
install.packages("ggplot2")Atelier : R pour la linguistique
Dans cet atelier, je vous présente une introduction au langage R pour l’étude de la linguistique. R est un langage de programmation libre avec le code source ouvert qui est particulièrement populaire dans les sciences naturelles et sociales. Nous commençons par une introduction générale aux fonctions permettant de télécharger, visualiser et manipuler des données structurées sous forme de tableau. Ensuite, nous continuons à étudier des modèles spécifiques pour l’étude du langage. Nous finissons avec l’application des interfaces de programmation d’application (API) pour l’usage des grands modèles de langage. Dans tous les exemples, nous employons les données qui proviennent de diverses parties de la linguistique.
Bien que nous présentions les principaux concepts dans les notes suivantes, nous vous suggérons de consulter les ressources supplémentaires suivantes pour approfondir le sujet :
- R for Data Science (2e) Livre disponible gratuitement en anglais qui approfondit les fonctions essentielles de visualisation, de manipulation et de programmation des données dans R présentées dans ces notes.
- Humanities Data in R (2e) Livre accèsible en anglais (nom d’utilisateur et mot de passe son “hdir”) qui donne les méthodes plus avancées pour traiter des données complexes et multimodales.
- Les aides-mémoirs : les graphiques, remaniement de données, et expressions régulières
Vous trouverez également une documentation complète sur les différentes fonctions et les différents «packages» sur le site de The Comprehensive R Archive Network (CRAN).
1. Philosophie
Ma philosophie en matière d’enseignement de la science des données est motivée par l’objectif de fournir les outils nécessaires à l’exploration libre des données, plutôt que de simplement encourager l’utilisation de chaînes de traitement et de modèles statiques existants. Pour atteindre cet objectif, je vous présente cet atelier organisé selon trois principes :
- des données tabulaires : Je privilégie les données tabulaires parce qu’elles nous permettent de baser nos analyses sur des structures théoriques. Ces théories proviennent de domaines tels que l’informatique, les mathématiques, les statistiques et la philosophie.
- des fonctions générales et basées sur les théories : Je privilégie les fonctions qui viennent des « packages » comme
dplyret ggplot2 au lieu des fonctions anciennes ou fonctions qui ne marchent qu’avec une seul type de donnée. Cela nous aide également à nous adapter vers d’autres langages de programmation comme Python, SQL ou JavaScript. - une base solide : Nous nous concentrerons sur les opérations de base avant de passer à des tâches plus complexes.
Ces principes nous obligent à nous concentrer fortement sur les fonctions générales pour visualiser et manipuler des données relativement simples dans les premières sections. Mais, comme vous pouvez le voir dans la table des matières à droite, ce travail nous aidera à progresser rapidement vers des sujets plus complexes… et à les comprendre une fois que nous y serons arrivés.
2. Configuration
Comme toutes les compétences, la seule façon d’apprendre le langage R est de pratiquer en produisant du code vous-même. Pour vous aider à le faire, je vous fournis des exercices qui correspondent à chaque section ci-dessous. Pour les suivre, vous pouvez soit exécuter le code dans Google Colab, soit télécharger R, RStudio, et les exemples et données ci-dessous dans votre propre ordinateur.
Les exercices appliquent et approfondissent les thèmes abordés à l’aide de données supplémentaires.
Il y a des collections de fonctions supplementaires dans les packages. Il existe des milliers de paquets open source. Au cours de cet atelier, nous en utiliserons plusieurs. La méthode la plus courante pour télécharger un package depuis R est donnée par le code suivant, dans lequel nous téléchargeons le package ggplot2.
Après avoir téléchargé le package, ce qui ne doit être fait qu’une seule fois, nous devons le charger à l’aide du code suivant, qui est exécuté à chaque fois que nous démarrons une nouvelle session dans R.
library(ggplot2)Le code permettant de télécharger tous les paquets nécessaires à l’atelier est fourni dans les documents liés ci-dessus. Nous utiliserons la fonction library pour charger chaque bibliothèque requise avant sa première utilisation dans notre code.
3. Données tabulaires
Nous commençons avec des données de la production des voyelles anglaises qui viennent d’une étude très bien connue de 139 personnes en 1995 (Hillenbrand et al.). Je les ai choisies parce qu’elles sont suffisamment petites pour une première application mais assez complexes pour être intéressantes.
J’ai préparé cette collection dans un fichier CSV. Vous pouvez également enregistrer vos données au format CSV en utilisant tous les tableurs comme LibreOffice, Google Sheets ou Excel. Afin de charger ces données dans R, on peut utiliser la fonction read_csv2 du package readr. Cette fonction nécessite un argument qui spécifie le chemin d’accès au fichier par rapport au code. Voici un exemple de charger les données de la production des voyelles anglaises.
library(readr)
read_csv2("donnees/hillenbrand_voyelle_eng.csv")# A tibble: 1,668 × 9
id groupe api xsampa dur f0 f1 f2 f3
<dbl> <chr> <chr> <chr> <dbl> <dbl> <dbl> <dbl> <dbl>
1 1 fille æ { 257 238 630 2423 3166
2 1 fille ɑ A 212 241 831 1676 2602
3 1 fille ɔ O 242 247 725 1384 2642
4 1 fille ɛ E 184 214 713 2095 3129
5 1 fille e e 222 230 534 2690 3335
6 1 fille ɜ˞ 3' 227 240 608 1733 2159
7 1 fille ɪ I 197 263 551 2393 3324
8 1 fille i i 237 277 554 3022 3541
9 1 fille o o 267 250 693 1235 2850
10 1 fille ʊ U 184 247 553 1495 2868
# ℹ 1,658 more rowsNous voyons que cette fonction renvoie un objet qui s’appelle un « tibble ». Dans R, un tibble est la structure dans laquelle on charge les données structurées sous forme de tableau. L’objet ci-dessus a 1668 lignes et 8 colonnes. Chaque ligne montre les métadonnées d’un locuteur et les mesures phonétiques d’une voyelle. Par défaut, nous ne voyons que les dix premières lignes. Pour chaque colonne, il y a un nom (id, groupe, etc.) et un type de données. Les colonnes numériques ont le type <dbl>, une abréviation de « double » dans l’expression « nombre flottante à virgule double précision ». Les colonnes qui contiennent des chaines de caractères ont le type <chr>, une abréviation de mot « caractère » en anglais. Nous allons voir que ces structures sont essentielles pour toutes les étapes de l’analyse de données en R.
Dans le code ci-dessus, nous avons créé et imprimé un tibble. Cependant, après l’exécution du code le tibble n’existe plus dans R. Afin de le sauvegarder, nous devons attribuer la sortie de la fonction à un nom à l’aide d’une flèche (signe inférieur et signe moins). Ici, nous sauvegardons le tibble dans l’objet phone.
phone <- read_csv2("donnees/hillenbrand_voyelle_eng.csv")Puis, après exécution, nous pouvons utiliser l’objet phone dans n’importe quelle autre tâche. Par exemple, dans la section suivante, nous allons visualiser ces données avec un langage adapté à l’exploration d’informations quantitatives.
4. Visualiser
La visualisation est une étape essentielle dans l’exploration de données. Nous appliquerons un langage général, qui s’appelle la « grammaire des graphiques », pour décrire et coder les visualisations dans R. Nous avons besoin d’un peu de la théorie avant de continuer, mais cette construction rend les visualisations complexes relativement faciles à réaliser.
Dans la grammaire des graphiques, une couche consiste de trois éléments :
- un tibble : L’objet qui contient l’information à visualiser.
- une géométrie : La forme qui correspond à chaque ligne du tibble. La visualisation consiste en une forme pour chaque ligne.
- des esthétiques : Les associations entre colonnes du tibble et les paramètres de chaque forme.
Une visualisation consiste d’une ou plusieurs couches. Un exemple sert à clarifier la manière dont ces parties peuvent correspondre aux éléments graphiques. Voici le code pour créer une visualisation de notre tibble phone qui a un point pour chaque ligne avec une position horizontale indiquée par la fréquence fondamentale (f0) et une position verticale indiquée par la durée de la voyelle (dur).
library(ggplot2)
phone |>
ggplot() +
geom_point(aes(x = f0, y = dur))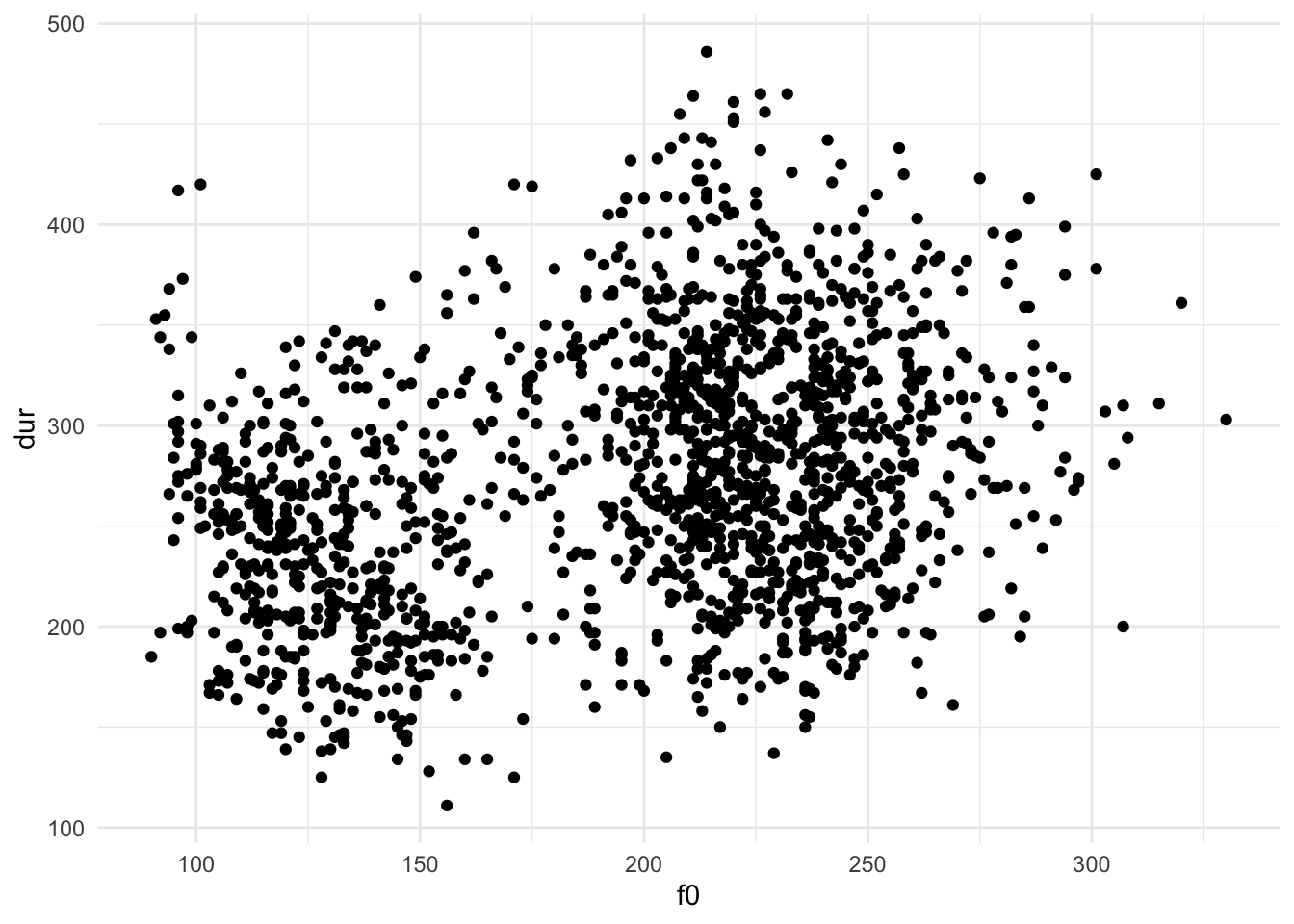
Dans cet exemple, nous commençons avec le nom d’un tibble (phone) suivi par le symbole |>. Ce symbole s’appelle un « pipe ». Il passe le tibble aux prochaines étapes. Cette construction nous permettre d’adapter l’order des fonctions et de les rendre plus facile à lire : p(h(g(f(x)))) devient x |> f() |> g() |> h() |> p().
Nous continuons avec la fonction ggplot() pour indiquer que nous voulons créer une visualisation. Dans la dernière ligne, nous appliquons la fonction geom_point pour spécifier la géométrie. À l’intérieur de la fonction, nous mettons la fonction aes() (pour aesthetic, esthétique en anglais) avec les associations entre les noms de colonnes et les positions horizontale et verticale. Par convention, la grammaire des graphiques utilise la lettre x pour la dimension horizontale et y pour la dimension verticale.
Comme l’exemple ci-dessus, la géométrie des points a deux esthétiques requises (x et y). Il y a d’autres esthétiques facultatives qu’on peut ajouter pour améliorer l’information portée par la visualisation. Par exemple, il y a une esthétique de la couleur qui permet de changer la couleur de chaque point en fonction d’une colonne du tibble. Voici un exemple où la couleur indique le groupe du locuteur ou de la locutrice.
phone |>
ggplot() +
geom_point(aes(x = f0, y = dur, colour = groupe))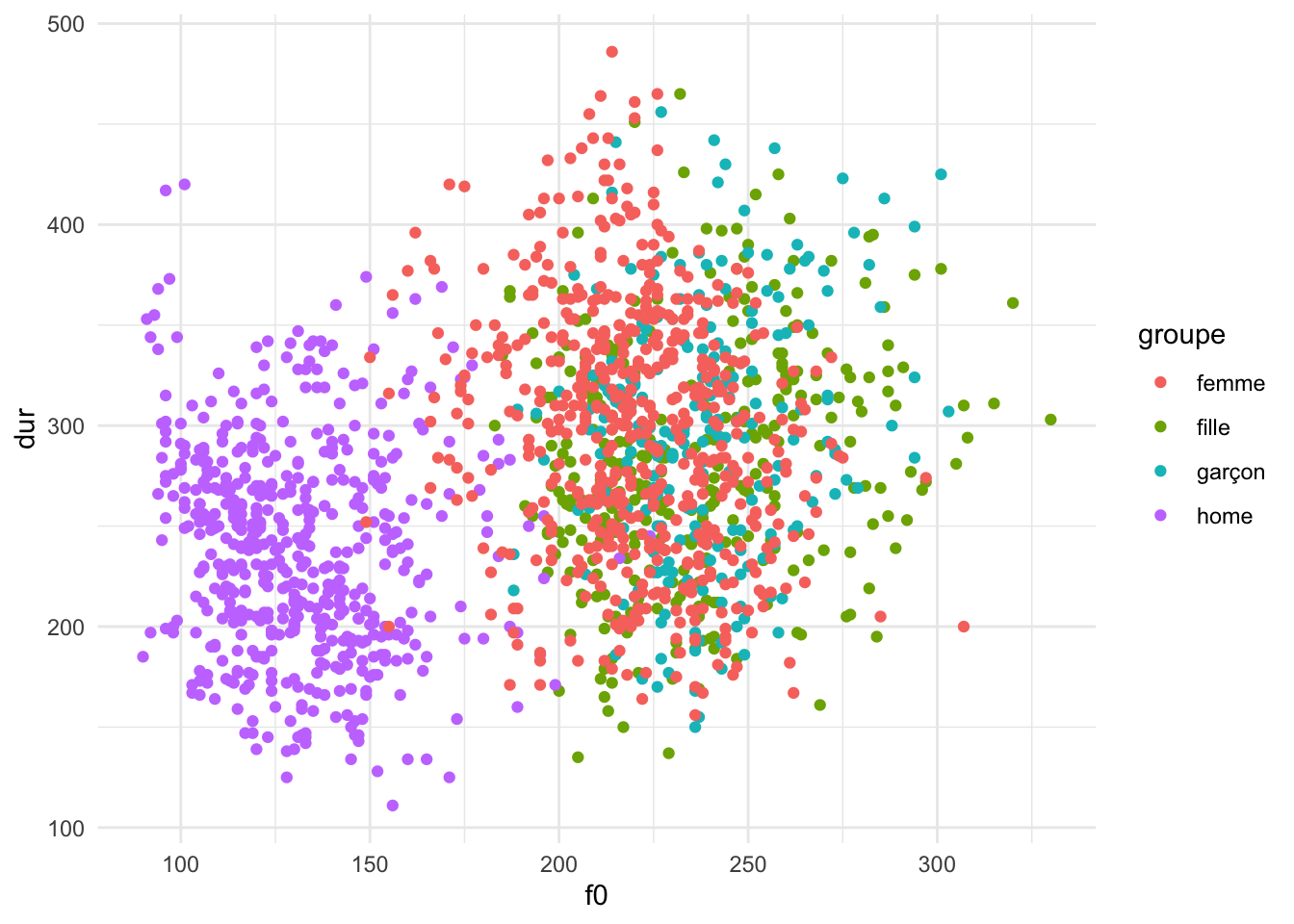
Déjà, cette visualisation montre certaines correspondances entre les colonnes. Nous voyons que la différence de la fréquence fondamentale correspond à une séparation les hommes et les autres. Et, qu’il peut exister une correspondance où les hommes ont des durées légèrement plus petites que les femmes et les enfants.
Le lien entre les couleurs et les groupes n’est pas explicit dans notre code. Le système de la grammaire de graphiques peut choisir les couleurs automatiquement. C’était la même chose pour les positions horizontale et verticale. Mais, souvent on a besoin de les changer. Pour spécifier la relation entre les esthétiques et les éléments réels d’un graphique, on peut appliquer les échelles. Les échelles peuvent être ajoutées comme une autre ligne de notre code. Voici un exemple où nous modifions les couleurs à l’aide d’une palette adaptée aux personnes atteintes de daltonisme.
phone |>
ggplot() +
geom_point(aes(x = f0, y = dur, colour = groupe)) +
scale_colour_viridis_d()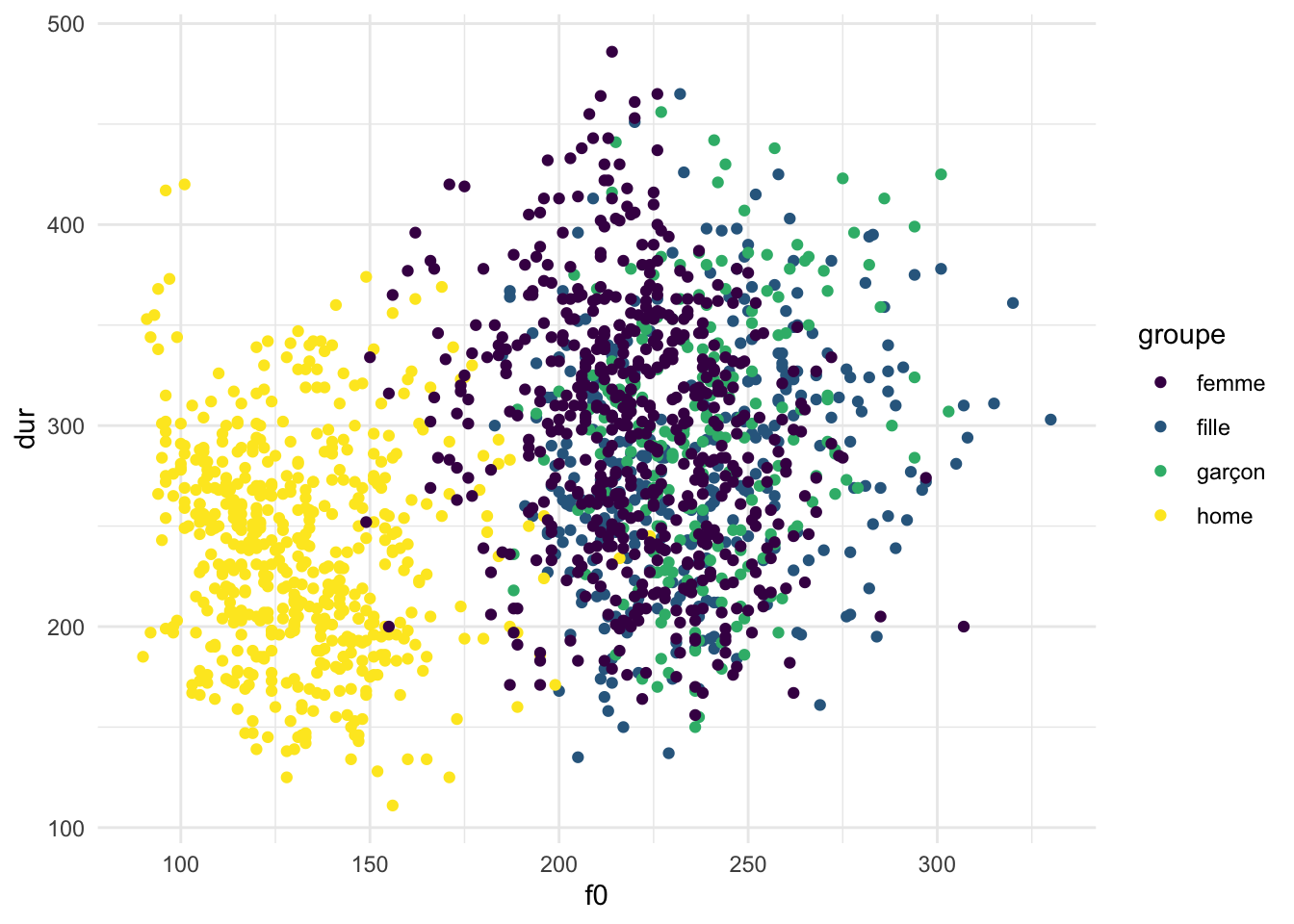
Voyons maintenant la visualisation la plus courante pour les données phonétiques qui fournit la relation entre les deux premiers formants F1 et F2. Ce graphique est au fond la même chose : les points avec les noms f2 et f1, respectivement, attribués aux esthétiques x et y. Mais, il y a une complexité. Afin de correspondre à la forme de la langue pour quelqu’un qui regarde vers sa droite, nous devons inverser le sens des axes. Cela nécessite l’application des échelles scale_x_reverse() et scale_y_reverse(). L’exemple suivant donne la forme correcte.
