nose.mean() * 100,
avg_knee = c.any_knee.mean() * 100
)
.pipe(ggplot, aes("avg_knee", "avg_nose"))
+ geom_point()
+ geom_text(aes(label="genre"), ha="left", size=10, nudge_y=1)
)
```
## 2.12 Modèles vision-langage (VLM)
Les modèles vus jusqu'ici produisent des sorties structurées : des
boîtes, des masques, des vecteurs. Les modèles vision-langage (VLM)
font quelque chose de différent : on leur fournit une image et une
question en langage naturel, et ils répondent en langage naturel.
Ce sont, schématiquement, des LLM auxquels on a ajouté un encodeur
d'images. On peut leur demander de décrire ce qu'ils voient, de
compter des éléments, d'interpréter une scène, ou de répondre à des
questions ouvertes sur le contenu visuel.
Nous utilisons ici l'API OpenAI avec le modèle `gpt-5.4-nano`, qui
offre des capacités de vision à faible coût et sans nécessiter de
ressources locales.
```{python}
#| eval: false
!pip install -q openai
```
```{python}
import base64
from openai import OpenAI
client = OpenAI(api_key="PLACEZ-LE-ICI")
def encode_image(path):
with open(path, "rb") as f:
return base64.b64encode(f.read()).decode("utf-8")
```
```{python}
image_path = posters["filepath"][7]
image = Image.open(image_path).convert("RGB")
```
La question que nous posons est libre. Ici, nous demandons une
description des couleurs dominantes — l'occasion de comparer la
réponse du VLM avec les annotations colorimétriques produites de
façon plus rigoureuse dans le premier notebook.
```{python}
question = "Describe the dominant colors in this movie poster"
if os.path.exists("cache/posters_vlm_single.parquet"):
df = pl.read_parquet("cache/posters_vlm_single.parquet")
else:
b64 = encode_image(image_path)
response = client.chat.completions.create(
model="gpt-5.4-nano-2026-03-17",
messages=[{
"role": "user",
"content": [
{"type": "image_url", "image_url": {"url": f"data:image/jpeg;base64,{b64}"}},
{"type": "text", "text": question}
]
}],
max_completion_tokens=512
)
df = pl.DataFrame({"question": [question], "response": [response.choices[0].message.content]})
df.write_parquet("cache/posters_vlm_single.parquet")
answer = df["response"][0]
df
```
```{python}
import textwrap
wrapped = "\n".join(textwrap.wrap(answer, width=60))
fig, axes = plt.subplots(1, 2, figsize=(14, 6))
axes[0].imshow(image)
axes[0].set_title("Input image")
axes[0].axis("off")
axes[1].axis("off")
axes[1].text(0.0, 1.0, f"Q: {question}\n\nA: {wrapped}", fontsize=9, transform=axes[1].transAxes, va="top")
plt.tight_layout()
plt.show()
```
Les VLM sont impressionnants, mais ils introduisent de nouvelles
difficultés. Leurs réponses sont des textes libres, qui peuvent
varier d'une exécution à l'autre ; ils peuvent « halluciner »
(décrire des éléments absents de l'image) ; et leur formulation
dépend largement de la façon dont la question est posée. Du point de
vue du distant viewing, ils restent des constructeurs d'annotations
parmi d'autres — particulièrement riches, mais aussi
particulièrement opaques. Il est essentiel de les valider sur des
échantillons avant d'en tirer des conclusions à grande échelle.
```{python}
if os.path.exists("cache/posters_vlm.parquet"):
posters_vlm = pl.read_parquet("cache/posters_vlm.parquet")
else:
all_dfs = []
for poster in posters.iter_rows(named=True):
b64 = encode_image(poster["filepath"])
resp = client.chat.completions.create(
model="gpt-5.4-nano-2026-03-17",
messages=[{
"role": "user",
"content": [
{"type": "image_url", "image_url": {"url": f"data:image/jpeg;base64,{b64}"}},
{"type": "text", "text": question}
]
}],
max_completion_tokens=512
)
all_dfs.append(pl.DataFrame({
"year": [poster["year"]],
"title": [poster["title"]],
"question": [question],
"response": [resp.choices[0].message.content]
}))
posters_vlm = pl.concat(all_dfs)
posters_vlm.write_parquet("cache/posters_vlm.parquet")
posters_vlm
```
## 2.13 VLM avec sortie structurée
Le texte libre est agréable à lire mais difficile à analyser en masse.