phone |>
ggplot() +
geom_point(aes(x = f2, y = f1)) +
scale_x_reverse() +
scale_y_reverse()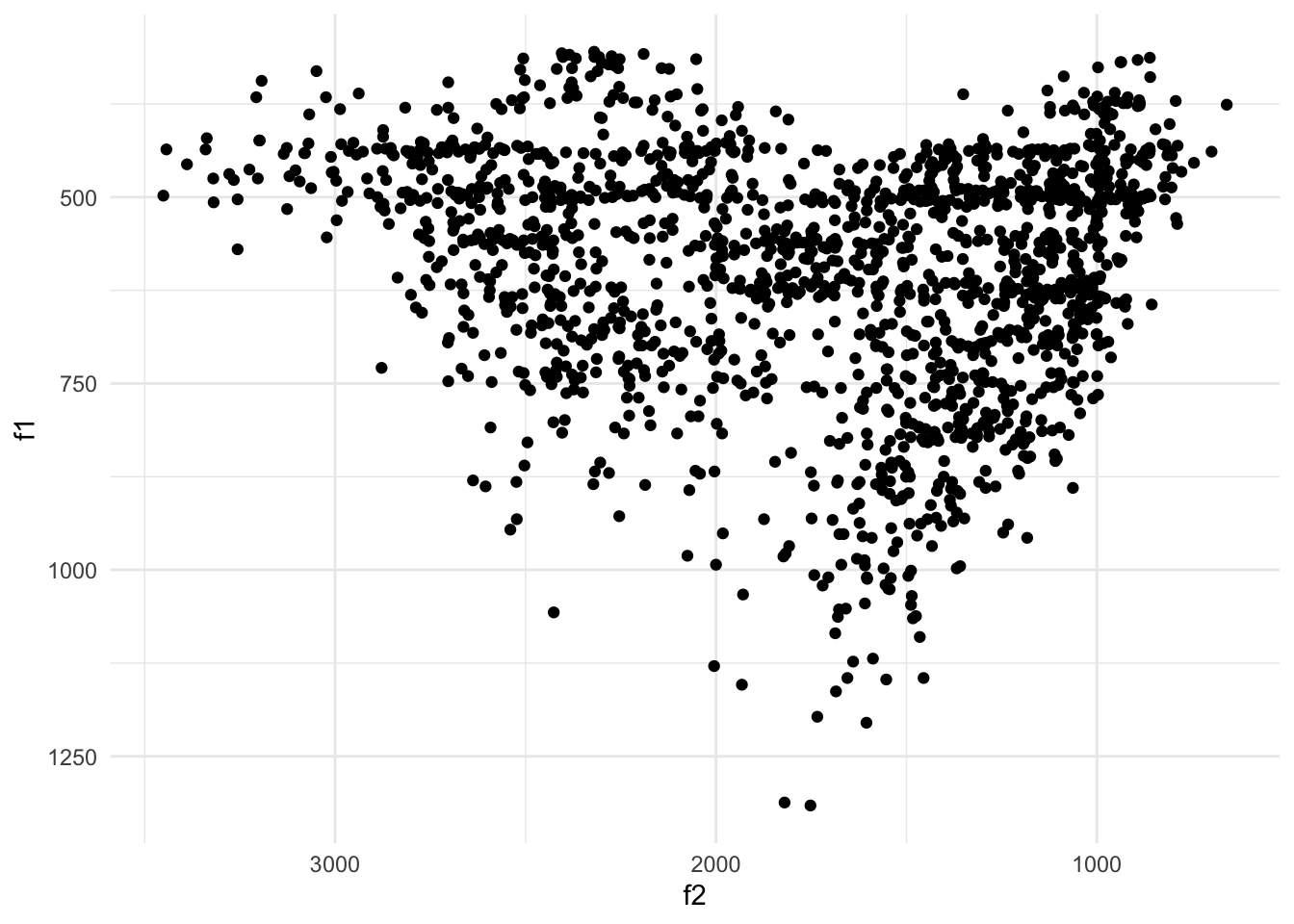
Cette visualisation montre la forme triangulaire classique de l’espace vocalique. Supposons qu’on veuille voir quelles voyelles correspondent à ces points. Comment pourrions-nous faire cela ? Nous devons appliquer une nouvelle géométrie : geom_text. Elle ne crée pas de points pour chaque ligne de données. En revanche, la géométrie de texte place directement des caractères dans le graphique. Nous devons donner une esthétique nouvelle pour indiquer la colonne qui correspond à ces caractères. Voici la façon d’avoir une visualisation avec les symboles API à la place des points.
phone |>
ggplot() +
geom_text(aes(x=f2, y=f1, label = api)) +
scale_x_reverse() +
scale_y_reverse()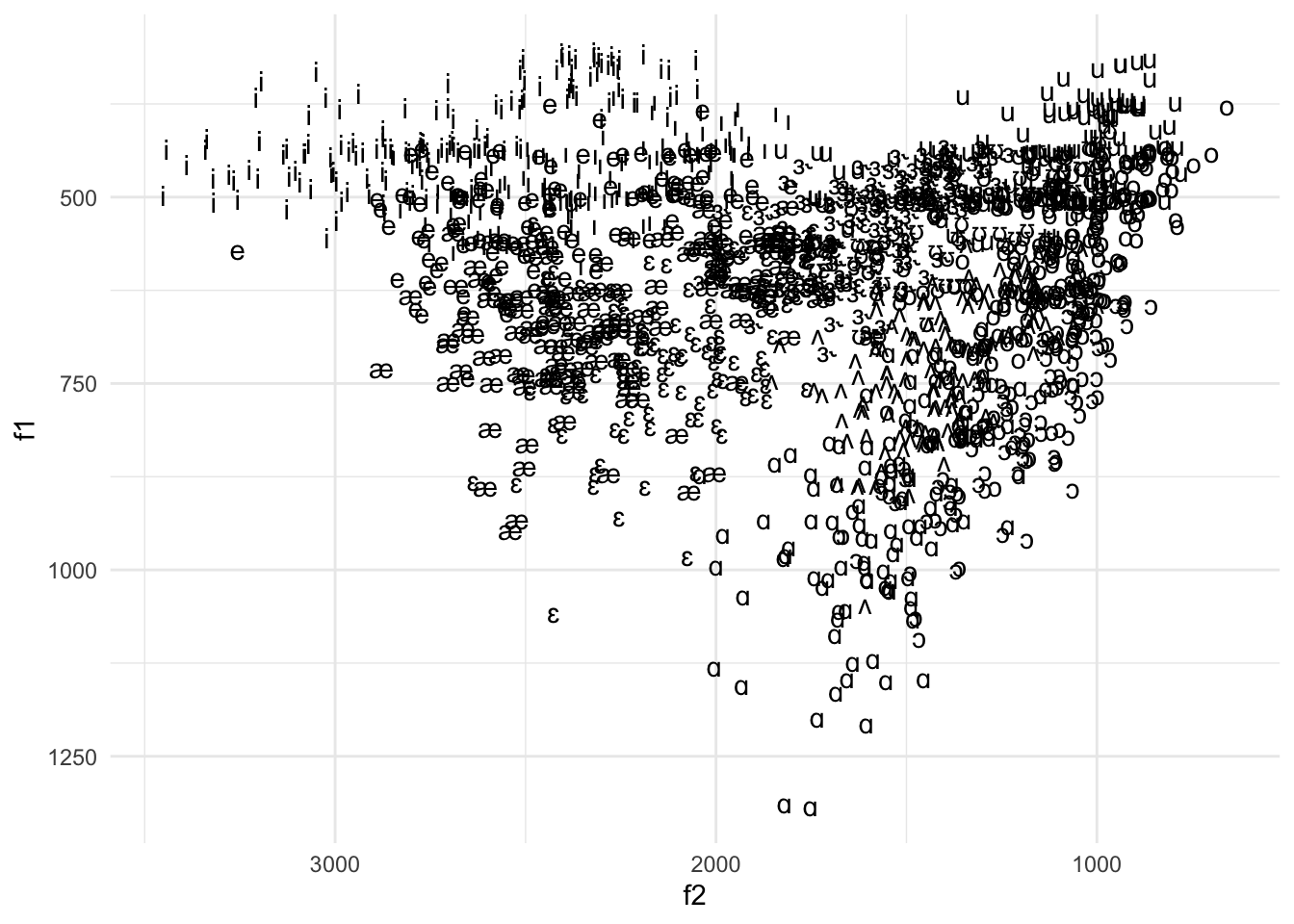
Nous pouvons sauvgarder une visualisation avec la fonction ggsave. Par défaut, le dernier graphique affiché est enregistré.
ggsave("ma_visualisation.png", height=12, width=12, units="cm")Il existe beaucoup de géométries, d’esthétiques et d’échelles pour élargir les possibilités de visualisations dans la grammaire de graphiques. Vous pouvez consulter les références suivants : [1; 2].
Nous avons vu les éléments centraux de la grammaire de graphiques. Dans le but d’aller plus loin, nous continuons en étudiant les méthodes pour modifier les tibbles avec les fonctions liées aux bases de données.
5. Manipuler un tableau
Souvent, il faut transformer un tableau de données en un autre tableau avec des éléments différents ou réorganiser. Dans R, nous pouvons manipuler les tableaux avec une collection de fonctions qui s’appellent des « verbes ». Ces fonctions ont la même structure : on les donne un tibble puis on reçoit un nouveau tibble. Cette structure permet d’appliquer un nombre quelconque de fonctions à un tibble. Il existe environ 50 verbes. Heureusement, nous n’avons besoin d’en apprendre que 12 pour effectuer toutes les opérations possibles. Dans cette section, nous commençons avec les 8 premiers verbes.
Le verbe slice_head tranche les n premières lignes d’un tibble, où n est un argument dans la fonction. Comme tous les verbes, nous utilisons un pipe (|>) pour donner l’objet de données à la fonction.
library(dplyr)
phone |>
slice_head(n = 4)# A tibble: 4 × 9
id groupe api xsampa dur f0 f1 f2 f3
<dbl> <chr> <chr> <chr> <dbl> <dbl> <dbl> <dbl> <dbl>
1 1 fille æ { 257 238 630 2423 3166
2 1 fille ɑ A 212 241 831 1676 2602
3 1 fille ɔ O 242 247 725 1384 2642
4 1 fille ɛ E 184 214 713 2095 3129Le verbe filter retient les lignes selon une relation entre les valeurs. Pour appliquer cette fonction, on place une expression à l’intérieur avec les noms des colonnes. Les lignes où l’expression est vraie seront conservées. Voici un exemple pour trouver les lignes de la voyelle «u».
phone |>
filter(api == "u")# A tibble: 139 × 9
id groupe api xsampa dur f0 f1 f2 f3
<dbl> <chr> <chr> <chr> <dbl> <dbl> <dbl> <dbl> <dbl>
1 1 fille u u 253 246 502 1540 3176
2 2 fille u u 327 287 559 1312 2870
3 3 fille u u 304 194 506 2378 2991
4 4 fille u u 292 258 503 1104 3346
5 5 fille u u 260 240 481 1226 3131
6 6 fille u u 303 330 609 1658 2644
7 7 fille u u 262 228 440 1124 3117
8 8 fille u u 211 255 503 1119 3100
9 9 fille u u 275 215 463 1676 2976
10 10 fille u u 246 197 430 1448 2896
# ℹ 129 more rowsPour réorganiser des lignes par les valeurs dans une ou plusieurs colonnes, nous appliquons la fonction arrange. Nous indiquons simplement le nom de la colonne dans la fonction.
phone |>
arrange(dur)# A tibble: 1,668 × 9
id groupe api xsampa dur f0 f1 f2 f3
<dbl> <chr> <chr> <chr> <dbl> <dbl> <dbl> <dbl> <dbl>
1 74 home ʊ U 111 156 463 1086 2453
2 71 home ɛ E 125 128 636 1893 2765
3 90 home u u 125 171 374 887 2478
4 74 home ʌ V 128 152 622 1285 2472
5 59 home ɪ I 134 145 424 1913 2556
6 74 home ɪ I 134 165 440 2119 2694
7 75 home ʊ U 134 160 500 1067 2435
8 7 fille ɛ E 135 205 605 2445 3265
9 22 fille ɪ I 137 229 447 2645 3302
10 64 home ɛ E 138 128 615 1624 2265
# ℹ 1,658 more rowsLa réorganisation des lignes, par défaut, trie les lignes par ordre croissant. Pour un ordre décroissant, nous ajoutons la fonction desc.
phone |>
arrange(desc(dur))# A tibble: 1,668 × 9
id groupe api xsampa dur f0 f1 f2 f3
<dbl> <chr> <chr> <chr> <dbl> <dbl> <dbl> <dbl> <dbl>
1 93 femme æ { 486 214 624 2442 3091
2 19 fille e e 465 232 463 2745 3155
3 111 femme ɔ O 465 226 698 1127 2886
4 93 femme ɔ O 464 211 760 1225 2796
5 115 femme æ { 461 220 646 2406 3283
6 31 garçon æ { 456 227 682 2638 3510
7 126 femme ɑ A 455 208 952 1676 2862
8 93 femme e e 453 220 477 2704 3102
9 24 fille æ { 451 220 643 2434 3326
10 93 femme ɑ A 443 209 883 1682 2962
# ℹ 1,658 more rowsAfin de démontrer l’application de plusieurs verbes, notons qu’il est souvent efficace d’appliquer arrange puis slice_head pour trouver les lignes des valeurs extrêmes. Nous voyons que chaque ligne, sauf la dernière, a un pipe à la fin.
phone |>
arrange(desc(f1)) |>
slice_head(n = 10)# A tibble: 10 × 9
id groupe api xsampa dur f0 f1 f2 f3
<dbl> <chr> <chr> <chr> <dbl> <dbl> <dbl> <dbl> <dbl>
1 41 garçon ɑ A 299 233 1316 1752 3113
2 29 garçon ɑ A 298 208 1312 1820 3308
3 22 fille ɑ A 238 228 1205 1605 2708
4 35 garçon ɑ A 321 245 1197 1734 3187
5 123 femme ɑ A 283 241 1163 1685 3250
6 38 garçon ɑ A 317 200 1154 1932 3044
7 25 fille ɑ A 270 223 1147 1553 2877
8 45 garçon ɑ A 259 234 1145 1655 3062
9 138 femme ɑ A 326 224 1145 1455 3272
10 44 garçon ɑ A 220 235 1129 2005 2826Le verbe mutate ajoute une colonne au tableau. Cela marche avec un nom de nouvelle colonne et la formule pour créer à partir d’autres colonnes. Par exemple, ci-dessous on a un exemple de la création d’une colonne dur_s (durée en secondes) qui est définie par la durée (en millisecondes) divisée par 1000.
phone |>
mutate(dur_s = dur / 1000)# A tibble: 1,668 × 10
id groupe api xsampa dur f0 f1 f2 f3 dur_s
<dbl> <chr> <chr> <chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
1 1 fille æ { 257 238 630 2423 3166 0.257
2 1 fille ɑ A 212 241 831 1676 2602 0.212
3 1 fille ɔ O 242 247 725 1384 2642 0.242
4 1 fille ɛ E 184 214 713 2095 3129 0.184
5 1 fille e e 222 230 534 2690 3335 0.222
6 1 fille ɜ˞ 3' 227 240 608 1733 2159 0.227
7 1 fille ɪ I 197 263 551 2393 3324 0.197
8 1 fille i i 237 277 554 3022 3541 0.237
9 1 fille o o 267 250 693 1235 2850 0.267
10 1 fille ʊ U 184 247 553 1495 2868 0.184
# ℹ 1,658 more rowsLe verbe select fait une sélection de colonnes selon fonction de leur nom. Il est utile si la taille d’un tableau devient trop grande.
phone |>
select(f1, f2)# A tibble: 1,668 × 2
f1 f2
<dbl> <dbl>
1 630 2423
2 831 1676
3 725 1384
4 713 2095
5 534 2690
6 608 1733
7 551 2393
8 554 3022
9 693 1235
10 553 1495
# ℹ 1,658 more rowsNous finissons cette section avec deux verbes qui fonctionnent souvent ensemble : group_by et summarise. Comme mutate, le verbe summarise permet de créer de nouvelles colonnes. Mais, il réduit les lignes à un sommaire avec l’application de fonctions comme mean (la moyenne) ou sd (l’écart-type). La fonction group_by indique par quelle colonne (ou colonnes) le sommaire est appliqué. Cet exemple peut clarifier la relation entre les deux. Voici le code pour calculer les moyennes de F1 et F2 selon la voyelle.
phone |>
group_by(api) |>
summarise(
f1_m = mean(f1),
f2_m = mean(f2)
)# A tibble: 12 × 3
api f1_m f2_m
<chr> <dbl> <dbl>
1 e 526. 2426.
2 i 412. 2725.
3 o 551. 1030.
4 u 445. 1167.
5 æ 663. 2257.
6 ɑ 891. 1508.
7 ɔ 767. 1173.
8 ɛ 686. 2050.
9 ɜ˞ 529. 1564.
10 ɪ 476. 2323.
11 ʊ 520. 1286.
12 ʌ 708. 1380.Nous pouvons enregistrer le résultat d’une manipulation de données à l’aide d’une flèche (<-). Celui-ci peut ensuite être enregistré sous forme de fichier que nous pouvons ouvrir dans d’autres logiciels à l’aide de write_csv2. Voici un exemple
phone_moyenne <- phone |>
group_by(api) |>
summarise(
f1_m = mean(f1),
f2_m = mean(f2)
)
write_csv2(phone_moyenne, "donnees/phone_moyenne.csv")Le pouvoir de la fonction summarise devient plus clair en voyant l’application aux visualisations. Avec une combinaison des verbes et couches de graphiques, nous avons les outils pour visualiser les formants moyens de chaque voyelle dans les données.
phone |>
group_by(api) |>
summarise(
f1_m = mean(f1),
f2_m = mean(f2)
) |>
ggplot() +
geom_point(aes(x=f2_m, y=f1_m), size = 8) +
geom_text(aes(x=f2_m, y=f1_m, label = api), colour="#fff") +
scale_x_reverse() +
scale_y_reverse() 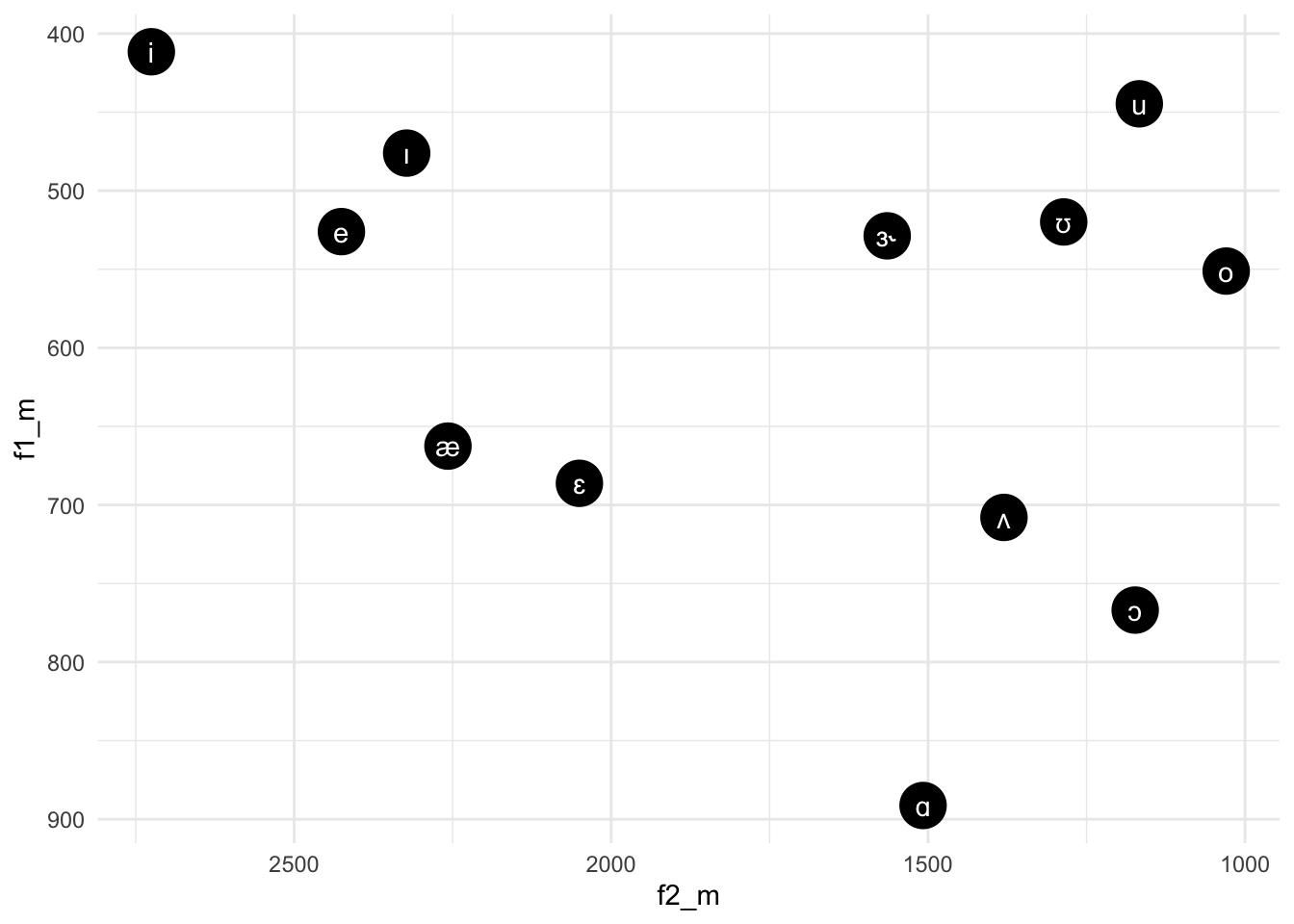
Je tiens à mentionner ici une fonction R de base très efficace pour explorer les données : table. Elle peut compter le nombre de valeurs dans une colonne, par exemple (notez le symbole $ entre le nom de la table et le nom de la colonne) :
table(phone$api)
æ ɑ e ɛ ɜ˞ i ɪ o ɔ u ʊ ʌ
139 139 139 139 139 139 139 139 139 139 139 139 Ou bien, elle peut également compter les combinaisons de deux colonnes :
table(phone$api, phone$groupe)
femme fille garçon home
æ 48 27 19 45
ɑ 48 27 19 45
e 48 27 19 45
ɛ 48 27 19 45
ɜ˞ 48 27 19 45
i 48 27 19 45
ɪ 48 27 19 45
o 48 27 19 45
ɔ 48 27 19 45
u 48 27 19 45
ʊ 48 27 19 45
ʌ 48 27 19 45Maintenant, nous avons une base solide de verbes et de fonctions de visualisation. Tous ces éléments sont au cœur de la science des données. Dans la section suivante, nous ajoutons des fonctions de modélisation.
6. Les modèles statistiques
Maintenant que nous savons comment manipuler les données, nous pouvons commencer à travailler avec de nouveaux ensembles de données. Ici, nous chargeons un ensemble de données de enregistreur de frappe dans lequel chaque saisi de texte effectuée lors d’une session d’écriture est enregistrée.
touches <- read_csv2("donnees/keylog-touches.csv.bz2", na="NA")
touches# A tibble: 1,145,051 × 7
id t0 t1 dur dur_apres touche code
<chr> <dbl> <dbl> <dbl> <dbl> <chr> <chr>
1 R_00RbUqO7jXLDItP 20914. 20978. 64.4 80.1 "I" KeyI
2 R_00RbUqO7jXLDItP 21146. 21226. 80.1 55.8 "f" KeyF
3 R_00RbUqO7jXLDItP 21234. 21290. 55.8 80.2 "" Space
4 R_00RbUqO7jXLDItP 22074. 22154. 80.2 88.2 "I" KeyI
5 R_00RbUqO7jXLDItP 22306. 22394. 88.2 64.3 "" Space
6 R_00RbUqO7jXLDItP 23674. 23739. 64.3 56.1 "c" KeyC
7 R_00RbUqO7jXLDItP 23818. 23874. 56.1 46.6 "o" KeyO
8 R_00RbUqO7jXLDItP 24044. 24090. 46.6 64 "u" KeyU
9 R_00RbUqO7jXLDItP 25066. 25130. 64 79.8 "l" KeyL
10 R_00RbUqO7jXLDItP 25170. 25250 79.8 72.3 "d" KeyD
# ℹ 1,145,041 more rowsUne fois les données chargées, le bloc suivant réalise une étape de préparation où nous filtrons les observations pour ne retenir que deux types précis de touches, ici l’espace et le point. Cette sélection permet de comparer plus facilement la durée de frappe de ces deux catégories.
touches_sub <- touches |>
filter(code %in% c("Space", "Period"))Après cette préparation, nous appliquons un test statistique de comparaison de moyennes. Le « test de Student » permet d’évaluer si les durées de frappe mesurées diffèrent de manière significative entre les deux types de touches retenus. L’idée est de vérifier si l’espace et le point présentent des temps d’appui systématiquement différents, ce qui pourrait refléter des habitudes de frappe ou des contraintes mécaniques spécifiques.
t.test(dur ~ code, data = touches_sub)
Welch Two Sample t-test
data: dur by code
t = 21.903, df = 11523, p-value < 2.2e-16
alternative hypothesis: true difference in means between group Period and group Space is not equal to 0
95 percent confidence interval:
6.915632 8.275116
sample estimates:
mean in group Period mean in group Space
86.04275 78.44737 Les résultats montrent qu’il existe une différence significative, et que la durée moyenne d’un point (86.04 ms) est plus grande que celle d’un espace (78.45 ms).
Le bloc suivant étend l’analyse à un autre angle. Cette fois, il s’agit d’un test ANOVA à un facteur qui utilise l’identifiant de la session comme variable explicative. L’objectif est d’estimer si la durée de frappe varie beaucoup d’un individu à l’autre. Si la variabilité est importante, cela peut indiquer que les différences interpersonnelles jouent un rôle déterminant dans la vitesse ou le style de frappe.
oneway.test(dur ~ id, data = touches)
One-way analysis of means (not assuming equal variances)
data: dur and id
F = 320.45, num df = 822, denom df = 349612, p-value < 2.2e-16Là encore, nous voyons qu’il existe une différence de la moyenne de la durée selon la session.
Enfin, le dernier bloc propose une analyse par régression linéaire. Il s’agit ici de comprendre comment la durée de frappe d’une touche pourrait être associée à la durée qui suit immédiatement cette frappe. Le modèle construit cherche à déterminer si, lorsque l’on appuie plus ou moins longtemps sur une touche, cela influence la rapidité avec laquelle on enchaîne la frappe suivante.
summary(lm(dur_apres ~ dur, data = touches))
Call:
lm(formula = dur_apres ~ dur, data = touches)
Residuals:
Min 1Q Median 3Q Max
-768972 -17 1 20 9042
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 71.33665 1.64052 43.484 < 2e-16 ***
dur 0.06564 0.01909 3.438 0.000586 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 765.1 on 1145049 degrees of freedom
Multiple R-squared: 1.032e-05, Adjusted R-squared: 9.45e-06
F-statistic: 11.82 on 1 and 1145049 DF, p-value: 0.0005857Les résultats montrent qu’il existe une relation positive entre la durée d’une touche et la durée de la prochaine touche. Mais, le coefficient de détermination linéaire (également connu sous le nom de « pourcentage de variance expliquée » ou, en anglais, « Multiple R-squared ») est très petit, ce qui indique que cette relation n’est pas trop forte.
7. Plusieurs tableaux
Dans cette section, nous apprendrons les derniers verbes dont nous avons besoin. Ces verbes nous aident à combiner l’information dans plusieurs tableaux et complètent l’essentiel pour notre boîte à outils des verbes.
Nous commençons par charger un second tableau de données contenant des informations descriptives sur les utilisateurs dans les sessions de frappe. Ce fichier regroupe généralement des métadonnées telles que la langue, le niveau déclaré ou d’autres caractéristiques permettant de mieux contextualiser les mesures.
meta <- read_csv2("donnees/keylog-meta.csv.bz2")
meta# A tibble: 823 × 4
id age lang cefr
<chr> <dbl> <chr> <chr>
1 R_2EGIsZARLydD3Uc 25 Italian C1/C2
2 R_1obCaysaZCWZXoG 22 Spanish B1/B2
3 R_3fqTek829k38iCk 22 Polish B1/B2
4 R_brxD7Q5ZnPW8Gn7 43 English C1/C2
5 R_1k1RE78cBbZyZMA 23 Polish B1/B2
6 R_1NwuZMzRkVIR0WT 32 English C1/C2
7 R_2t8LOS9nQDBQPA8 24 Spanish C1/C2
8 R_239Q0X5YLwB7U6Z 28 English C1/C2
9 R_10xbkjEmnsusfb1 32 Polish B1/B2
10 R_10CbLBzAnYKgWxB 21 Polish B1/B2
# ℹ 813 more rowsNous importons ensuite un troisième tableau, cette fois centré sur des mesures liées aux mots eux-mêmes. Il peut s’agir, par exemple, de durées de frappe associées à chaque mot tapé, ce qui fournit une information plus synthétique que l’analyse touche par touche.
mots <- read_csv2("donnees/keylog-mots.csv.bz2")
mots# A tibble: 210,337 × 6
id mot char_mot dur_mot d1 d2
<chr> <chr> <dbl> <dbl> <dbl> <dbl>
1 R_00RbUqO7jXLDItP If 2 312. 928. 848.
2 R_00RbUqO7jXLDItP I 1 80.2 1600. 1520
3 R_00RbUqO7jXLDItP could 5 1576. 2168. 2088.
4 R_00RbUqO7jXLDItP choose 6 945. 976. 904.
5 R_00RbUqO7jXLDItP to 2 200. 930. 849.
6 R_00RbUqO7jXLDItP be 2 151 528. 456.
7 R_00RbUqO7jXLDItP any 3 440. 264 168.
8 R_00RbUqO7jXLDItP animal 6 1560 976. 888
9 R_00RbUqO7jXLDItP for 3 264. 248 176.
10 R_00RbUqO7jXLDItP one 3 312 1120. 1048.
# ℹ 210,327 more rowsUne fois ces deux tableaux disponibles, nous effectuons une jonction entre eux à partir d’un identifiant commun. Cette opération permet de combiner les caractéristiques présentes dans les métadonnées avec les observations relatives aux mots, enrichissant ainsi chaque ligne d’information contextuelle supplémentaire. Le résultat est une table fusionnée où les durées ou autres mesures des mots peuvent être interprétées en fonction des profils utilisateurs. Voici un exemple où nous utilisons l’identifiant du participant (id) pour les fusionner.
mots |>
left_join(meta, by = "id")# A tibble: 210,337 × 9
id mot char_mot dur_mot d1 d2 age lang cefr
<chr> <chr> <dbl> <dbl> <dbl> <dbl> <dbl> <chr> <chr>
1 R_00RbUqO7jXLDItP If 2 312. 928. 848. 28 Italian C1/C2
2 R_00RbUqO7jXLDItP I 1 80.2 1600. 1520 28 Italian C1/C2
3 R_00RbUqO7jXLDItP could 5 1576. 2168. 2088. 28 Italian C1/C2
4 R_00RbUqO7jXLDItP choose 6 945. 976. 904. 28 Italian C1/C2
5 R_00RbUqO7jXLDItP to 2 200. 930. 849. 28 Italian C1/C2
6 R_00RbUqO7jXLDItP be 2 151 528. 456. 28 Italian C1/C2
7 R_00RbUqO7jXLDItP any 3 440. 264 168. 28 Italian C1/C2
8 R_00RbUqO7jXLDItP animal 6 1560 976. 888 28 Italian C1/C2
9 R_00RbUqO7jXLDItP for 3 264. 248 176. 28 Italian C1/C2
10 R_00RbUqO7jXLDItP one 3 312 1120. 1048. 28 Italian C1/C2
# ℹ 210,327 more rowsLe bloc suivant exploite cette jonction pour procéder à un regroupement selon une variable décrivant le niveau de compétence linguistique. Après avoir regroupé les observations selon ce critère, on calcule la médiane d’une mesure temporelle spécifique, ce qui permet d’obtenir un indicateur robuste de la performance dactylographique pour chaque niveau. Le tri final met en évidence les niveaux pour lesquels la médiane est la plus élevée, facilitant la comparaison globale.
mots |>
left_join(meta, by = "id") |>
group_by(cefr) |>
summarise(mu = median(d1)) |>
arrange(desc(mu))# A tibble: 3 × 2
cefr mu
<chr> <dbl>
1 A1/A2 789.
2 B1/B2 592
3 C1/C2 448 Enfin, sur un principe similaire, l’analyse est répétée en regroupant cette fois les données selon la langue déclarée. L’objectif est d’examiner si la performance sur les mots varie sensiblement d’une langue maternelle à l’autre.
mots |>
left_join(meta, by = "id") |>
group_by(lang) |>
summarise(mu = median(d1)) |>
arrange(desc(mu))# A tibble: 8 × 2
lang mu
<chr> <dbl>
1 Greek 608.
2 Polish 520
3 Portuguese 503.
4 Spanish 499
5 Italian 486.
6 French 447.
7 German 441
8 English 435 Nous voyons que les étudiants anglais ont tapé le plus vite.
8. Fenêtres glissantes
Nous avons traité les analyses horizontales dans lesquelles nous ne voyons que les relations entres les valeurs d’une ligne. Avec summarise et les fonctions pour les modèles statistiques, nous avons egalement traité les analyses verticales dans lesquelles nous traitons toutes les valeurs d’une colonne sur toutes les lignes, ou tous les groupes de lignes. Dans cette section, nous allons plus loin en utilisant ce que l’on appelle des fonctions à fenêtre glissante. Ces fonctions nous aident à trouver des relations entre les observations en fonction de l’ordre des lignes dans nos données. Des fonctions à fenêtre glissante sont très utiles lorsque l’on travaille avec des séries chronologiques, comme c’est souvent le cas en linguistique.
Nous commençons par créer un tableau simplifié contenant uniquement les variables essentielles pour illustrer l’usage des fonctions de fenêtre.
touches_min <- select(touches, id, t0, t1, dur, touche, code)
touches_min# A tibble: 1,145,051 × 6
id t0 t1 dur touche code
<chr> <dbl> <dbl> <dbl> <chr> <chr>
1 R_00RbUqO7jXLDItP 20914. 20978. 64.4 "I" KeyI
2 R_00RbUqO7jXLDItP 21146. 21226. 80.1 "f" KeyF
3 R_00RbUqO7jXLDItP 21234. 21290. 55.8 "" Space
4 R_00RbUqO7jXLDItP 22074. 22154. 80.2 "I" KeyI
5 R_00RbUqO7jXLDItP 22306. 22394. 88.2 "" Space
6 R_00RbUqO7jXLDItP 23674. 23739. 64.3 "c" KeyC
7 R_00RbUqO7jXLDItP 23818. 23874. 56.1 "o" KeyO
8 R_00RbUqO7jXLDItP 24044. 24090. 46.6 "u" KeyU
9 R_00RbUqO7jXLDItP 25066. 25130. 64 "l" KeyL
10 R_00RbUqO7jXLDItP 25170. 25250 79.8 "d" KeyD
# ℹ 1,145,041 more rowsLe bloc suivant illustre l’usage de plusieurs fonctions de fenêtre classiques comme lag et lead, fréquemment utilisées dans l’analyse de séries temporelles ou de séquences ordonnées. Elles nous permettent de « voir » les lignes avant et après. L’argument n donne le nombre de lignes auxquelles accéder.
touches_min |>
arrange(id, t0) |>
group_by(id) |>
mutate(
diff_avant = t0 - lag(t0, n=1),
diff_apres = lead(t0, n=1) - t0,
gap_avant = t0 - lag(t1, n=1),
gap_apres = lead(t0, n=1) - t1,
)# A tibble: 1,145,051 × 10
# Groups: id [823]
id t0 t1 dur touche code diff_avant diff_apres gap_avant
<chr> <dbl> <dbl> <dbl> <chr> <chr> <dbl> <dbl> <dbl>
1 R_00RbUqO7j… 20914. 20978. 64.4 "I" KeyI NA 232. NA
2 R_00RbUqO7j… 21146. 21226. 80.1 "f" KeyF 232. 88.1 168.
3 R_00RbUqO7j… 21234. 21290. 55.8 "" Space 88.1 840. 8
4 R_00RbUqO7j… 22074. 22154. 80.2 "I" KeyI 840. 232. 784
5 R_00RbUqO7j… 22306. 22394. 88.2 "" Space 232. 1368. 152.
6 R_00RbUqO7j… 23674. 23739. 64.3 "c" KeyC 1368. 144. 1280.
7 R_00RbUqO7j… 23818. 23874. 56.1 "o" KeyO 144. 225. 79.8
8 R_00RbUqO7j… 24044. 24090. 46.6 "u" KeyU 225. 1023. 169.
9 R_00RbUqO7j… 25066. 25130. 64 "l" KeyL 1023. 104. 976
10 R_00RbUqO7j… 25170. 25250 79.8 "d" KeyD 104. 120 39.9
# ℹ 1,145,041 more rows
# ℹ 1 more variable: gap_apres <dbl>Il y a d’autres fonctions de fenêtre dans le package slider qui nous aident à calculer des résumés plus complexes. Par exemple, slide_mean donne la moyenne d’une fenêtre autour de chaque ligne d’une taille spécifiée.