Pour 5 000 affiches, on préfère obtenir des données structurées :
des champs nommés, des listes, des catégories. Heureusement, la
plupart des VLM modernes acceptent une contrainte de format de
sortie, généralement sous forme de schéma JSON. On définit la
structure attendue, et le modèle est forcé de produire une sortie
conforme — bien plus simple à parser et à fusionner avec le reste
des annotations.
Nous utilisons ici Pydantic pour décrire le schéma de sortie. Chaque
champ a un nom, un type, et une description qui sert d'indication
au modèle.
```{python}
from pydantic import BaseModel, Field
from enum import Enum
class PosterColor(str, Enum):
black = "noir"
white = "blanc"
gray = "gris"
red = "rouge"
orange = "orange"
yellow = "jaune"
green = "vert"
blue = "bleu"
purple = "violet"
pink = "rose"
brown = "marron"
teal = "sarcelle"
gold = "or"
silver = "argent"
class ColorAnalysis(BaseModel):
background_color: PosterColor = Field(description="La couleur dominante de l'arrière-plan de l'affiche.")
foreground_color: PosterColor = Field(description="La couleur dominante du premier plan (sujet principal ou personnage).")
text_color: PosterColor = Field(description="La couleur principale utilisée pour le texte sur l'affiche.")
accent_color: PosterColor = Field(description="La couleur d'accent ou de mise en valeur utilisée.")
vibe_description: str = Field(description="Une brève description de l'ambiance ou de l'atmosphère créée par ces couleurs.")
```
```{python}
image_path = posters["filepath"][7]
image = Image.open(image_path).convert("RGB")
```
La génération se fait via `client.beta.chat.completions.parse`, qui
retourne directement un objet Pydantic validé sans traitement
supplémentaire. En cas d'échec, nous conservons la sortie brute pour
pouvoir l'inspecter.
```{python}
question = "Analysez cette affiche de film et identifiez la couleur de l'arrière-plan, la couleur du premier plan, la couleur du texte et la couleur d'accent."
if os.path.exists("cache/posters_vlm_struct_single.parquet"):
df = pl.read_parquet("cache/posters_vlm_struct_single.parquet")
else:
b64 = encode_image(image_path)
response = client.beta.chat.completions.parse(
model="gpt-5.4-nano-2026-03-17",
messages=[{
"role": "user",
"content": [
{"type": "image_url", "image_url": {"url": f"data:image/jpeg;base64,{b64}"}},
{"type": "text", "text": question}
]
}],
response_format=ColorAnalysis,
max_completion_tokens=512
)
parsed = response.choices[0].message.parsed
try:
df = pl.DataFrame({
"background_color": [parsed.background_color.value],
"foreground_color": [parsed.foreground_color.value],
"text_color": [parsed.text_color.value],
"accent_color": [parsed.accent_color.value],
"vibe_description": [parsed.vibe_description]
})
except Exception as e:
print(f"Parse error: {e}")
df = pl.DataFrame({"raw_output": [response.choices[0].message.content]})
df.write_parquet("cache/posters_vlm_struct_single.parquet")
df
```
```{python}
import textwrap
if "raw_output" not in df.columns:
vibe_wrapped = "\n".join(textwrap.wrap(df["vibe_description"][0], width=50))
text = (
f"Arrière-plan : {df['background_color'][0]}\n"
f"Premier plan : {df['foreground_color'][0]}\n"
f"Texte : {df['text_color'][0]}\n"
f"Accent : {df['accent_color'][0]}\n\n"
f"Ambiance :\n{vibe_wrapped}"
)
else:
text = df["raw_output"][0]
fig, axes = plt.subplots(1, 2, figsize=(14, 6))
axes[0].imshow(image)
axes[0].set_title("Input image")
axes[0].axis("off")
axes[1].axis("off")
axes[1].text(0.0, 1.0, text, fontsize=10, transform=axes[1].transAxes, va="top")
plt.tight_layout()
plt.show()
```
La sortie structurée transforme un VLM, qui produirait sinon du
texte difficilement exploitable, en générateur d'annotations
directement utilisables. On peut combiner des champs catégoriels
(couleur dominante, ambiance) avec des descriptions plus ouvertes,
et tirer parti du meilleur des deux mondes : la richesse
interprétative du langage naturel et la structure des bases de
données.