library(slider)
touches_min |>
filter(id == "R_00RbUqO7jXLDItP") |>
arrange(t0) |>
mutate(
dur_moyenne10 = slide_mean(dur, before=10),
dur_moyenne100 = slide_mean(dur, before=100),
dur_moyenne1000 = slide_mean(dur, before=1000)
) |>
ggplot() +
geom_line(aes(x=t0, y=dur_moyenne10), colour = "#fa8072") +
geom_line(aes(x=t0, y=dur_moyenne100), colour = "#808000") +
geom_line(aes(x=t0, y=dur_moyenne1000), colour = "#6fa8dc") 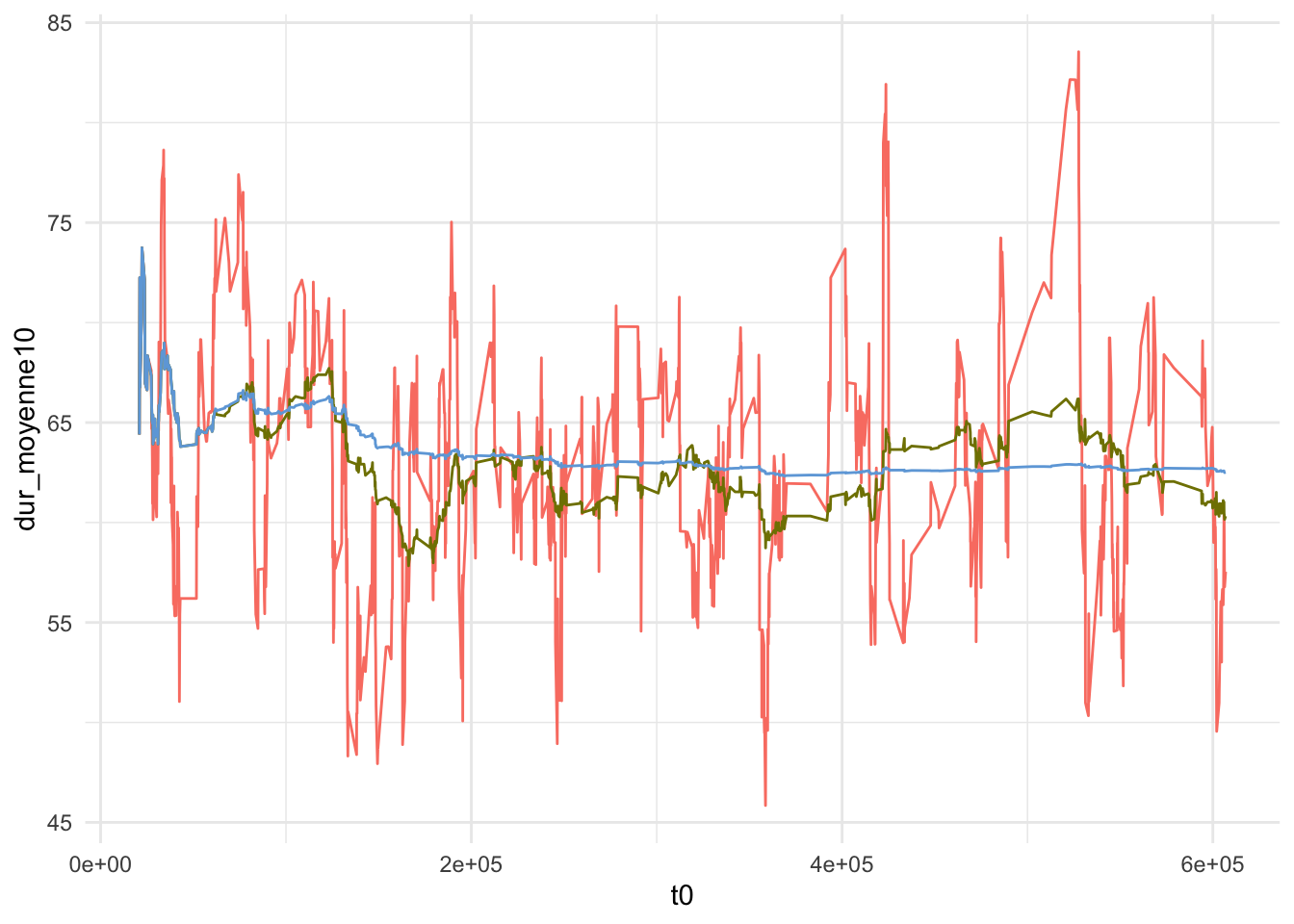
Enfin, le dernier bloc explore l’utilisation de fenêtres glissantes plus larges permettant de calculer des moyennes mobiles sur différents horizons. Après avoir filtré un utilisateur particulier, nous ordonnons ses frappes puis appliquons plusieurs tailles de fenêtre afin de lisser progressivement les durées observées. Cela donne des courbes plus ou moins sensible aux variations locales : une petite fenêtre suit de près les changements instantanés, tandis qu’une grande fenêtre met en évidence des tendances plus globales. Le graphique obtenu superpose ces différentes moyennes, offrant une visualisation intuitive de l’évolution du rythme de frappe au cours du temps.
9. Chaînes de caractères
Dans cette section, nous introduisons l’usage des fonctions provenant du package stringi pour manipuler les données textuelles . Ces fonctions ont la même forme : le nom commence avec stri_ et le premier argument est une séquence de caractères. Par exemple, voici la fonction stri_length qui compte le nombre de caractères dans une séquence.
library(stringi)
mots |>
mutate(nchar = stri_length(mot))# A tibble: 210,337 × 7
id mot char_mot dur_mot d1 d2 nchar
<chr> <chr> <dbl> <dbl> <dbl> <dbl> <int>
1 R_00RbUqO7jXLDItP If 2 312. 928. 848. 2
2 R_00RbUqO7jXLDItP I 1 80.2 1600. 1520 1
3 R_00RbUqO7jXLDItP could 5 1576. 2168. 2088. 5
4 R_00RbUqO7jXLDItP choose 6 945. 976. 904. 6
5 R_00RbUqO7jXLDItP to 2 200. 930. 849. 2
6 R_00RbUqO7jXLDItP be 2 151 528. 456. 2
7 R_00RbUqO7jXLDItP any 3 440. 264 168. 3
8 R_00RbUqO7jXLDItP animal 6 1560 976. 888 6
9 R_00RbUqO7jXLDItP for 3 264. 248 176. 3
10 R_00RbUqO7jXLDItP one 3 312 1120. 1048. 3
# ℹ 210,327 more rowsLe bloc suivant combine cette nouvelle information à celle provenant du tableau des métadonnées. Après avoir joint les deux tables selon l’identifiant utilisateur, nous regroupons les mots par langue, puis calculons la longueur moyenne des mots pour chaque groupe. Ce type de résumé aide à comparer les différentes langues présentes dans le corpus, en examinant si certaines présentent systématiquement des mots plus longs, ce qui pourrait influencer la dynamique de frappe observée.
mots |>
mutate(nchar = stri_length(mot)) |>
left_join(meta, by = "id") |>
group_by(lang) |>
summarise(mu = mean(nchar, na.rm=TRUE)) |>
arrange(desc(mu))# A tibble: 8 × 2
lang mu
<chr> <dbl>
1 German 4.47
2 Greek 4.47
3 French 4.45
4 Portuguese 4.43
5 Italian 4.42
6 Polish 4.39
7 Spanish 4.38
8 English 4.38La majorité des fonctions de stringi a besoin d’un argument figé pour spécifier ce qu’elles font. Par exemple, la fonction stri_detect indique la présence d’une séquence de caractères. Ici nous l’appliquons pour indiquer quels mots ont le caractère <a> en utilisant l’argument fixed.
mots |>
mutate(nombre_a = stri_detect(mot, fixed = "a"))# A tibble: 210,337 × 7
id mot char_mot dur_mot d1 d2 nombre_a
<chr> <chr> <dbl> <dbl> <dbl> <dbl> <lgl>
1 R_00RbUqO7jXLDItP If 2 312. 928. 848. FALSE
2 R_00RbUqO7jXLDItP I 1 80.2 1600. 1520 FALSE
3 R_00RbUqO7jXLDItP could 5 1576. 2168. 2088. FALSE
4 R_00RbUqO7jXLDItP choose 6 945. 976. 904. FALSE
5 R_00RbUqO7jXLDItP to 2 200. 930. 849. FALSE
6 R_00RbUqO7jXLDItP be 2 151 528. 456. FALSE
7 R_00RbUqO7jXLDItP any 3 440. 264 168. TRUE
8 R_00RbUqO7jXLDItP animal 6 1560 976. 888 TRUE
9 R_00RbUqO7jXLDItP for 3 264. 248 176. FALSE
10 R_00RbUqO7jXLDItP one 3 312 1120. 1048. FALSE
# ℹ 210,327 more rowsSouvent, nous ne voulons pas seulement chercher un sequence donné. En revanche, nous avons besoin de trouver les lignes qui correspondent à un ensemble des caractères. Pour cela, nous appliquons les « expressions régulières », langage pour décrire les motifs dans les séquences de caractères. Par exemple, l’expression [A-Z] indique les lettres latines majuscules.
mots |>
mutate(nombre_maj = stri_detect(mot, regex = "[A-Z]"))# A tibble: 210,337 × 7
id mot char_mot dur_mot d1 d2 nombre_maj
<chr> <chr> <dbl> <dbl> <dbl> <dbl> <lgl>
1 R_00RbUqO7jXLDItP If 2 312. 928. 848. TRUE
2 R_00RbUqO7jXLDItP I 1 80.2 1600. 1520 TRUE
3 R_00RbUqO7jXLDItP could 5 1576. 2168. 2088. FALSE
4 R_00RbUqO7jXLDItP choose 6 945. 976. 904. FALSE
5 R_00RbUqO7jXLDItP to 2 200. 930. 849. FALSE
6 R_00RbUqO7jXLDItP be 2 151 528. 456. FALSE
7 R_00RbUqO7jXLDItP any 3 440. 264 168. FALSE
8 R_00RbUqO7jXLDItP animal 6 1560 976. 888 FALSE
9 R_00RbUqO7jXLDItP for 3 264. 248 176. FALSE
10 R_00RbUqO7jXLDItP one 3 312 1120. 1048. FALSE
# ℹ 210,327 more rowsAprès avoir détecté les majuscules et recalculé la longueur du mot, nous filtrons les cas les plus courts afin de faciliter la visualisation. Les données sont ensuite regroupées par longueur et par présence ou absence de majuscule, avant de calculer une médiane des durées associées à la frappe du mot. Le graphique produit illustre ces tendances en représentant, pour chaque longueur, les différences éventuelles entre les deux types de mots, ce qui fournit un aperçu visuel clair des variations liées à la mise en forme du texte.
mots |>
mutate(has_maj = stri_detect(mot, regex = "[A-Z]")) |>
mutate(nchar = stri_length(mot)) |>
filter(nchar < 10) |>
group_by(nchar, has_maj) |>
summarise(mu = median(dur_mot)) |>
ggplot() +
geom_point(aes(x=factor(nchar), y=mu, colour = has_maj))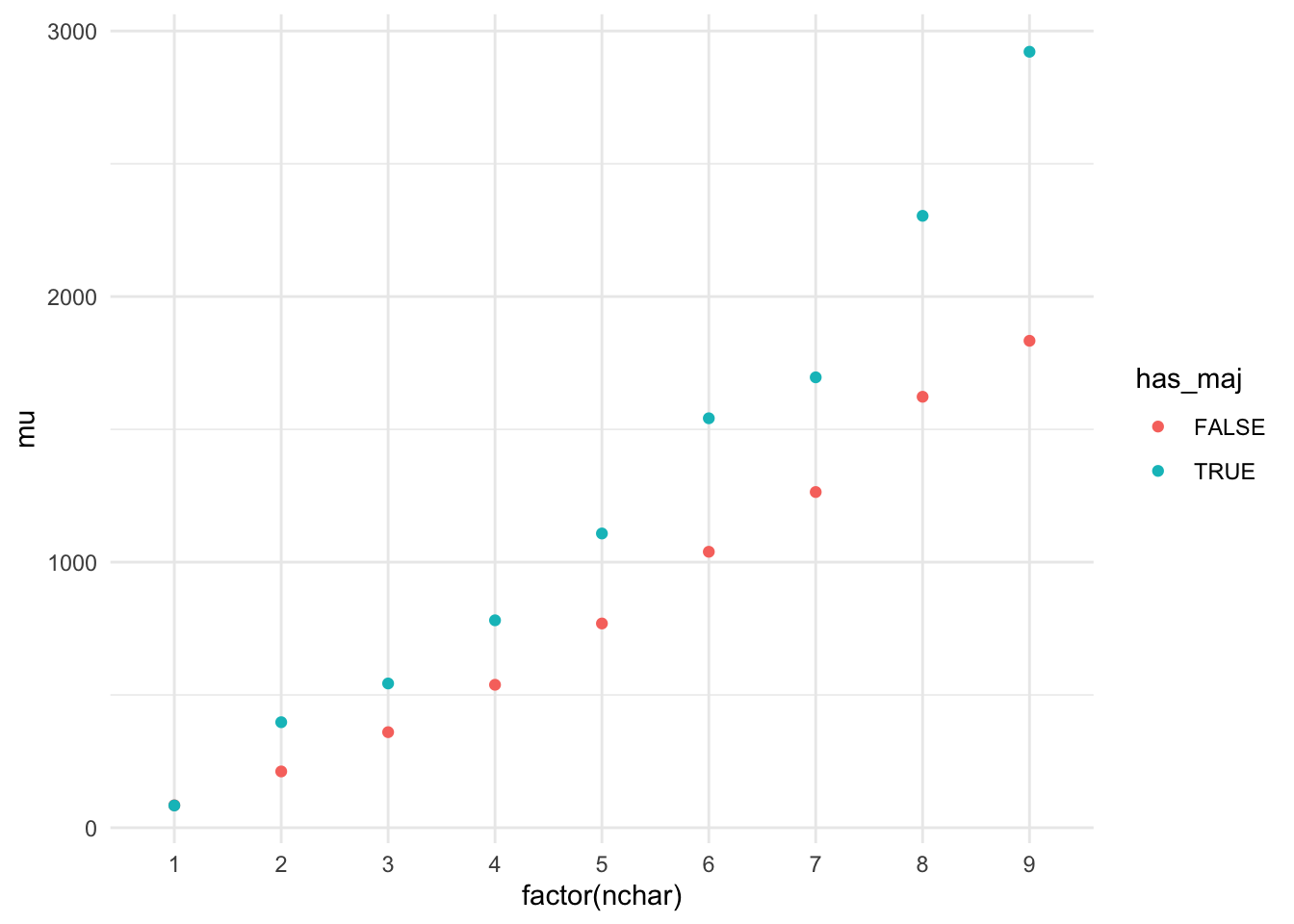
Il y a beaucoup d’autres fonctions de stringi qui ont la même forme avec le choix d’une phrase figée ou une expression régulière. Par exemple, j’utilise souvent stri_count, stri_replace, stri_extract et stri_match.
Nous n’avons pas le temps pour une introduction complète aux expressions régulières. Voici les symboles les plus courants pour la linguistique :
\w: n’importe quel caractère d’un mot (a-z, 0-9, à, è, é, etc.)\W: l’inverse, c’est-à-dire les espaces, virgules, points etc.\A: indique le début d’une phrase\Z: indique la fit d’une phrase- ‘+’ : indique une ou plusieurs occurrences du symbole précédent
Pour une référence de toutes les options, je vous recommande le « Cheatsheet » de Mozilla, qui est accessible en français ou en anglais.
10. TextGrid
Dans cet section, nous travaillons avec des fichiers au format TextGrid, un format couramment utilisé en phonétique pour annoter des enregistrements audio qui provient du logiciel Pratt [3]. Nous allons étudier les données d’un corpus qui s’appelle Rhapsodie. Rhapsodie fournit une base de données syntaxique et prosodique pour le français parlé [4]. Voici un exemple d’un TextGrid du corpus Rhapsodie dans Pratt.
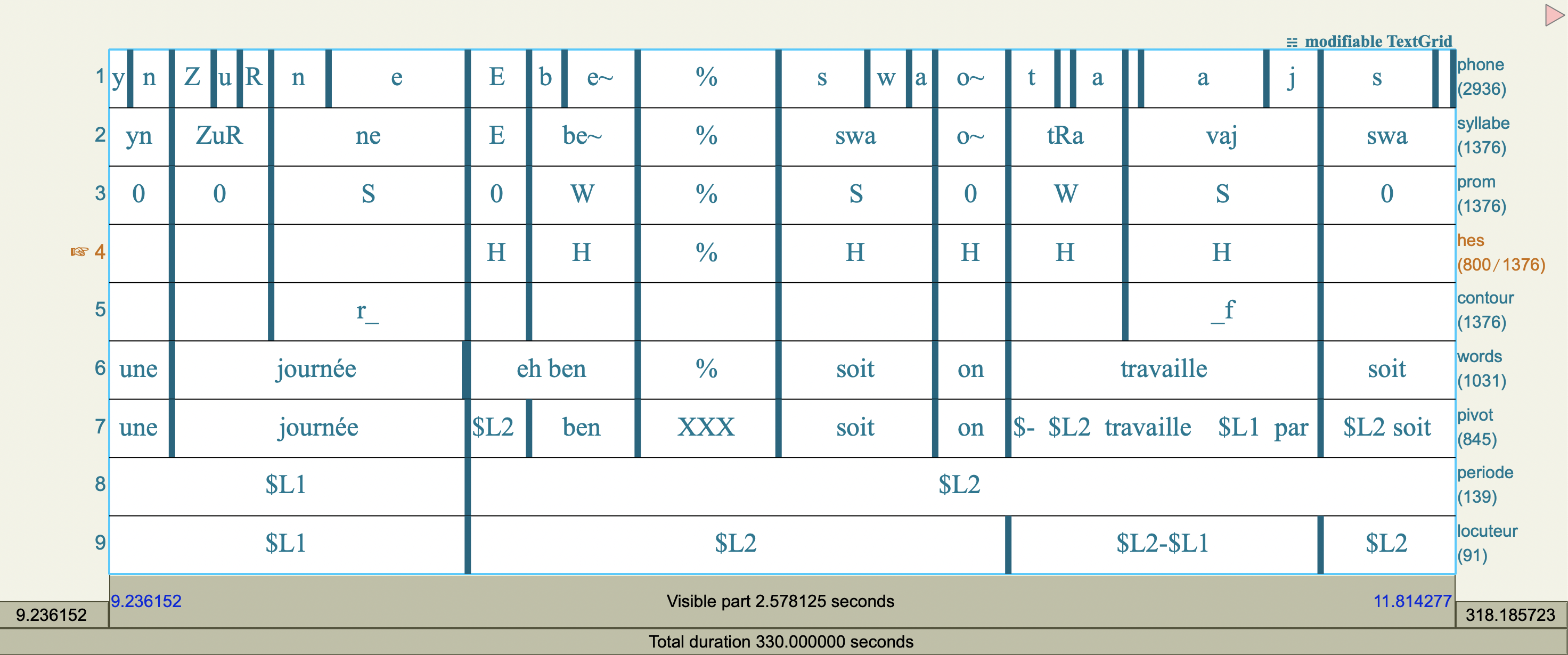
Ce fichier TextGrid contenant plusieurs niveaux d’annotation, chacun représentant des informations différentes comme des segments phonétiques, des contours prosodiques ou d’autres repères temporels. Les niveaux d’annotation se sont appellés les «tiers». Dans Praat, les annotations sont organisées en différentes couches alignées selon leur temporalité.
Voici nous téléchargeons un fichier du corpus Rhapsodie dans R en utilisons le package readtextgrid [5].
library(readtextgrid)
tg <- read_textgrid("donnees/rhapsodie/tg/Rhap-M0018-Pro.TextGrid")
tg# A tibble: 2,731 × 10
file tier_num tier_name tier_type tier_xmin tier_xmax xmin xmax text
<chr> <int> <chr> <chr> <dbl> <dbl> <dbl> <dbl> <chr>
1 Rhap-M001… 1 phone Interval… 0 89.7 0 0.695 _
2 Rhap-M001… 1 phone Interval… 0 89.7 0.695 0.735 e
3 Rhap-M001… 1 phone Interval… 0 89.7 0.735 0.845 s
4 Rhap-M001… 1 phone Interval… 0 89.7 0.845 0.875 a
5 Rhap-M001… 1 phone Interval… 0 89.7 0.875 0.935 a~
6 Rhap-M001… 1 phone Interval… 0 89.7 0.935 1.01 S
7 Rhap-M001… 1 phone Interval… 0 89.7 1.01 1.06 E
8 Rhap-M001… 1 phone Interval… 0 89.7 1.06 1.10 n
9 Rhap-M001… 1 phone Interval… 0 89.7 1.10 1.16 s
10 Rhap-M001… 1 phone Interval… 0 89.7 1.16 1.22 y
# ℹ 2,721 more rows
# ℹ 1 more variable: annotation_num <int>Le format dans R est très différent du format dans Praat. Dans R, les dimensions temporelles des niveaux ne sont pas directement reliées entre elles. Toutes les données d’un niveau (ici phone) sont fournies, suivies du deuxième niveau, et ainsi de suite. Ce format n’est pas aussi bien adapté à la consultation directe des données, mais il est plutôt optimisé pour la programmation.
Le bloc suivant extrait spécifiquement le tier correspondant aux phonèmes, appelé « phone » dans le fichier. Ce niveau contient une segmentation fine de la parole où chaque entrée représente un segment phonétique délimité dans le temps.
tg_phone <- tg |>
filter(tier_name == "phone")
tg_phone# A tibble: 734 × 10
file tier_num tier_name tier_type tier_xmin tier_xmax xmin xmax text
<chr> <int> <chr> <chr> <dbl> <dbl> <dbl> <dbl> <chr>
1 Rhap-M001… 1 phone Interval… 0 89.7 0 0.695 _
2 Rhap-M001… 1 phone Interval… 0 89.7 0.695 0.735 e
3 Rhap-M001… 1 phone Interval… 0 89.7 0.735 0.845 s
4 Rhap-M001… 1 phone Interval… 0 89.7 0.845 0.875 a
5 Rhap-M001… 1 phone Interval… 0 89.7 0.875 0.935 a~
6 Rhap-M001… 1 phone Interval… 0 89.7 0.935 1.01 S
7 Rhap-M001… 1 phone Interval… 0 89.7 1.01 1.06 E
8 Rhap-M001… 1 phone Interval… 0 89.7 1.06 1.10 n
9 Rhap-M001… 1 phone Interval… 0 89.7 1.10 1.16 s
10 Rhap-M001… 1 phone Interval… 0 89.7 1.16 1.22 y
# ℹ 724 more rows
# ℹ 1 more variable: annotation_num <int>Nous procédons ensuite à une analyse descriptive des durées phonémiques. En éliminant les segments marqués par un symbole de remplissage, nous regroupons les phonèmes par type et calculons la durée moyenne correspondante. Cela permet de visualiser, sous forme de nuage de points, les phonèmes les plus courts et les plus longs, révélant ainsi des tendances phonétiques naturelles comme la brièveté des voyelles réduites ou la relative lenteur de certaines consonnes.
tg_phone |>
filter(text != "_") |>
group_by(text) |>
summarise(dur_moyenne = mean(xmax - xmin)) |>
arrange(dur_moyenne) |>
ggplot() +
geom_point(aes(x=fct_inorder(text), y=dur_moyenne))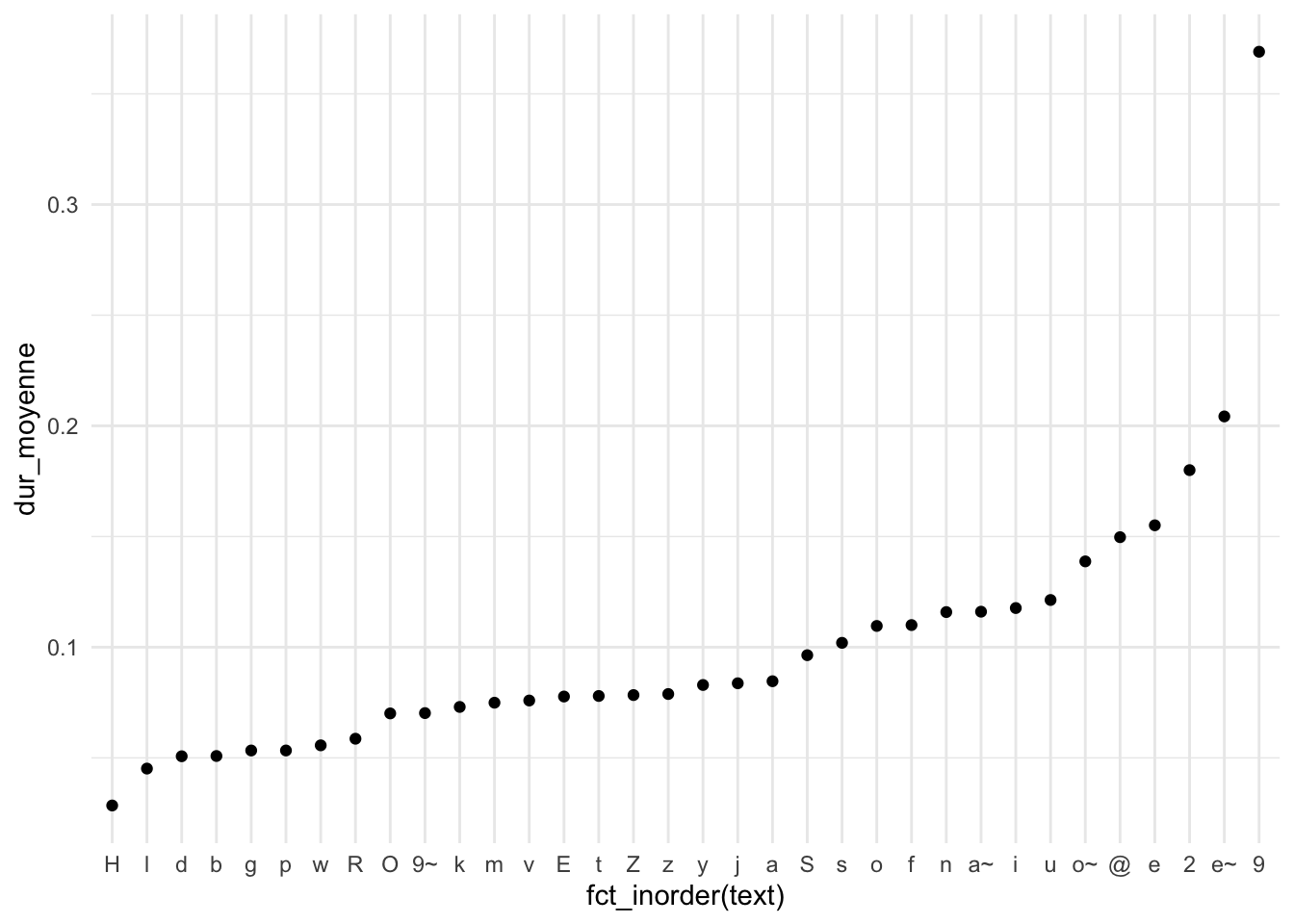
Le bloc suivant extrait un autre tier, ici appelé contour, qui peut représenter des catégories prosodiques ou des niveaux mélodiques associés à la parole. En filtrant ce tier pour ne conserver que certains symboles choisis, on se concentre sur les principales catégories d’annotation nécessaires à l’analyse. Afficher le tableau obtenu permet de vérifier que les entrées retenues sont bien celles attendues avant de les utiliser comme éléments de référence pour une fusion avec les phonèmes.
tg_contour <- tg |>
filter(tier_name == "contour") |>
filter(text %in% c("M", "C", "H", "L"))
tg_contour# A tibble: 191 × 10
file tier_num tier_name tier_type tier_xmin tier_xmax xmin xmax text
<chr> <int> <chr> <chr> <dbl> <dbl> <dbl> <dbl> <chr>
1 Rhap-M001… 5 contour Interval… 0 89.8 0.695 0.735 L
2 Rhap-M001… 5 contour Interval… 0 89.8 0.735 0.875 L
3 Rhap-M001… 5 contour Interval… 0 89.8 0.875 0.935 L
4 Rhap-M001… 5 contour Interval… 0 89.8 0.935 1.10 H
5 Rhap-M001… 5 contour Interval… 0 89.8 1.22 1.36 L
6 Rhap-M001… 5 contour Interval… 0 89.8 1.36 1.52 H
7 Rhap-M001… 5 contour Interval… 0 89.8 4.08 4.49 C
8 Rhap-M001… 5 contour Interval… 0 89.8 6.04 6.14 C
9 Rhap-M001… 5 contour Interval… 0 89.8 6.79 7.43 C
10 Rhap-M001… 5 contour Interval… 0 89.8 8.99 9.14 H
# ℹ 181 more rows
# ℹ 1 more variable: annotation_num <int>Le bloc suivant illustre une opération plus avancée : il s’agit de joindre les informations phonémiques et prosodiques en fonction de leurs chevauchements temporels en utilisant la fonction join_by. Cette jonction exploite une condition où un phonème est associé à une catégorie prosodique si ses bornes temporelles se trouvent incluses dans l’intervalle correspondant du contour. Le résultat est un tableau enrichi où chaque phonème porte, en plus de son étiquette propre, l’annotation prosodique qui lui correspond. Ce type de fusion temporelle est courant en traitement de la parole pour relier différents niveaux d’analyse.
tg_join <- tg_phone |>
left_join(
select(tg_contour, xmin, xmax, text),
by = join_by(
xmin >= xmin,
xmax <= xmax
),
suffix = c("", "_contour")
)
tg_join# A tibble: 734 × 13
file tier_num tier_name tier_type tier_xmin tier_xmax xmin xmax text
<chr> <int> <chr> <chr> <dbl> <dbl> <dbl> <dbl> <chr>
1 Rhap-M001… 1 phone Interval… 0 89.7 0 0.695 _
2 Rhap-M001… 1 phone Interval… 0 89.7 0.695 0.735 e
3 Rhap-M001… 1 phone Interval… 0 89.7 0.735 0.845 s
4 Rhap-M001… 1 phone Interval… 0 89.7 0.845 0.875 a
5 Rhap-M001… 1 phone Interval… 0 89.7 0.875 0.935 a~
6 Rhap-M001… 1 phone Interval… 0 89.7 0.935 1.01 S
7 Rhap-M001… 1 phone Interval… 0 89.7 1.01 1.06 E
8 Rhap-M001… 1 phone Interval… 0 89.7 1.06 1.10 n
9 Rhap-M001… 1 phone Interval… 0 89.7 1.10 1.16 s
10 Rhap-M001… 1 phone Interval… 0 89.7 1.16 1.22 y
# ℹ 724 more rows
# ℹ 4 more variables: annotation_num <int>, xmin_contour <dbl>,
# xmax_contour <dbl>, text_contour <chr>Enfin, nous terminons par un tableau croisé qui récapitule la distribution des phonèmes selon les catégories prosodiques associées.
tg_join |>
filter(text != "_") |>
group_by(text) |>
summarise(
moyenne_l = mean(text_contour == "L", na.rm=TRUE),
n = n()
) |>
arrange(moyenne_l) |>
filter(n > 20) |>
print(n = Inf)# A tibble: 14 × 3
text moyenne_l n
<chr> <dbl> <int>
1 t 0.263 28
2 p 0.278 29
3 k 0.333 22
4 a~ 0.389 30
5 i 0.417 28
6 R 0.44 49
7 @ 0.455 30
8 d 0.467 27
9 s 0.517 39
10 u 0.545 22
11 E 0.583 23
12 a 0.6 73
13 l 0.625 47
14 e 0.696 35Ce tableau permet de repérer rapidement quelles combinaisons apparaissent fréquemment et lesquelles sont rares ou absentes. Une telle vue d’ensemble peut aider à détecter des structures prosodiques typiques ou à identifier d’éventuelles incohérences dans l’annotation.
11. Programmer
L’analyse dans la dernière section n’utilise qu’un seul fichier. Le corpus Rhapsodie se compose d’environ 60 fichiers. Ce n’est pas pratique de créer le code pour les charger un par un. En revanche, on a besoin de fonctions de programmation en R pour appliquer notre analyse à chaque fichier.
Voici un exemple de code qui (1) trouve les fichiers au format TextGrid (avec dir), (2) applique une boucle sur chaque fichier et (3) combine tous les résultats dans un grand tableau (avec bind_rows).
dir_nom <- "donnees/rhapsodie/tg/"
d <- dir(dir_nom, pattern="TextGrid$")
df <- list("vector", length(d))
for (j in seq_along(d)) {
tg <- read_textgrid(file.path(dir_nom, d[j]), encoding="UTF-8")
tg$id <- j
# ↓↓↓ cette partie ci-dessous fonctionne de traiter une seule
# ↓↓↓ fiche ; vous pouvez la changer
tg_phone <- tg |>
filter(tier_name == "phone")
tg_contour <- tg |>
filter(tier_name == "contour") |>
filter(text %in% c("M", "C", "H", "L"))
res <- tg_phone |>
left_join(
select(tg_contour, xmin, xmax, text),
by = join_by(
xmin >= xmin,
xmax <= xmax
),
suffix = c("", "_contour")
)
# ↑↑↑
df[[j]] <- res
}
df <- bind_rows(df)
df# A tibble: 104,695 × 14
file tier_num tier_name tier_type tier_xmin tier_xmax xmin xmax text
<chr> <int> <chr> <chr> <dbl> <dbl> <dbl> <dbl> <chr>
1 Rhap-D000… 1 phone Interval… 0 330. 0 2.23 _
2 Rhap-D000… 1 phone Interval… 0 330. 2.23 2.27 e
3 Rhap-D000… 1 phone Interval… 0 330. 2.27 2.42 s
4 Rhap-D000… 1 phone Interval… 0 330. 2.42 2.45 k
5 Rhap-D000… 1 phone Interval… 0 330. 2.45 2.48 @
6 Rhap-D000… 1 phone Interval… 0 330. 2.48 2.54 v
7 Rhap-D000… 1 phone Interval… 0 330. 2.54 2.65 u
8 Rhap-D000… 1 phone Interval… 0 330. 2.65 2.68 p
9 Rhap-D000… 1 phone Interval… 0 330. 2.68 2.74 u
10 Rhap-D000… 1 phone Interval… 0 330. 2.74 2.82 R
# ℹ 104,685 more rows
# ℹ 5 more variables: annotation_num <int>, id <int>, xmin_contour <dbl>,
# xmax_contour <dbl>, text_contour <chr>La partie entre les flèches indique où j’ai ajouté du code spécifique à chaque fichier.
Après avoir obtenu le tableau df, nous pouvons appliquer les mêmes verbes que nous avons utilisé dans la section précédente.
df |>
filter(text != "_") |>
group_by(text) |>
summarise(
moyenne_l = mean(text_contour == "L", na.rm = TRUE),
n = n()
) |>
arrange(moyenne_l) |>
filter(n > 20) |>
print(n = Inf)# A tibble: 38 × 3
text moyenne_l n
<chr> <dbl> <int>
1 m= 0.25 50
2 ? 0.364 23
3 H 0.382 426
4 f 0.411 1369
5 w 0.418 1194
6 S 0.450 511
7 j 0.451 1811
8 i 0.464 5412
9 s 0.467 5828
10 p 0.468 3608
11 t 0.468 5069
12 o~ 0.488 2178
13 o 0.503 1284
14 k 0.504 4208
15 u 0.514 2160
16 b 0.517 1212
17 y 0.518 1978
18 O 0.533 2021
19 R 0.535 7418
20 9 0.548 883
21 a~ 0.552 3425
22 Z 0.552 1710
23 E 0.552 4393
24 2 0.556 967
25 J 0.562 27
26 g 0.571 636
27 e~ 0.574 759
28 e 0.575 6287
29 n 0.576 2724
30 z 0.576 1451
31 m 0.579 3202
32 v 0.603 2721
33 a 0.609 8589
34 l 0.611 6144
35 9~ 0.640 860
36 d 0.642 4413
37 @ 0.642 3647
38 % NaN 127Nous voyons que les résultats deviennent plus stables avec tous les fichiers.
12. Données audio
Il est possible d’analyser les fichiers audio (.mp3, .wav, etc.) directement dans R. Voici nous télécharger un fichier qui contient la prononciation de la voyelle /i/ en français avec les fonctions readWave et makesound, respectivement du package tuneR et de package phonTools [6; 7].
library(tuneR)
library(phonTools)
w <- readWave("donnees/voyelles/i.wav")
snd <- makesound(w@left, fs = w@samp.rate)
snd
Sound Object
Read from file: w@left.wav
Sampling frequency: 44100 Hz
Duration: 2340 ms
Number of Samples: 103194 Le résultat donne un objet spécifique (« Sound Object ») que nous pouvons étudier avec les fonctions provenant du package phonTools. Par exemple, nous pouvons calculer l’intensité du son avec powertrak. Par défaut, la fonction crée une visualisation en même temps.
power <- powertrack(snd, fs = fs)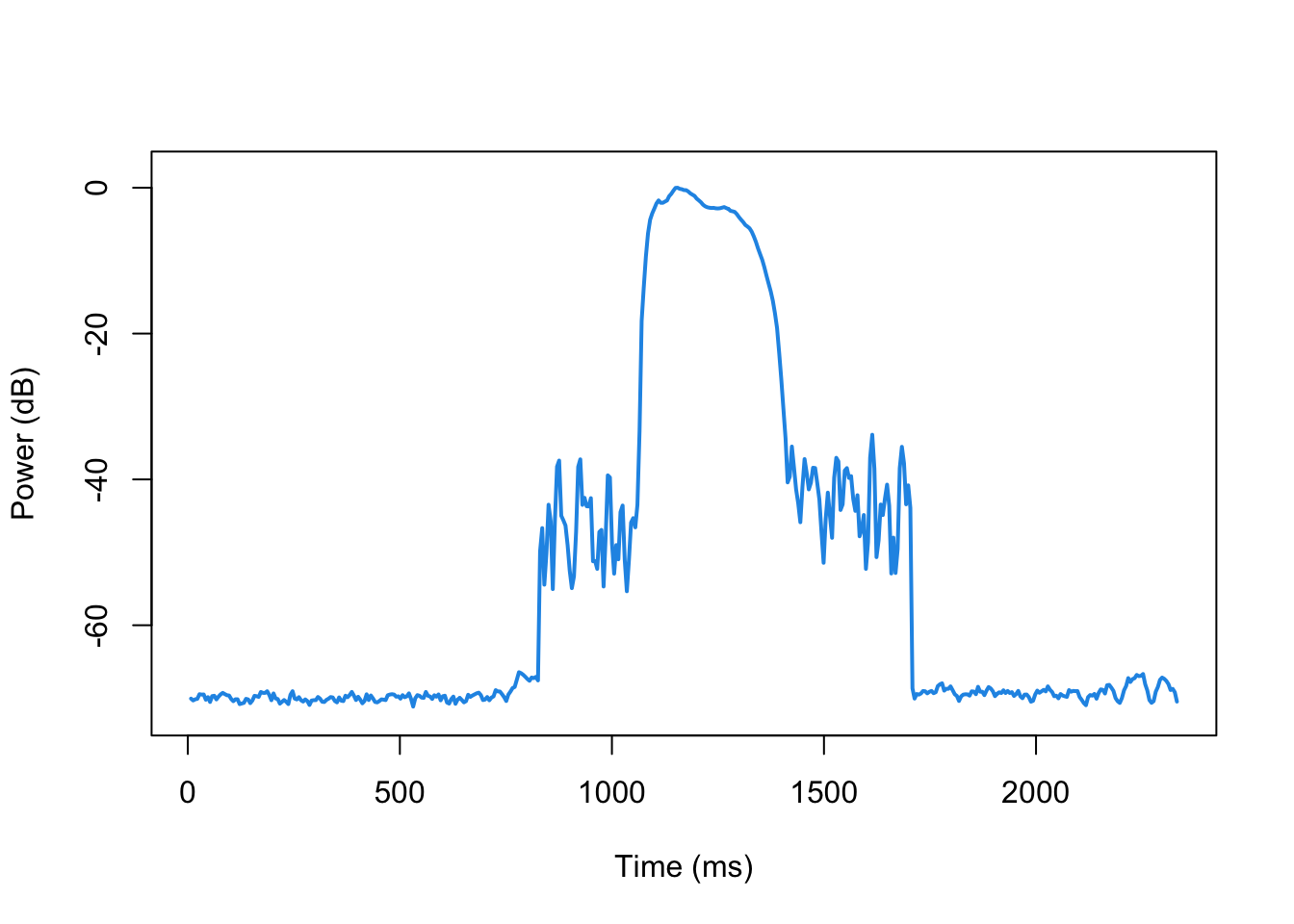
Comme toujours, nous voudrions organiser l’information dans un tableau puis appliquer toutes les fonctions générales pour la visualisation, la modification et les modèles.
power <- as_tibble(power)
power# A tibble: 467 × 2
time power
<dbl> <dbl>
1 7.53 -70.1
2 12.5 -70.3
3 17.5 -70.2
4 22.5 -70.1
5 27.5 -69.5
6 32.5 -69.5
7 37.5 -69.5
8 42.4 -70.2
9 47.4 -69.9
10 52.4 -70.5
# ℹ 457 more rowsNous pouvons faire la même chose avec les formants en utilisant la fonction formanttrack.
formants <- formanttrack(snd, fs = fs)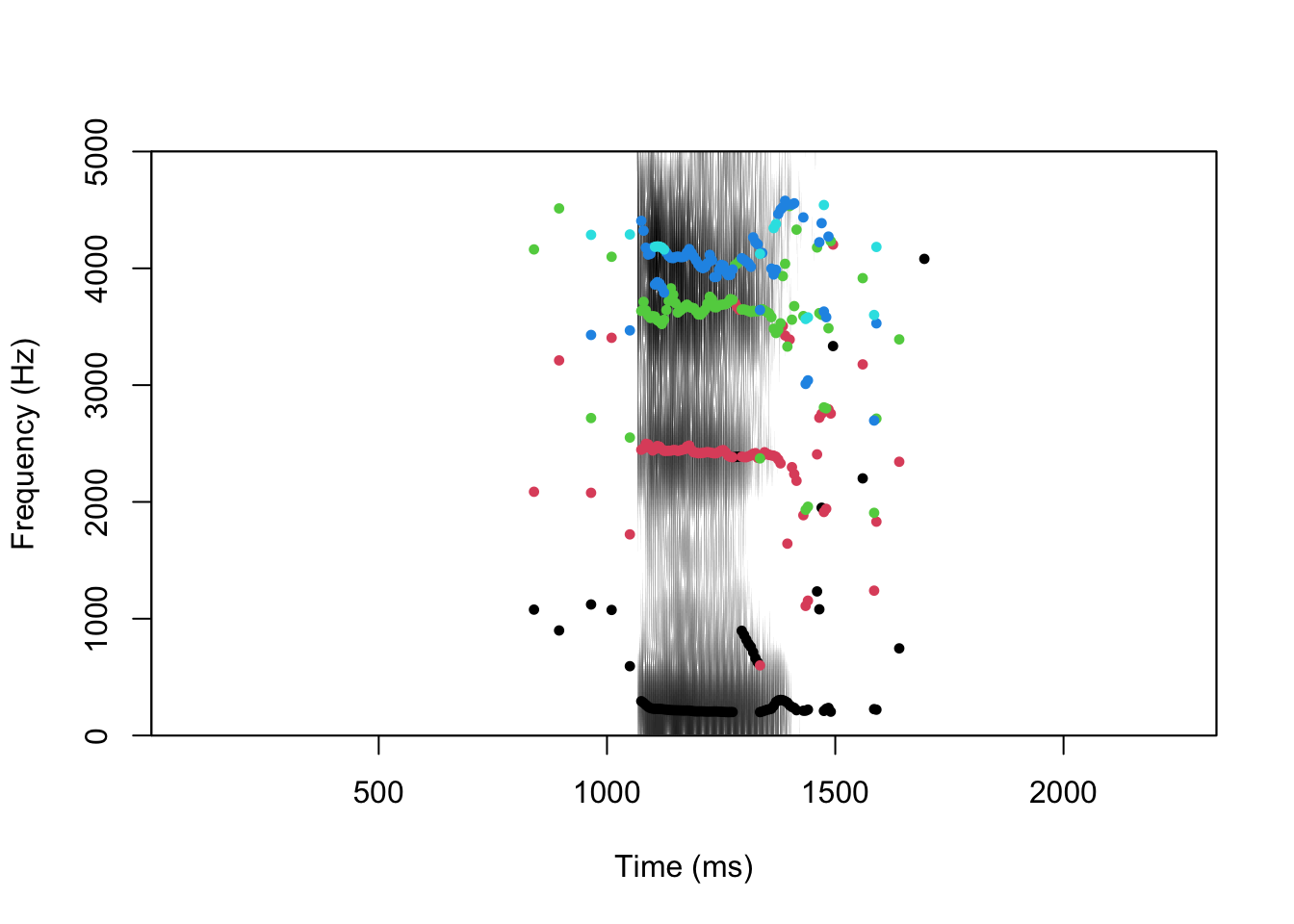
Et aussi, nous pouvons créer des données tabulaires.
formants <- as_tibble(formants)
formants# A tibble: 90 × 6
time f1 f2 f3 f4 f5
<dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
1 840. 1078. 2087. 4162. 0 0
2 895. 899. 3212. 4513. 0 0
3 965. 1122. 2078. 2718. 3430. 4287.