```{python}
if os.path.exists("cache/posters_vlm_struct.parquet"):
posters_vlm_struct = pl.read_parquet("cache/posters_vlm_struct.parquet")
else:
all_dfs = []
for poster in posters.iter_rows(named=True):
b64 = encode_image(poster["filepath"])
resp = client.beta.chat.completions.parse(
model="gpt-5.4-nano-2026-03-17",
messages=[{
"role": "user",
"content": [
{"type": "image_url", "image_url": {"url": f"data:image/jpeg;base64,{b64}"}},
{"type": "text", "text": question}
]
}],
response_format=ColorAnalysis,
max_completion_tokens=512
)
parsed = resp.choices[0].message.parsed
if parsed is not None:
all_dfs.append(pl.DataFrame({
"year": [poster["year"]],
"title": [poster["title"]],
"background_color": [parsed.background_color.value],
"foreground_color": [parsed.foreground_color.value],
"text_color": [parsed.text_color.value],
"accent_color": [parsed.accent_color.value],
"vibe_description": [parsed.vibe_description]
}))
posters_vlm_struct = pl.concat(all_dfs)
posters_vlm_struct.write_parquet("cache/posters_vlm_struct.parquet")
posters_vlm_struct
```
À partir des couleurs prédites par le VLM, on peut suivre par
période la part des affiches dont l'arrière-plan dominant est
identifié comme blanc, et celle dont l'arrière-plan est identifié
comme noir. C'est un proxy commode pour interroger les évolutions
de la palette graphique des affiches à travers les décennies.
```{python}
(
posters_vlm_struct
.join(posters, on=[c.year, c.title])
.group_by(c.period)
.agg(
arr_blanc = (c.background_color == "blanc").mean() * 100,
texte_noir = (c.text_color == "noir").mean() * 100,
)
.pipe(ggplot, aes("period", "arr_blanc"))
+ geom_line(group=1, linetype="dotted")
+ geom_line(aes(y="texte_noir"), group=1)
)
```
## 2.14 Conclusion et prochaines étapes
Nous avons parcouru tout un éventail de modèles de vision par
ordinateur modernes, chacun produisant un type d'annotation
différent : étiquettes d'objets, masques de segmentation, texte
extrait, cartes de profondeur, plongements, visages, poses,
descriptions en langage naturel et données structurées. Chacune de
ces annotations ouvre une perspective particulière sur la
collection, et toutes peuvent être combinées pour répondre à des
questions de recherche plus complexes que ce que permettrait une
seule d'entre elles.
Quelques principes à retenir au-delà du contenu technique. D'abord,
la puissance d'un modèle ne dispense jamais de revenir aux images
pour vérifier ses sorties — au contraire, elle rend cette
vérification plus importante, car les erreurs des modèles complexes
sont souvent plus subtiles que celles des méthodes simples. Ensuite,
le choix du modèle, du prompt et des seuils fait partie intégrante
de l'analyse : ce sont des choix de recherche, qui méritent d'être
explicités. Enfin, les annotations produites ici sont des points de
départ, pas des conclusions. Le vrai travail commence quand on les
relie aux questions historiques et culturelles qui motivent l'étude.
Pour aller plus loin, on peut combiner les annotations entre elles
(par exemple : où sont placés les visages dans la composition en
profondeur ?), construire des analyses comparatives entre genres ou
époques, ou affiner les modèles sur des sous-corpus particuliers.
Merci d'avoir suivi ce tutoriel, et n'hésitez pas à nous faire part
de vos questions et retours !