4 1010. 1075. 3405. 4099. 0 0
5 1050. 593. 1722. 2551. 3468. 4290.
6 1075. 294. 2447. 3636. 4406. 0
7 1080. 280. 2459. 3713. 4322. 0
8 1085. 262. 2498. 3640. 4177. 0
9 1090. 245. 2493. 3597. 4118. 0
10 1095. 235. 2459. 3575. 4124. 0
# ℹ 80 more rowsPour aller plus loin, il faut appliquer les fonctions de programmation pour calculer la courbe de l’intensité et les formants pour chaque voyelle (qui sont dans leurs propres fichiers). Nous pouvons appliquer et modifier l’exemple dans la Section 11. Voici le code qui sauvegarde les formants au point de l’intensité maximale pour chaque voyelle.
dir_nom <- "donnees/voyelles"
d <- dir(dir_nom, pattern="wav$")
df <- list("vector", length(d))
for (j in seq_along(d)) {
w <- readWave(file.path(dir_nom, d[j]))
snd <- makesound(w@left, fs = w@samp.rate)
# ↓↓↓ cette partie ci-dessous fonctionne de traiter une seule
# ↓↓↓ fiche ; vous pouvez la changer
power <- powertrack(snd, fs = fs, show=FALSE)
power <- as_tibble(power)
formants <- formanttrack(snd, fs = fs, show=FALSE)
formants <- as_tibble(formants)
t_haut <- arrange(power, desc(power))$time[1]
res <- arrange(formants, abs(time - t_haut))[1,]
res$fname <- d[j]
# ↑↑↑
df[[j]] <- res
}
df <- bind_rows(df)
df# A tibble: 11 × 7
time f1 f2 f3 f4 f5 fname
<dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <chr>
1 965. 760. 1173. 2480. 3453. 3662. a.wav
2 1380. 351. 2404. 2919. 4144. 0 e.wav
3 650. 537. 1460. 2581. 3471. 4365. ə.wav
4 520. 663. 1626. 2459. 3512. 3794. ɛ.wav
5 1155. 216. 2437. 3622. 4101. 0 i.wav
6 975. 352. 874. 2494. 3698. 4329. o.wav
7 1460. 250 1421. 2595. 3453. 4174. ø.wav
8 795. 501. 1398. 2581. 3386. 0 œ.wav
9 955. 619. 1115. 2610. 3524. 4188. ɔ.wav
10 1050. 257. 580. 1923. 2626. 3842. u.wav
11 975. 239. 2119. 2307. 3138. 4085. y.wavNous pouvons récréer la visualisation comme dans la Section 4 avec les formants de ces exemples.
df |>
mutate(api = stri_replace(fname, "", fixed = ".wav")) |>
ggplot() +
geom_text(aes(x=f2, y=f1, label = api)) +
scale_x_reverse() +
scale_y_reverse()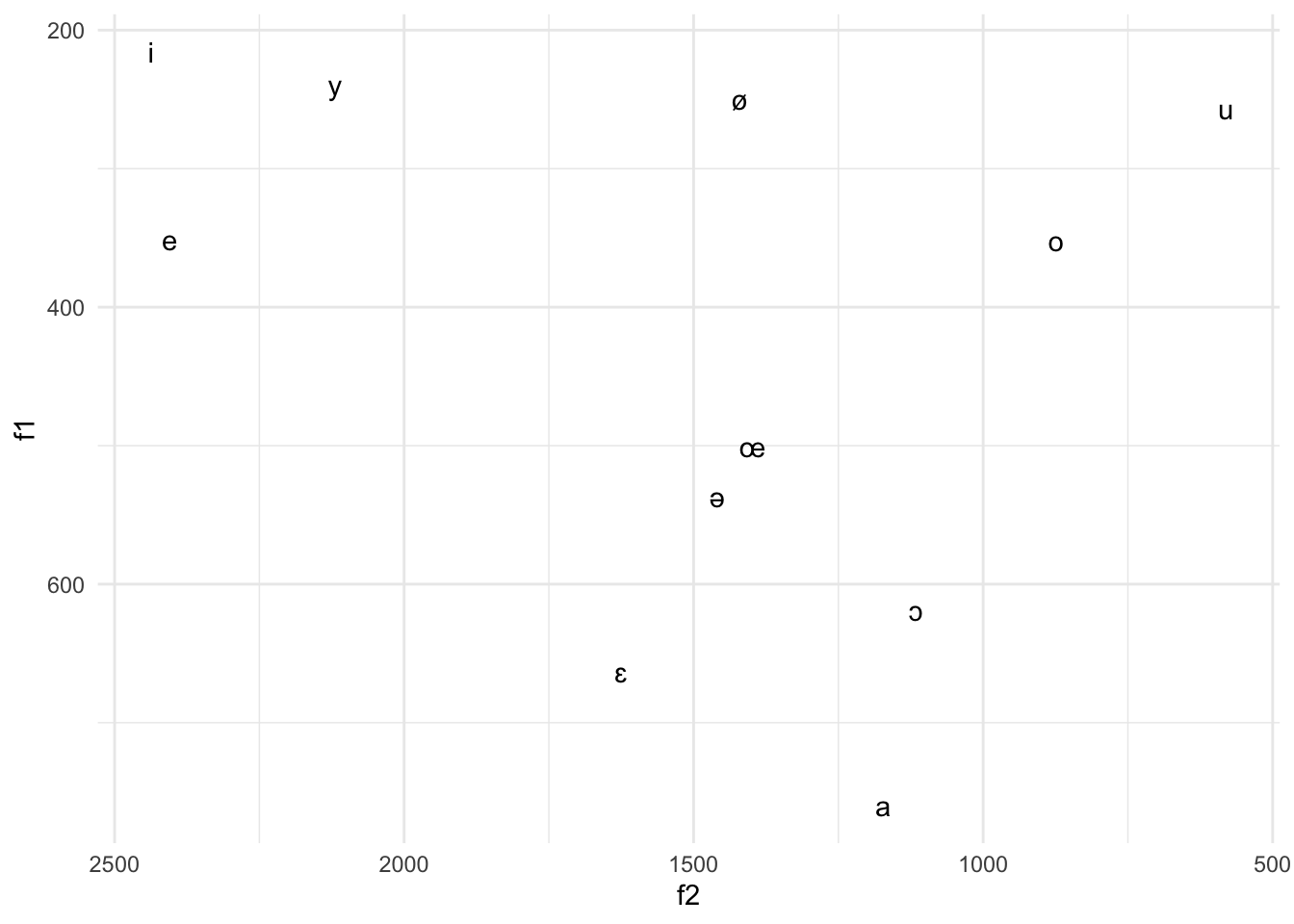
Pour finir, je note qu’il est aussi possible d’utiliser la fonction pitchtrack de la même façon pour calculer la fréquence fondamentalle d’un fichier sonore.
13. Analyse grammaticale
Dans cette section, nous explorons l’analyse grammaticale automatique à l’aide de udpipe, outil qui permet d’annoter automatiquement du texte de manière détaillée : identification des mots, lemmatisation, catégorisation grammaticale et détection de traits morphologiques [8].
Le premier bloc charge un modèle de langue pré-entraîné pour le français. Ce modèle est dérivé du corpus GSD [9]. Si l’on ne spécifie pas de modèle, celui-ci sera téléchargé automatiquement.
library(udpipe)
udmodel_fr <- udpipe_load_model(file = "donnees/french-gsd-ud-2.5-191206.udpipe")Le bloc suivant applique ce modèle à un texte littéraire, la « tirade du nez » [10]. Le texte est dans un format brut puis passé au moteur d’annotation qui segmente les mots, identifie leur catégorie grammaticale, leur lemme et leurs traits morphologiques. Le résultat, converti en tibble, permet d’inspecter les annotations ligne par ligne.
txt_tirade <- read_lines("donnees/tirade_du_nez.txt")
df_tirade <- as_tibble(udpipe_annotate(
udmodel_fr, x = txt_tirade
))
df_tirade# A tibble: 625 × 14
doc_id paragraph_id sentence_id sentence token_id token lemma upos xpos
<chr> <int> <int> <chr> <chr> <chr> <chr> <chr> <chr>
1 doc1 1 1 C'est tout ? 1 C' ce PRON <NA>
2 doc1 1 1 C'est tout ? 2 est être AUX <NA>
3 doc1 1 1 C'est tout ? 3 tout tout ADJ <NA>
4 doc1 1 1 C'est tout ? 4 ? ? PUNCT <NA>
5 doc2 1 1 Ah ! non ! 1 Ah ah INTJ <NA>
6 doc2 1 1 Ah ! non ! 2 ! ! PUNCT <NA>
7 doc2 1 1 Ah ! non ! 3 non non ADV <NA>
8 doc2 1 1 Ah ! non ! 4 ! ! PUNCT <NA>
9 doc2 1 2 c'est un pe… 1 c' ce PRON <NA>
10 doc2 1 2 c'est un pe… 2 est être AUX <NA>
# ℹ 615 more rows
# ℹ 5 more variables: feats <chr>, head_token_id <chr>, dep_rel <chr>,
# deps <chr>, misc <chr>L’application de udpipe_annotate peut prendre plusieurs heures pour les grandes données. Heureusement, comme les résultats sont un tableau, nous ne pouvons l’appliquer qu’une seule fois, sauvegarder dans un fichier, puis charger pour réanalyser.
Dans le bloc suivant, nous chargeons un corpus tiré de Wikipédia (3 pour cent de tous les articles), déjà prétraité pour inclure des annotations grammaticales. Ce corpus volumineux permet d’étudier les habitudes grammaticales de milliers de phrases, ce qui ouvre la voie à des analyses quantitatives plus ambitieuses.
wikifr <- read_csv2("donnees/wiki_parsed.csv.bz2")
wikifr# A tibble: 2,431,081 × 11
doc_id sid tid token lemma pos xpos dep dep_head head morph
<chr> <dbl> <dbl> <chr> <chr> <chr> <chr> <chr> <dbl> <chr> <chr>
1 Arabie saoudi… 1 1 L l NOUN NOUN nsubj 10 mona… <NA>
2 Arabie saoudi… 1 2 , , PUNCT PUNCT punct 1 L <NA>
3 Arabie saoudi… 1 3 en en ADP ADP case 4 forme <NA>
4 Arabie saoudi… 1 4 forme forme NOUN NOUN nmod 1 L Gend…
5 Arabie saoudi… 1 5 long… long ADJ ADJ amod 4 forme Gend…
6 Arabie saoudi… 1 6 le le DET DET det 10 mona… Defi…
7 Arabie saoudi… 1 7 , , PUNCT PUNCT punct 10 mona… <NA>
8 Arabie saoudi… 1 8 est être AUX AUX cop 10 mona… Mood…
9 Arabie saoudi… 1 9 une un DET DET det 10 mona… Defi…
10 Arabie saoudi… 1 10 mona… mona… NOUN NOUN ROOT 0 ROOT Gend…
# ℹ 2,431,071 more rowsLe bloc suivant effectue une analyse centrée sur les verbes et leurs temps conjugués en utilisant les fonctions provenant de stringi. Nous filtrons d’abord les entrées pour ne conserver que les verbes qui portent un trait morphologique indiquant un temps verbal. Ensuite, nous détectons la présence de plusieurs temps (présent, imparfait et passé) en comptant combien de fois chaque trait apparaît dans les annotations. En regroupant les occurrences par lemme, nous obtenons une estimation de la fréquence moyenne des temps verbaux utilisés pour chaque verbe. Après filtrage des lemmes suffisamment fréquents, nous trions les résultats pour mettre en avant ceux dont le présent apparaît le moins souvent. Cette approche montre comment extraire des tendances grammaticales générales à partir d’un grand corpus.
wikifr |>
filter(pos == "VERB") |>
filter(stri_detect(morph, fixed = "Tense=")) |>
mutate(
pres = stri_count(morph, fixed = "Tense=Pres"),
imp = stri_count(morph, fixed = "Tense=Imp"),
passe = stri_count(morph, fixed = "Tense=Past")
) |>
group_by(lemma) |>
summarise(
pres_moyenne = mean(pres),
imp_moyenne = mean(imp),
passe_moyenne = mean(passe),
n = n()
) |>
filter(n > 800) |>
arrange(pres_moyenne) |>
print(n = Inf)# A tibble: 21 × 5
lemma pres_moyenne imp_moyenne passe_moyenne n
<chr> <dbl> <dbl> <dbl> <int>
1 situer 0.191 0.0237 0.783 1012
2 utiliser 0.220 0.0637 0.705 1020
3 appeler 0.273 0.0317 0.688 882
4 créer 0.275 0.00581 0.713 861
5 connaître 0.280 0.0201 0.695 995
6 réaliser 0.304 0.0242 0.669 869
7 considérer 0.328 0.0536 0.614 839
8 mettre 0.399 0.0134 0.584 1415
9 dire 0.427 0.0239 0.535 836
10 faire 0.608 0.0563 0.308 2893
11 voir 0.660 0.0317 0.304 1041
12 passer 0.661 0.0289 0.305 935
13 avoir 0.677 0.127 0.171 3391
14 devoir 0.682 0.177 0.111 1716
15 prendre 0.686 0.0163 0.287 1351
16 devenir 0.687 0.0166 0.289 1445
17 permettre 0.767 0.0509 0.171 1532
18 trouver 0.789 0.0699 0.135 1316
19 pouvoir 0.834 0.0537 0.0939 3484
20 aller 0.885 0.0680 0.0403 868
21 être 0.928 0.0261 0.0301 1228Il est possible aussi d’entraîner les modèles nous-mêmes. Pour cela, nous chargeons un corpus au format CoNLL-U, structure standard utilisée dans le projet Universal Dependencies pour représenter des annotations linguistiques complètes. Ce fichier contient des exemples annotés manuellement, ce qui en fait une ressource précieuse pour entraîner ou évaluer des modèles. La conversion en tibble permet d’en inspecter facilement les colonnes, notamment les mots, les lemmes, les étiquettes grammaticales et les dépendances syntaxiques.
ud <- as_tibble(udpipe_read_conllu("donnees/fr_sequoia-ud-train.conllu"))
ud# A tibble: 51,862 × 14
doc_id paragraph_id sentence_id sentence token_id token lemma upos xpos
<chr> <int> <chr> <chr> <chr> <chr> <chr> <chr> <chr>
1 <NA> 0 annodis.er_000… Gutenbe… 1 Gute… Gute… PROPN <NA>
2 <NA> 0 annodis.er_000… Cette e… 1 Cette ce DET <NA>
3 <NA> 0 annodis.er_000… Cette e… 2 expo… expo… NOUN <NA>
4 <NA> 0 annodis.er_000… Cette e… 3 nous nous PRON <NA>
5 <NA> 0 annodis.er_000… Cette e… 4 appr… appr… VERB <NA>
6 <NA> 0 annodis.er_000… Cette e… 5 que que SCONJ <NA>
7 <NA> 0 annodis.er_000… Cette e… 6 dès dès ADP <NA>
8 <NA> 0 annodis.er_000… Cette e… 7 le le DET <NA>
9 <NA> 0 annodis.er_000… Cette e… 8 XIIe XIIe ADJ <NA>
10 <NA> 0 annodis.er_000… Cette e… 9 sièc… sièc… NOUN <NA>
# ℹ 51,852 more rows
# ℹ 5 more variables: feats <chr>, head_token_id <chr>, dep_rel <chr>,
# deps <chr>, misc <chr>Le bloc suivant montre comment entraîner son propre modèle UDPipe à partir d’un corpus annoté. L’entraînement consiste à apprendre un tokenizer, un étiqueteur morphosyntaxique et un analyseur en dépendances. Les résultats sont sauvegardés dans le fichier exemple_fr.udpipe.
m <- udpipe_train(
file = "donnees/exemple_fr.udpipe",
files_conllu_training = "donnees/fr_sequoia-ud-train.conllu",
annotation_tokenizer = "default",
annotation_tagger = "default",
annotation_parser = "default"
)Enfin, le dernier bloc charge ce modèle nouvellement entraîné, puis l’applique au texte de la tirade afin de comparer les résultats avec ceux du modèle standard. Cette étape permet d’évaluer les différences d’annotation, d’observer les éventuelles améliorations ou divergences, et d’illustrer concrètement l’importance du choix du modèle dans une chaîne d’analyse grammaticale automatisée.
udmodel_fr_nouv <- udpipe_load_model(
file = "donnees/exemple_fr.udpipe"
)
df_tirade_nouv <- as_tibble(udpipe_annotate(
udmodel_fr_nouv, x = txt_tirade
))
df_tirade_nouv# A tibble: 620 × 14
doc_id paragraph_id sentence_id sentence token_id token lemma upos xpos
<chr> <int> <int> <chr> <chr> <chr> <chr> <chr> <chr>
1 doc1 1 1 C'est tout ? 1 C' ce PRON <NA>
2 doc1 1 1 C'est tout ? 2 est être AUX <NA>
3 doc1 1 1 C'est tout ? 3 tout tout ADJ <NA>
4 doc1 1 1 C'est tout ? 4 ? ? PUNCT <NA>
5 doc2 1 1 Ah ! 1 A à ADP <NA>
6 doc2 1 1 Ah ! 2 h h NOUN <NA>
7 doc2 1 1 Ah ! 3 ! ! PUNCT <NA>
8 doc2 1 2 non ! 1 non non ADV <NA>
9 doc2 1 2 non ! 2 ! ! PUNCT <NA>
10 doc2 1 3 c'est un pe… 1 c' ce PRON <NA>
# ℹ 610 more rows
# ℹ 5 more variables: feats <chr>, head_token_id <chr>, dep_rel <chr>,
# deps <chr>, misc <chr>Nous allons analyser les différences entre ces résultats et ceux du modèle standard dans une section suivante.
14. ACP + UMAP
Dans cette section, nous explorons deux méthodes très répandues de réduction de dimensionnalité, la ACP (analyse en composantes principales) et UMAP, qui permettent de représenter des données complexes dans un espace de faible dimension tout en conservant autant que possible leur structure.
Le contexte ici est l’analyse de représentations vectorielles de mots obtenues par un modèle de type fastText, qui génère pour chaque mot un vecteur de grande dimension reflétant ses similarités sémantiques dans de vastes corpus textuels [11]. Réduire ces vecteurs à deux dimensions permet de visualiser les relations entre mots d’un simple coup d’œil. fasttext. Nous allons voir d’autres applications de ces méthodes dans les sections suivantes.
fl <- read_csv2("donnees/fruitlegumes.csv")
fl# A tibble: 119 × 2
nom type
<chr> <chr>
1 abricot fruit
2 açaï fruit
3 agrumes fruit
4 amande fruit
5 ananas fruit
6 argousier fruit
7 avocat fruit
8 banane fruit
9 bergamote fruit
10 bigarreau fruit
# ℹ 109 more rowsLe premier bloc charge un tableau contenant une liste de fruits et légumes ainsi qu’une indication de leur catégorie. Ce tableau servira de référence pour associer chaque mot (par exemple « pomme », « carotte ») à sa classe (« fruit » ou « légume »), ce qui facilitera la visualisation et l’interprétation des résultats produits par les méthodes de réduction de dimensionnalité.
Nous chargeons ensuite une matrice de vecteurs d’embedding, c’est-à-dire une représentation numérique du sens des mots. Chaque mot correspond à une ligne de la matrice et chaque colonne à une dimension latente. En faisant correspondre les noms du tableau de fruits/légumes aux lignes de cette matrice, nous extrayons les vecteurs utiles pour notre analyse.
embed <- read_rds("donnees/fasttext_embed.rds")
idx <- match(fl$nom, rownames(embed))
X <- embed[idx, ]
dim(X)[1] 119 300Le bloc suivant applique la ACP aux vecteurs. Cette méthode linéaire vise à projeter les données dans un espace de plus faible dimension en conservant la direction de variance maximale.
apc <- prcomp(X, center = TRUE, scale. = TRUE)
fl$apc1 <- apc$x[, 1]
fl$apc2 <- apc$x[, 2]
fl# A tibble: 119 × 4
nom type apc1 apc2
<chr> <chr> <dbl> <dbl>
1 abricot fruit 7.13 -4.45
2 açaï fruit 3.51 8.55
3 agrumes fruit 3.90 -0.761
4 amande fruit 3.89 -5.05
5 ananas fruit 2.72 -0.415
6 argousier fruit 2.94 3.95
7 avocat fruit -0.166 -1.45
8 banane fruit 4.12 -3.87
9 bergamote fruit 6.16 -1.93
10 bigarreau fruit 3.78 0.289
# ℹ 109 more rowsNous retenons ici les deux premières composantes principales et les ajoutons au tableau initial afin de pouvoir les utiliser directement pour l’affichage. Cela permet de visualiser, de manière simplifiée, comment les représentations des mots se distribuent dans l’espace.
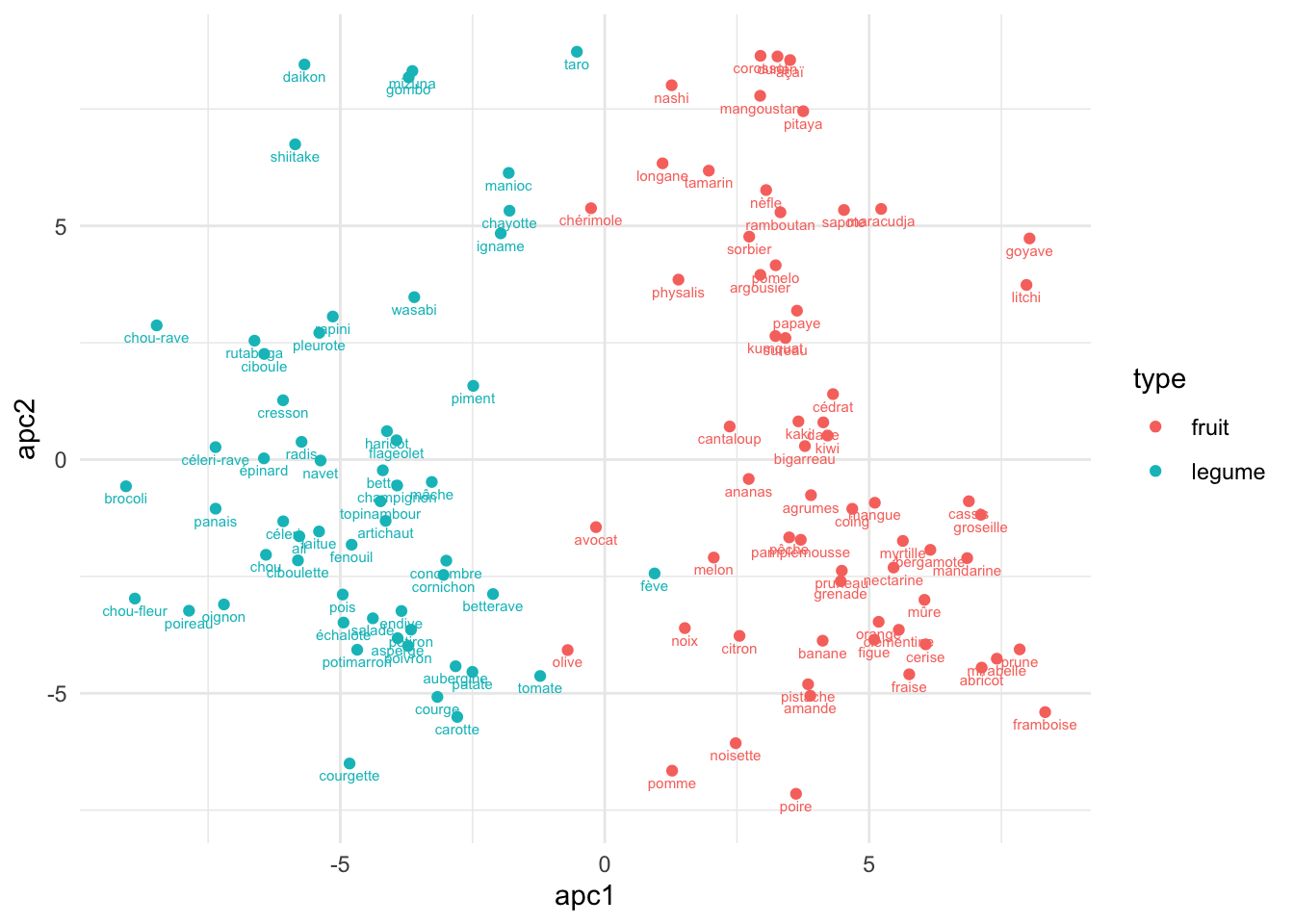
Une fois les deux composantes extraites, nous les représentons graphiquement. Chaque point correspond à un fruit ou un légume, la couleur désigne la catégorie, et les étiquettes textuelles facilitent l’identification individuelle. Cette visualisation met généralement en évidence des regroupements naturels : par exemple, les fruits tendent à se rassembler dans une zone du plan, les légumes dans une autre, ce qui illustre la capacité des embeddings à capturer des dimensions sémantiques pertinentes.
fl |>
ggplot() +
geom_point(aes(x=apc1, y=apc2, colour = type)) +
geom_text(
aes(x=apc1, y=apc2, label = nom, colour = type),
size = 2,
nudge_y = -0.25
)
Le bloc suivant applique UMAP, une méthode non linéaire beaucoup plus flexible que la ACP. UMAP cherche à préserver la structure locale des données et est particulièrement efficace pour faire apparaître des groupes compacts ainsi que des relations sémantiques fines. Nous utilisons le package umap et la fonction umap [12].
library(umap)
obj <- umap(X)
fl$umap1 <- obj$layout[, 1]
fl$umap2 <- obj$layout[, 2]Les coordonnées résultantes sont ajoutées au tableau principal afin de pouvoir les visualiser de la même manière que les composantes APC.
fl |>
ggplot() +
geom_point(aes(x=umap1, y=umap2, colour = type)) +
geom_text(
aes(x=umap1, y=umap2, label = nom, colour = type),
size = 2,
nudge_y = -0.1
)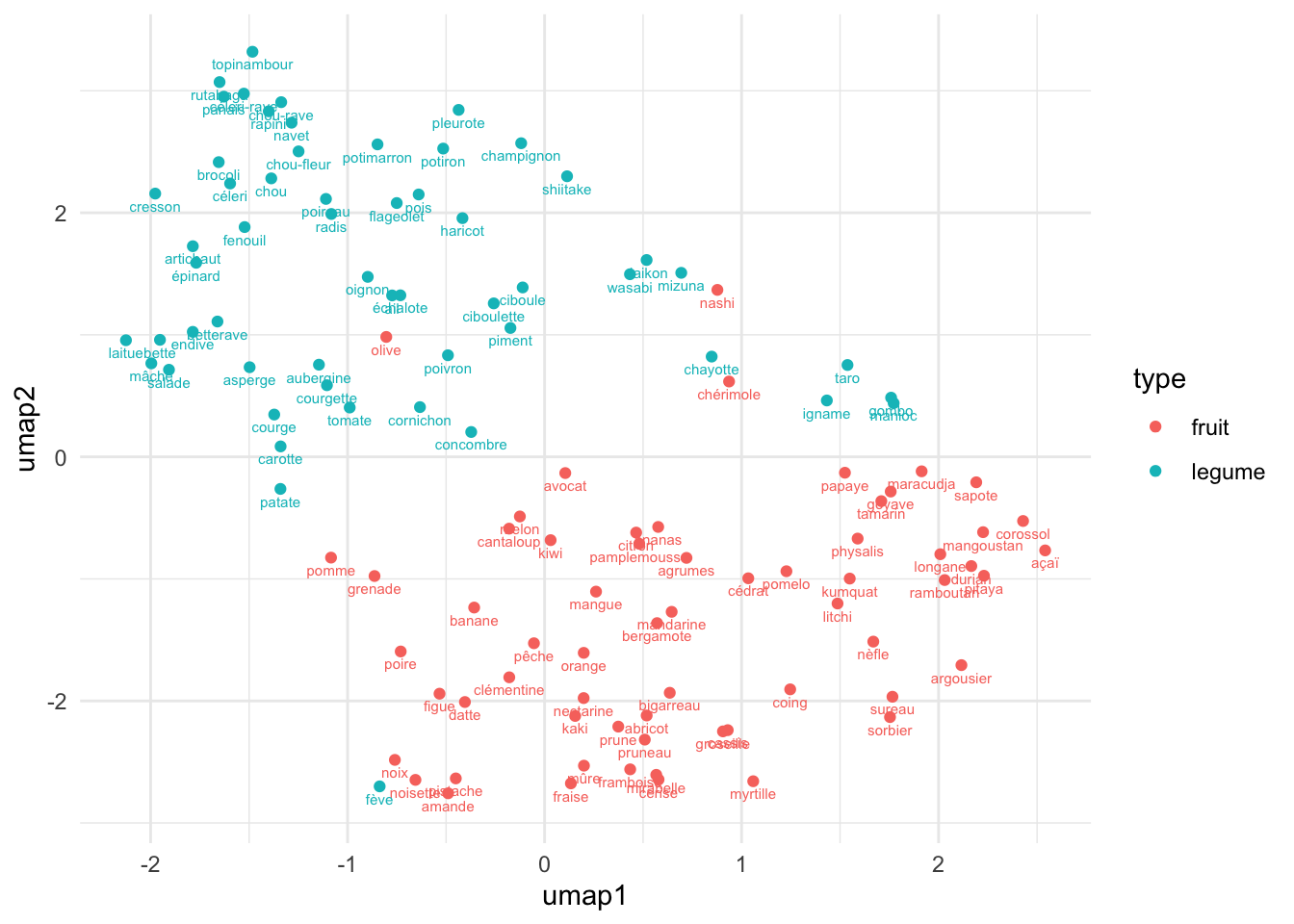
La dernière visualisation montre le résultat d’UMAP dans un plan à deux dimensions. Ce type de projection peut révéler des structures que la APC ne met pas en évidence, comme des sous-groupes plus subtils ou des distances sémantiques plus cohérentes à petite échelle. La combinaison des couleurs et des étiquettes rend la lecture intuitive et facilite la comparaison des deux approches de réduction de dimensionnalité.
15. Modèles prédictifs
Dans cette section, nous abordons la construction d’un modèle prédictif à partir des données textuelles issues des mots tapés par les utilisateurs. L’objectif est d’illustrer comment transformer des données brutes en un ensemble de caractéristiques exploitables par un algorithme d’apprentissage supervisé. Nous utilison les données des critique du film du site Allociné.fr. Nous l’utilisons pour une analyse de sentiment.
Nous commençons par importer les données d’analyse linguistique. Ce fichier contient les mots tokenisés et lemmatisés de chaque document.
parse <- read_csv2("donnees/polarity_parse.csv.bz2")
parse# A tibble: 17,431,814 × 5
doc_id sid token lemma pos
<dbl> <dbl> <chr> <chr> <chr>
1 0 0 Si si SCONJ
2 0 0 vous vous PRON
3 0 0 cherchez chercher VERB
4 0 0 du de ADP
5 0 0 cinéma cinéma NOUN
6 0 0 abrutissant abrutissant ADV
7 0 0 à à ADP
8 0 0 tous tout ADJ
9 0 0 les le DET
10 0 0 étages étage NOUN
# ℹ 17,431,804 more rowsNous chargeons ensuite les métadonnées qui contiennent notamment la variable cible (polarity) que nous cherchons à prédire.
meta <- read_csv2("donnees/polarity_meta.csv.bz2")
meta# A tibble: 160,000 × 2
doc_id polarity
<dbl> <dbl>
1 0 0
2 1 0
3 2 0
4 3 0
5 4 1
6 5 0
7 6 1
8 7 1
9 8 1
10 9 0
# ℹ 159,990 more rowsCette étape transforme le texte en matrice sparse avec to_sparse. Nous normalisons les lemmes en minuscules avec stri_trans_tolower, puis filtrons pour ne garder que les mots apparaissant plus de 200 fois. Chaque ligne représente un document et chaque colonne un lemme.
X <- parse |>
mutate(lemma = stri_trans_tolower(lemma)) |>
group_by(lemma) |>
filter(n() > 200) |>
to_sparse(doc_id, lemma)
dim(X)[1] 159961 4639Nous créons un tibble qui associe chaque identifiant de document aux métadonnées correspondantes avec left_join, assurant ainsi la correspondance entre X et les étiquettes.
df_meta <- tibble(doc_id = as.numeric(rownames(X))) |>
left_join(meta, by = "doc_id")
df_meta# A tibble: 159,961 × 2
doc_id polarity
<dbl> <dbl>
1 0 0
2 1 0
3 2 0
4 3 0
5 4 1
6 5 0
7 6 1
8 7 1
9 8 1
10 9 0
# ℹ 159,951 more rowsNous séparons aléatoirement les données en un ensemble d’apprentissage (10 000 observations) et un ensemble de validation. Cette division permet d’évaluer la performance du modèle sur des données non vues.
ind_train <- sort(sample(seq_len(nrow(X)), 10000))
ind_valid <- setdiff(seq_len(nrow(X)), ind_train)Nous entraînons une régression logistique régularisée avec cv.glmnet du package glmnet [13]. L’option family="binomial" spécifie un problème de classification binaire et effectue automatiquement une validation croisée pour sélectionner le paramètre de régularisation optimal.
library(glmnet)
model <- cv.glmnet(
X[ind_train,], df_meta$polarity[ind_train], family="binomial"
)Nous générons des prédictions sur l’ensemble de validation avec predict et calculons le taux de précision global en comparant les prédictions aux vraies valeurs.
pred <- predict(model, newx=X[ind_valid,], type = "class")
mean(pred == df_meta$polarity[ind_valid])[1] 0.8867772La fonction table crée une matrice de confusion qui détaille les vrais positifs, vrais négatifs, faux positifs et faux négatifs, offrant une vue plus complète de la performance du modèle.
table(pred=pred, y=df_meta$polarity[ind_valid]) y
pred 0 1
0 66131 8656
1 8323 66851Nous extrayons les coefficients non nuls du modèle avec coef() pour identifier les lemmes les plus influents. Les coefficients positifs indiquent une association avec une classe, les négatifs avec l’autre.
cf <- coef(model, s = model$lambda[5])
cf <- cf[cf[,1] != 0,,drop=FALSE][-1,,drop=FALSE]
cf[order(cf[,1]),,drop=FALSE]9 x 1 sparse Matrix of class "dgCMatrix"
s=0.07176278
intérêt -0.116654918
rien -0.096866697
pas -0.036332424
mal -0.017120113
mauvais -0.007037554
ridicule -0.004267539
très 0.000301326
magnifique 0.224069435
excellent 0.374677833Nous voyons plusieurs mots associés à chaque polarité.
16. LLM
Les grands modèles de langage (abrégé LLM, de l’anglais large language model) donnent aux agents conversationnels la capacité de comprendre et de répondre à des entrées en texte libre. Les LLM ne peuvent pas être exécutés directement dans R, mais il est possible d’y accéder au moyen d’une API. Une API permet d’utiliser un LLM à partir de divers logiciels, que ce soit localement ou via un service externe payant. Deux logiciels courants pour utiliser les LLM localement sont ollama et LM Studio.
Voici un exemple d’utilisation d’un LLM avec la fonction oai_chat, LM Studio et un modèle source ouvert de OpenAI. Nous pourrions utiliser un autre service en modifiant le paramètre base_url ou un autre modèle en modifiant le paramètre model.
msg <- "Combien de personnes vivent dans le 11e arrondissement de Paris ?"
res <- oai_chat(
base_url = "http://localhost:1234",
model = "openai/gpt-oss-20b",
msg = msg,
temperature = 0.7,
)
resEnviron **110 000 personnes** habitent le 11ᵉ arrondissement de Paris (données du recensement officiel d’INSEE, année 2019). Le chiffre exact varie légèrement selon les mises à jour annuelles (par exemple, l’estimation 2021 se situe autour de 112 k habitants), mais on peut dire qu’il y a un peu plus d’un centième de million de résidents dans ce quartier.Les LLM ouvrent de nombreuses possibilités pour étendre l’analyse des données textuelles. Par exemple, au lieu d’entraîner un modèle supervisé à partir d’annotations humaines, nous pouvons utiliser un LLM pour générer des annotations à grande échelle. Essayons maintenant avec un sous-ensemble de nos données de critiques de films.
Vous trouverez ci-dessous le code qui demande à un modèle LLM d’évaluer la polarité, la certitude et la conviction d’un critiques. Le résultat est renvoyé au format JSON, couramment utilisé pour transmettre des données via une API.
msg <- c(
'Évaluer le degré de conviction, le degré de certitude et le caractère',
'positif de ce texte sur une échelle de 1 (peu convaincant/certain/positif)',
'à 10 (très convaincant/certain/positif). Indiquez votre évaluation dans une',
'forme pur JSON. Par exemple :',
'{"conviction": 4, "certain": 8, "positif": 2}.\n\n'
)
res <- oai_chat(
base_url = "http://localhost:1234/v1/chat/completions",
model = "openai/gpt-oss-20b",
msg = paste(msg, document, collapse=" "),
temperature = 0.7,
)
res{"conviction": 7, "certain": 8, "positif": 5}Les données au format JSON peuvent être facilement analysées dans R à l’aide de la fonction fromJSON du package jsonlite [14].
library(jsonlite)
as_tibble(fromJSON(res))# A tibble: 1 × 3
conviction certain positif
<int> <int> <int>
1 7 8 5Nous importons les résultats d’annotation produits par le LLM pour l’ensemble des documents. Ces annotations serviront de nouvelles étiquettes pour entraîner un modèle.
llm <- read_csv2("donnees/polarity_llm.csv.bz2")
llm# A tibble: 953 × 7
doc_id input polarity raw conviction certain positif
<dbl> <chr> <dbl> <chr> <dbl> <dbl> <dbl>
1 39 "Petit film amateur réalisé… 0 "{\"… 6 7 5
2 132 "Une comédie romantique bie… 1 "{\"… 7 8 9
3 618 "Le sujet est d'une sensibi… 1 "{\"… 9 9 10
4 720 "Structure narrative classi… 0 "{\"… 8 7 2
5 859 "Un film énigmatique dans s… 1 "{\"… 5 4 7
6 989 "Fortunata n'a pas la vie f… 0 "{\"… 6 8 2
7 1781 "j'ai vu les deux films et … 1 "{\"… 8 7 9
8 1817 "Très déçue. Comme trop sou… 0 "{\"… 8 7 2
9 1852 "Antonio Banderas s'investi… 0 "{\"… 9 9 1
10 1982 "Mais qu est ce que c est n… 0 "{\"… 6 8 2
# ℹ 943 more rowsLa fonction table crée un tableau croisé comparant la polarité originale avec le score de positivité généré par le LLM, permettant d’évaluer la cohérence entre les deux mesures.
table(llm$polarity, llm$positif)
1 2 3 4 5 6 7 8 9 10
0 129 256 57 15 16 9 9 2 2 1
1 2 10 9 7 11 17 32 86 216 67Nous entraînons un nouveau modèle glmnet en utilisant les annotations de polarité générées par le LLM comme variable cible. La matrice X est d’abord filtrée pour ne garder que les documents annotés.
X_nouv <- X[as.character(llm$doc_id),]
model <- cv.glmnet(X_nouv, llm$positif)Nous extrayons et trions les coefficients non nuls pour identifier quels lemmes sont les plus associés aux jugements de polarité du LLM, révélant potentiellement des patterns différents de ceux du modèle précédent.
cf <- coef(model, s = model$lambda[12])
cf <- cf[cf[,1] != 0,,drop=FALSE][-1,,drop=FALSE]
cf[order(cf[,1]),,drop=FALSE]9 x 1 sparse Matrix of class "dgCMatrix"
s=0.5341057
mal -0.30335297
mauvais -0.19382625
ne -0.18204717
pire -0.04267963
ridicule -0.02476939
très 0.04357302
magnifique 0.14690575
bel 0.20887087
excellent 1.05102845Cette section démontre une stratégie hybride où un LLM sert d’annotateur automatique pour créer des données d’entraînement. En comparant les coefficients du modèle entraîné sur les annotations LLM avec ceux du modèle basé sur les annotations originales, nous pouvons identifier les différences dans les patterns linguistiques capturés par chaque approche. Cette méthode est particulièrement utile lorsque l’annotation humaine est coûteuse ou lorsque nous souhaitons explorer rapidement différentes dimensions d’analyse textuelle. Cependant, il est important de valider la qualité des annotations LLM et de comprendre que le modèle résultant reflète les biais et les capacités du LLM utilisé pour l’annotation.
17. Whisper
Whisper est un modèle de reconnaissance vocale développé par OpenAI capable de transcrire automatiquement de l’audio en texte avec un haut niveau de précision. Cette section montre comment utiliser l’API Whisper pour transcrire un fichier audio en français et obtenir non seulement le texte complet, mais aussi le temps précis de chaque mot. Cette capacité de segmentation temporelle est particulièrement utile pour l’analyse linguistique, l’alignement texte-audio, ou la création de sous-titres automatiques.
Nous envoyons un fichier audio MP3 à l’API Whisper avec la fonction oai_transcriptions. Les paramètres spécifient le modèle à utiliser (“whisper-1”) et la langue source (“fr”), et la granularité de temps (segments et mots individuels).
Sys.setenv(OPENAI_API_KEY = "AJOUTEZ_ICI")
trans <- oai_transcriptions(
file = "donnees/rhapsodie/mp3/Rhap-D0001.mp3",
model_name = "whisper-1",
language = "fr"
)
whisper_mots <- as_tibble(trans$words)
whisper_mots# A tibble: 905 × 3
word start end
<chr> <dbl> <dbl>
1 C 0 0.32
2 est 0.32 0.32
3 pas 0.32 1.52
4 mal 1.52 1.74
5 disons 1.74 2.2
6 est 2.4 2.46
7 ce 2.46 2.46
8 que 2.46 2.48
9 vous 2.48 2.66
10 pourriez 2.66 3.34
# ℹ 895 more rowsL’accès programmatique à l’API Whisper via R facilite l’intégration de la reconnaissance vocale dans des chaînes de traitement d’analyse de données plus larges, ouvrant la voie à l’étude systématique de grandes quantités de données audio.
18. Plongement de textes
Les plongements de textes (text embeddings) sont des représentations vectorielles denses qui capturent le sens sémantique des documents dans un espace de dimension réduite. Contrairement aux représentations sac-de-mots qui créent des vecteurs creux de haute dimension, les embeddings produits par des modèles comme OpenAI’s plongement de textes génèrent des vecteurs denses de quelques milliers de dimensions où des textes similaires en sens sont proches dans l’espace vectoriel. Cette section montre comment obtenir des embeddings via l’API OpenAI, les utiliser pour entraîner un modèle prédictif, et visualiser la structure sémantique des documents en deux dimensions avec UMAP.
Pour accéder aux plongements basées sur LLM, nous utilisons encore une API, cette fois avec la fonction oai_embeddings. Dans cet exemple, nous utiliserons un modèle propriétaire d’OpenAI, mais il est également possible de modifier l’URL pour utiliser un modèle local.
Sys.setenv(OPENAI_API_KEY = "AJOUTEZ_ICI")
res <- oai_embeddings(
input = "Que sais-je?",
model = "text-embedding-3-large"
)
dim(res)[1] 3072Nous voyons que ce plongement de texte a une dimension de 3072. Notez que la dimension ne change pas en fonction de la taille du texte.
Nous chargeons un ensemble de données précalculées d’intégrations provenant d’un échantillon de critiques de films.
X <- read_rds("donnees/polarity_embed.rds")
dim(X)[1] 953 3072Nous créons un ensemble d’entraînement réduit (700 observations) et un ensemble de validation avec sample. Les embeddings étant des représentations riches, même un petit ensemble d’entraînement peut produire de bons résultats.
ind_train <- sort(sample(seq_len(nrow(X)), 700))
ind_valid <- setdiff(seq_len(nrow(X)), ind_train)Nous entraînons une régression logistique avec régularisation ridge (alpha=0) via cv.glmnet. La régularisation L2 est particulièrement adaptée aux embeddings car elle pénalise uniformément toutes les dimensions sans en éliminer complètement.
model <- cv.glmnet(
X[ind_train,], llm$polarity[ind_train], family="binomial", alpha=0
)Nous générons des prédictions sur l’ensemble de validation avec predict et calculons la précision globale. Les embeddings capturant la sémantique profonde, la performance peut être élevée même avec peu de données d’entraînement.
pred <- predict(model, newx=X[ind_valid,], type = "class")
mean(pred == llm$polarity[ind_valid])[1] 0.9644269La fonction table produit une matrice de confusion détaillant la répartition des prédictions correctes et incorrectes, permettant d’identifier d’éventuels biais du modèle.
table(pred=pred, y=llm$polarity[ind_valid]) y
pred 0 1
0 135 2
1 7 109Nous appliquons UMAP avec umap pour projeter les embeddings de haute dimension en deux dimensions visualisables. Cette technique de réduction dimensionnelle préserve la structure locale et révèle les regroupements sémantiques dans les données.
obj <- umap(X)
llm$umap1 <- obj$layout[, 1]
llm$umap2 <- obj$layout[, 2]Nous créons un graphique de dispersion avec ggplot() montrant la projection UMAP colorée par le score de positivité. Cette visualisation révèle si les documents de positivité similaire forment des clusters distincts dans l’espace sémantique.
llm |>
mutate(positif = factor(positif)) |>
ggplot() +
geom_point(aes(x=umap1, y=umap2, colour = positif), size=6, alpha=0.4) +
scale_colour_viridis_d()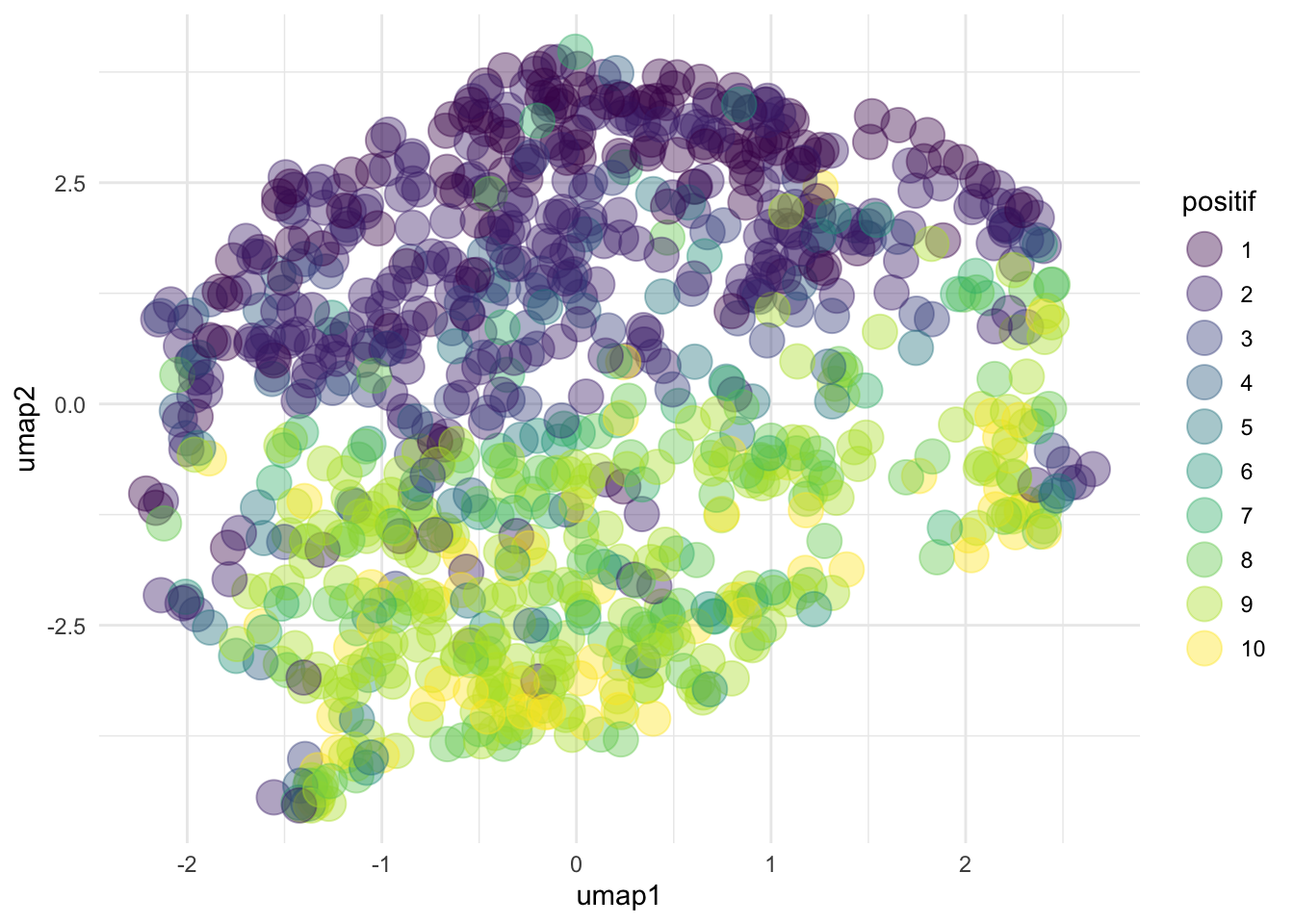
Cette section illustre la puissance des embeddings de textes pour l’analyse et la classification. Comparés aux représentations sac-de-mots, les embeddings capturent des relations sémantiques complexes et permettent d’obtenir de bonnes performances avec moins de données d’entraînement. La visualisation UMAP révèle la structure sémantique sous-jacente des documents, montrant comment le modèle d’embedding organise les textes selon leur sens. Cette approche est particulièrement efficace pour des tâches nécessitant une compréhension nuancée du contenu textuel, et peut facilement être intégrée dans des chaînes de traitement d’apprentissage automatique plus complexes.
19. Alignement des textes
Lorsque nous analysons le même texte avec différents modèles ou outils d’annotation linguistique, il est essentiel de pouvoir comparer systématiquement leurs sorties. Cette section présente l’alignement de deux annotations du même texte produites par des modèles différents. En alignant les tokens correspondants, nous pouvons identifier les divergences dans les analyses (étiquettes morphosyntaxiques, lemmes, relations de dépendance) et évaluer la cohérence ou les différences entre les modèles. Cette approche est cruciale pour la validation de modèles, l’amélioration de chaînes de traitement d’analyse, ou la compréhension des forces et faiblesses de différents systèmes d’annotation.
Nous utilisons la fonction alignement_des_textes() pour apparier les tokens des deux annotations en se basant sur la colonne token. Le paramètre suffix_y = “_nouv” ajoute un suffixe aux colonnes de la seconde annotation pour les distinguer, créant ainsi un tibble combiné où chaque ligne contient les informations des deux modèles pour le même token.
df_comb <- alignement_des_textes(
df_tirade,
df_tirade_nouv,
col1 = token,
col2 = token,
suffix_y = "_nouv"
)
df_comb# A tibble: 613 × 30
id id_y doc_id paragraph_id sentence_id sentence token_id token lemma
<dbl> <dbl> <chr> <int> <int> <chr> <chr> <chr> <chr>
1 1 1 doc1 1 1 C'est tout ? 1 C' ce
2 2 2 doc1 1 1 C'est tout ? 2 est être
3 3 3 doc1 1 1 C'est tout ? 3 tout tout
4 4 4 doc1 1 1 C'est tout ? 4 ? ?
5 6 7 doc2 1 1 Ah ! non ! 2 ! !
6 7 8 doc2 1 1 Ah ! non ! 3 non non
7 8 9 doc2 1 1 Ah ! non ! 4 ! !
8 9 10 doc2 1 2 c'est un pe… 1 c' ce
9 10 11 doc2 1 2 c'est un pe… 2 est être
10 11 12 doc2 1 2 c'est un pe… 3 un un
# ℹ 603 more rows
# ℹ 21 more variables: upos <chr>, xpos <chr>, feats <chr>,
# head_token_id <chr>, dep_rel <chr>, deps <chr>, misc <chr>,
# doc_id_nouv <chr>, paragraph_id_nouv <int>, sentence_id_nouv <int>,
# sentence_nouv <chr>, token_id_nouv <chr>, token_nouv <chr>,
# lemma_nouv <chr>, upos_nouv <chr>, xpos_nouv <chr>, feats_nouv <chr>,
# head_token_id_nouv <chr>, dep_rel_nouv <chr>, deps_nouv <chr>, …Nous filtrons les lignes où les étiquettes morphosyntaxiques diffèrent entre les deux modèles avec filter(upos != upos_nouv). La fonction select() permet de visualiser côte à côte les tokens, lemmes et étiquettes des deux annotations, révélant précisément où et comment les modèles divergent dans leur analyse.
df_comb |>
filter(upos != upos_nouv) |>
select(token, lemma, token_nouv, lemma_nouv, upos, upos_nouv)# A tibble: 63 × 6
token lemma token_nouv lemma_nouv upos upos_nouv
<chr> <chr> <chr> <chr> <chr> <chr>
1 Dieu Dieu Dieu Dieu PROPN ADV
2 bien bien bien bien ADV NOUN
3 boire boire boire boire NOUN VERB
4 Curieux curieux Curieux curieux ADJ ADV
5 oblongue oblongue oblongue oblongue ADJ NOUN
6 capsule capsule capsule capsule NOUN ADJ
7 Truculent Truculent Truculent Truculer ADJ VERB
8 Çà Çà Çà çà PROPN NOUN
9 sort sortir sort sort VERB PROPN
10 Prévenant prévenant Prévenant Prévenant PROPN ADV
# ℹ 53 more rowsCette section démontre l’importance de l’alignement pour la comparaison systématique d’annotations linguistiques. En appariant les sorties de différents modèles, nous pouvons quantifier leur accord, identifier les cas problématiques, et mieux comprendre les choix d’annotation de chaque système. Cette approche est particulièrement utile pour l’évaluation de nouveaux modèles, le diagnostic d’erreurs, ou le choix du meilleur outil pour une tâche spécifique. L’alignement constitue ainsi une étape fondamentale dans tout workflow d’analyse textuelle rigoureux impliquant plusieurs sources d’annotation.
20. Conclusions
Ce parcours à travers diverses techniques de traitement et d’analyse des données textuelles et temporelles a montré la richesse des outils disponibles en R pour explorer des corpus linguistiques, qu’ils proviennent de frappes clavier, d’annotations phonétiques, de textes littéraires ou de grands ensembles issus du web. En partant de transformations simples de tableaux et de statistiques descriptives, nous avons progressivement étendu la palette d’analyses vers des modèles plus sophistiqués : fonctions de fenêtre pour décrire des dynamiques, expressions régulières pour extraire de l’information fine au sein des mots, annotation grammaticale automatique pour comprendre la structure des phrases, réduction de dimensionnalité pour visualiser des représentations sémantiques, et enfin modèles prédictifs pour relier des caractéristiques textuelles à des propriétés externes.
L’ensemble de ces approches montre comment des données très hétérogènes — temps d’appui sur les touches, phonèmes, traits morphologiques, vecteurs d’embedding ou encore fréquences lexicales — peuvent être articulées pour éclairer des questions linguistiques ou comportementales. Les exemples présentés ne constituent qu’un point de départ : ils ouvrent la voie à des analyses plus fines, des comparaisons plus larges et des modèles plus ambitieux. L’essentiel est de comprendre que chaque étape, du prétraitement aux modèles prédictifs, contribue à transformer des données brutes en connaissances interprétables. Ces techniques offrent ainsi un ensemble puissant et flexible pour explorer empiriquement la langue et les usages qu’en font les locuteurs.
Les références
1.
Wickham H, Çetinkaya-Rundel M, Grolemund G. R for data science: import, tidy, transform, visualize, and model data. " O’Reilly Media, Inc.". 2023.
2.
Wickham H, François R, Henry L, Müller K, Vaughan D. dplyr: A Grammar of Data Manipulation. 2023. Disponible sur: https://CRAN.R-project.org/package=dplyr.
3.
Styler W. Using Praat for linguistic research. University of Colorado at Boulder Phonetics Lab. 2013.
4.
Lacheret A, Kahane S, Beliao J, Dister A, Gerdes K, Goldman JP, et al. Rhapsodie: a prosodic-syntactic treebank for spoken french. In: Language Resources and Evaluation Conference. 2014.
5.
Mahr T, Fruehwald J. readtextgrid: Read in a ’Praat’ ’TextGrid’ File. 2025. Disponible sur: https://CRAN.R-project.org/package=readtextgrid.
6.
Ligges U, Krey S, Mersmann O, Schnackenberg S. tuneR: Analysis of Music and Speech. 2023. Disponible sur: https://CRAN.R-project.org/package=tuneR.
7.
Barreda S. phonTools: Functions for phonetics in R. 2023.
8.
Wijffels J. udpipe: Tokenization, Parts of Speech Tagging, Lemmatization and Dependency Parsing with the ’UDPipe’ ’NLP’ Toolkit. 2025. Disponible sur: https://CRAN.R-project.org/package=udpipe.
9.
Guillaume B, Marneffe MC de, Perrier G. Conversion et améliorations de corpus du français annotés en Universal Dependencies. Traitement automatique des langues. 2019.60(2):71‑95.
10.
Rostand E. Cyrano de Bergerac: Comédie héroïque en cinq actes en vers. éd. revue et commentée. Aziza C, éditeur. Paris: Gallimard. 2006. (Folio Théâtre).
11.
Athiwaratkun B, Wilson A, Anandkumar A. Probabilistic fasttext for multi-sense word embeddings. In: Proceedings of the 56th annual meeting of the association for computational linguistics (volume 1: Long papers). 2018. p. 1‑11.
12.
Konopka T. umap: Uniform Manifold Approximation and Projection. 2023. Disponible sur: https://CRAN.R-project.org/package=umap.
13.
Friedman J, Hastie T, Tibshirani R. Regularization Paths for Generalized Linear Models via Coordinate Descent. Journal of Statistical Software. 2010.33(1):1‑22.
14.
Ooms J. The jsonlite Package: A Practical and Consistent Mapping Between JSON Data and R Objects. arXiv:14032805 [statCO]. 2014. Disponible sur: https://arxiv.org/abs/1403.2805.